こんにちは。中山(id:yoichi22) です
Software Designに連載させていただいております「Pythonモダン化計画」では、モノタロウの社内事例から読者の皆様のお役に立ちそうな取り組みを紹介させていただいています。のですが、社内でも隣のチームがやってた取り組みを記事で初めて知ることもあって、私も読者として楽しませてもらっています。隣の執筆者さんありがとうございます。

今回は、運用にまつわる監視とログの話題です。本記事の初出は、Software Design2022年1月号「Pythonモダン化計画(第6回)」になります。過去の連載記事は以下を参照ください。
- 第1回 Software Design連載 2021年8月号 Python製のレガシー&大規模システムをどうリファクタリングするか
- 第2回 Software Design連載 2021年9月号 「テストが無い」からの脱却
- 第3回 Software Design連載 2021年10月号 スナップショットテストの可能性を追求する
- 第4回 Software Design連載 2021年11月号 Robot FrameworkでE2Eテストを自動化する
- 第5回 Software Design連載 2021年12月号 リリース作業とエラー追跡の改善
インフラ監視から、サービス観点での監視へ
モノタロウのサービスはオンプレミスとクラウドの混在したインフラの上に構築されており、アプリケーションの多くはPythonで書かれています。システムを安定して運用するためには、これらのインフラやアプリケーション全体の稼働状況を監視し、リソース不足や障害の発生に素早く対応していく必要があります。トラブルが発生したときには、システムのどこで何が起きているのかを各種のログを解析して的確に把握する必要もあります。
数年前までは、アプリケーションの挙動を含め、インフラ全体の稼働状況が十分に管理できているとはいえない状況でした。リソース逼迫によるトラブルが発生してはじめて、普段のインフラの状況を把握できていないアプリケーション担当者が調査に着手するといった、後手に回る対応もしばしば発生していました。
システムの各所で生成されるログも、以前は原始的な使い方しかできていませんでした。具体的には、トラブル発生やユーザからの問い合わせに応じて調査が必要になると、そのつどサーバーにSSHでログインしてgrepしていました。しかし、サービスの拡大につれてWebサーバだけでも100以上になると、特定のログを求めて複数のホストから情報を探すのが困難になってきます。「定期的にログを収集してほぼ1日遅れでDBにログを集約する」といった仕組みはありましたが、データ量の増加に伴ってDBからログを検索する時間は延びる一方でした。
システムの稼働状況の把握やログの運用がおぼつかない状況は、「自動スケールを導入したい」といったシステムのモダン化にとっても障壁です。そこでモノタロウでは、まずインフラ全般を見るチームを中心に、こうした状況の改善を進めました。現在では、NagiosやCactiといったツールによりリソース監視や死活監視を実施しています。ただし本記事では、こうしたインフラの監視ではなく、その先のお話をします。具体的には、運用中のシステムから得られる情報をインフラだけでなくサービスの観点からも可視化するため、アプリケーションを扱うチームが主導できるDatadogを導入しました。ログに関しても、FluentdとBigQueryを活用したログ基盤を整備し、簡便かつ高速に情報を検索できるようにしています。
今回は、モノタロウのシステムにおいてDatadogにより運用監視の解像度を上げた事例と、横断的で高速なログ検索のための基盤をどのように実現しているかを紹介します。
Datadogで運用監視の解像度を向上
モノタロウのシステムは、大きく分けてインフラチームとアプリケーションチームによる連携で運用されています。インフラチームは、サーバインスタンスの構築からミドルウェアの導入までを行います。その上で動作するアプリケーションやバッチ処理の開発、運用をするのがアプリケーションチームです。
システムの監視は、「メモリやディスクなどのサーバリソースが枯渇していないか」「ミドルウェアが正常に動作しているか」といった観点で、主にインフラチームによって実施されてきました。しかし、私達が本当に実現しなければならないのは、お客様にサービスを安定してご利用いただくことです。そのためには、インフラだけでなく、アプリケーションも含めたシステム全体を監視できる環境が必要です。
そこで、アプリケーションチームの手で追加の監視を組み込み、サービス提供者の視点で運用監視の解像度を上げるための仕組みとしてDatadogを導入しました。DatadogにはPython向けの自由度の高いSDKが提供されており、Pythonを開発の中心に据えている私達に合っていました。
Datadogは、監視対象のホストで「エージェント」と呼ばれるサービスを動かしておき、それらエージェントから送られる情報を可視化するプラットフォームです。エージェントは、CPU使用率や、ApacheやNginxから得られる統計情報といったホストの情報を集めるだけでなく、アプリのトレース情報や、独自のメトリックやイベントも送信できます。それらのデータは、どの系統か(本番なのかステージングなのか)、どのサービスか(Webサイトなのか基幹なのか)、どのホストか(DBなのかAPIなのか)といったタグを付与して区別できます。エージェントが収集した様々な情報をタグで分類して見れるようにすることで、サービスの稼働状況を高い解像度で監視できるようになります。
Datadogダッシュボードの活用
Datadogを使うことで、システムのさまざまな層の指標を一覧するダッシュボードが作成できます。これにより、負荷状況の把握や障害が発生している箇所の特定がしやすくなります。
モノタロウのECサイトのシステムの場合には、ユーザからのアクセスを受けるロードバランサ、Webページをサーブするフロントエンド、APIの機能を提供するバックエンド、検索エンジンやデータベースなどの層が連携しています。これらの各層を構成するホスト群ごとに、指標をグルーピングしたグラフを並べることで、以下のようなダッシュボードを作成しています。一番左の列がECサイトの全体の指標で、AWSのロードバランサであるELBのメトリクスなどを並べています。以降の各列には、フロントエンドからバックエンドの順に、各行におおよそ同じ指標のグラフが並ぶ形でダッシュボードを構成しています。
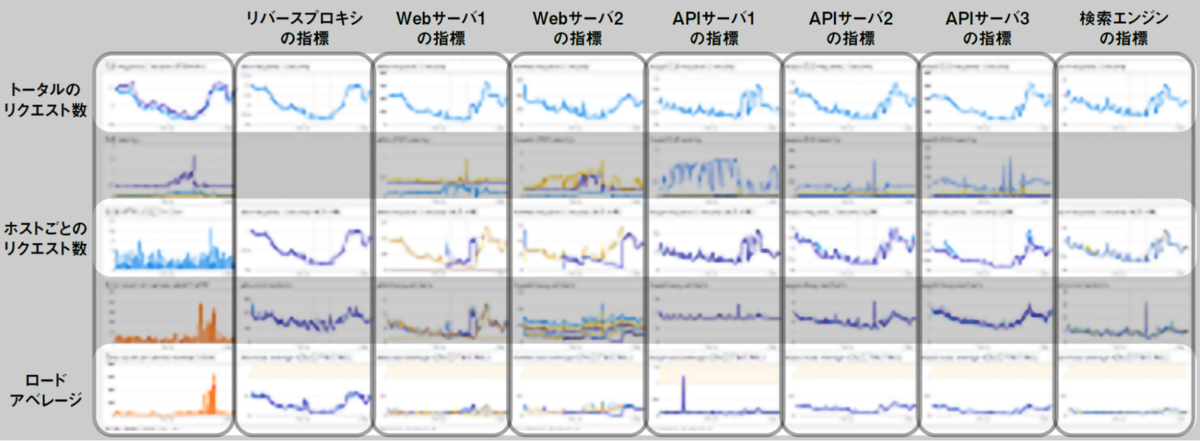
このようなダッシュボードを使うことで、たとえば「フロントエンドでタイムアウトが発生した場合にバックエンドの方向にたどって負荷上昇している箇所を見つける」といったことが容易になります。問題の箇所が見つかったら、スケールアウトによる負荷分散を検討したり、直近のリリースに問題がないかを確認してロールバックを検討するなどの対処が実施できます1。
さらに、DatadogのPython SDKを使って、独自のメトリックやイベントを生成して送信し、API呼び出しのリトライやタイムアウト発生をダッシュボードに出して切り分けに活用するといった工夫もしています。たとえば以下は、DogStatsDという機能を利用して、API呼び出しのリトライ回数が増加したことをDatadogに通知するコードです。
from datadog import statsd
statsd.increment("backend_retry_count",
tags=["datasource_type:api", "datasource:https://example.com/api"])
Datadog APMの活用
ダッシュボードを活用した監視は、リソース不足やアクセス過多など、ある程度の規模におよぶ挙動の把握には役立ちます。一方で、呼び出し回数の少ないエンドポイントや、特定のアクセスパターンでしか発生しない処理の遅延はダッシュボードでは把握できない場合もあります。
そうした状況の切り分けや対処方針の判断材料として活用できる仕組みとして、Datadog APMがあります。APMを導入することで、エンドポイントごとの呼び出し回数、レイテンシ分布の時間経過による推移が可視化されるようになります。
APMを使うには、DatadogのSDKに含まれる「トレーサー」と呼ばれる仕掛けをアプリケーションに組み込みます。Python製アプリケーション向けのトレーサーはrequestsやhttplibといったモジュールにも対応しているので、アプリケーションから他のAPIを呼び出すときの時間なども自動的に計測されます。
ただし、モノタロウでは独自の内製Webフレームワークを使っているので、個別に対応が必要だった部分もあります。具体的には、トレーサーで計測を行いたい区間(スパン)ごとに次のように定義したbegin_span()関数とend_span()関数を呼び出すことで対応しました。
def begin_span(name, resource, url, method):
span = ddtrace.tracer.trace(name, service=_service, span_type=ddtrace.ext.http.TYPE)
span.resource = resource
span.set_tag(ddtrace.ext.http.URL, url)
span.set_tag(ddtrace.ext.http.METHOD, method)
return span
def end_span(span, status_code, success):
span.set_tag(ddtrace.ext.http.STATUS_CODE, status_code)
span.error = 0 if success else 1
span.finish()
また、モノタロウでDBアクセスに使っているmysqlclientについても、Python向けのDatadogのトレーサーであるdd-trace-pyが未対応でした。これについては、dd-trace-pyにおける標準的な方法でMySQL対応のモジュールを書くことで対応しました。このとき作成したモジュールは開発元にフィードバックして取り込んでもらえたので、現在はmysqlclientのトレーサーも標準で利用可能です。
以上の対応を行うことで、APMによりエンドポイントごとの処理時間と処理の内訳(内部のMySQLクエリやAPI呼び出しでそれぞれどれだけ時間がかかっているか)が見られるようになります。

APMの課題
APMの導入には、課題もありました。一つは、性能劣化の心配です。一般に、アプリケーションの処理にトレースのような仕組みを追加すると、実行は遅くなってしまいます。APMの導入にあたっては、処理性能に配慮されていることを実装を読んで確認し、さらに実際に大量のトレースを送信させてみて性能劣化が許容できる範囲であることを確かめました。
もう一つはデータの保安です。モノタロウのシステムの古い実装には、プレースホルダを使わない生のSQLを文字列操作で生成して、DBAPIで実行しているものがあります。 dd-trace-py が組み込まれた状態でこの処理を実行すると、例えば WHERE 句にユーザIDのような個人情報が入った状態の生のSQLが意図せずDatadogに送られてしまう問題がありました。この問題を防ぐために、次のようにトレースの生成のたびに呼び出されるフックを定義して生SQLの実行に関するスパンから生のSQL文の情報を除去するようにしています(このような処理をしても、エージェントがパラメタを除いたSQLの構造を別途送信するので、トレースの解析に支障はでません)。
def process_trace(self, trace):
for span in trace:
# ddtrace.contrib.dbapi が生成したspanを書き換え
if span.span_type == ddtrace.ext.SpanTypes.SQL:
span.set_tag(ddtrace.ext.sql.QUERY, "")
return trace
Datadogの導入で変わったこと
Datadogにより、障害発生時に関係者が同じグラフを見て状況の認識を一致させ、対処の必要性や方針を素早く判断できるようになりました。特に、本番環境で実行された処理の内訳がAPMによって可視化され、性能劣化やエラー発生をリアルタイムで分析できるようになったことで、リリース起因での障害かどうかを素早く判定してロールバック対象を特定できるようになりました。
各種ログを素早く横断的に検索するための基盤
モノタロウのECサイトは、複数のWebサーバやAPIサーバの連携で成り立っています。個々のサーバは呼び出し元やリクエストの内容に関係なく、処理順にアプリケーションのログを出力します。そのため、ログの各行の間には明示的な関係性がありません。一方、アプリケーションの障害調査では「ユーザからのリクエストがバックエンド側でどう処理され、全体の処理時間がどの程度だったか」を知りたい場合があります。そのためには個々のサーバのログを紐づけて素早く横断的に検索するための手段が必要です。
モノタロウにおいて、ログを紐づける手段として使用しているのは、ユーザからのリクエストヘッダ(X-Request-Id)に付与される一意なIDです2。このIDをバックエンド側のサーバまで渡し、それが各アプリケーションやWebサーバのログに出力するようにしています。たとえばNginxやApacheでは、このIDがrequest_idというフィールド名でアクセスログに出力されるよう設定しています。これらのログをFluentdのtailプラグインで読み取り、最終的に高速な検索が可能なBigQueryへと集約しています。なお、処理の過程でもログの重複が起こりうることから、Apacheなどのリクエスト処理においても一意のIDを発行することで重複を除去する工夫をしています。
Webサーバだけでなく、Python製のアプリケーションからも必要な情報をログとしてBigQueryに送っています。その際には、アプリケーションの処理で定義される固有の情報や、POSTリクエストのパラメータのようなセンシティブな情報をマスクした上で、いったんFluent Bitに送り出します。具体的にはfluent-logger-pythonを利用した次のようなコードを組み込んでいます。
from fluent import sender
# リクエストヘッダ情報からIDを取り出す
request_id = request_headers.get('HTTP_X_REQUEST_ID')
data = {
# X-Request-Idの値
'request_id': request_id,
# リクエスト処理ごとのユニークな値
'unique_id': unique_id,
# セッション管理ID
'sid': session_id,
'request_uri': request_uri,
'request_params': params,
# ... その他、必要な情報を辞書に詰める
}
fluent_sender = sender.FluentSender('appslog')
# 処理開始時刻を記録したいため、emit_with_time()を使っている
fluent_sender.emit_with_time('app.request', int(request_time.timestamp()), data)
このコードによって、送出するデータには'appslog.app.request'というFluentdのタグが付与されます。これを次のように設定したFluent Bitでいったん転送し、Webサーバのログと同じく最終的にBigQueryへと集約します。
[SERVICE]
Flush 5
Daemon off
Log_Level info
[OUTPUT]
# forward output pluginを利用して、中央サーバーのfluentdへ集約してから処理している
Name forward
# このタグにマッチするログが収集される
Match appslog.app.request
# このホストに収集したログを転送している
Host aggregator
Port 24224
収集したログは現在ではほぼリアルタイムで参照できるようになっています。これにより、トラブル発生時の影響調査やユーザからの問い合わせ時にBigQueryで簡便かつ高速にログの調査ができるようになりました3。
今後の展望
Datadogの導入によってシステム運用の解像度が飛躍的に向上し、ログ基盤の整備によってフロントからバックエンドまでBigQueryで迅速かつ詳細に問題を追跡できるようになりました。現在は、これらを足がかりとして、運用監視のさらなる高度化を計画しています。具体的には、機能やコンポーネントごとにサービスレベル目標(SLO)を定義し、SLOの達成状況に基づいた監視やアラーティングを順次設定しています。これにより、「ユーザの期待を満たしているか」という観点でサービスを監視運用できるようになると考えています。
-
ダッシュボードを活用したトラブルシューティングの事例についてはモノタロウのブログ記事も参照ください。https://tech-blog.monotaro.com/entry/2021/05/20/070000↩
-
CDNであるAkamaiの機能を利用しています。↩
-
本ログ基盤についてはモノタロウ金谷の発表も参照してください。https://codezine.jp/article/detail/11630↩