この記事の初出は、Software Design2022年3月号「設計方針から変えていく、モノリシックなアプリの過去と未来(最終回)」で、加筆修正されています。過去の連載記事は以下を参照ください。
- 第1回 Software Design連載 2021年8月号 Python製のレガシー&大規模システムをどうリファクタリングするか - MonotaRO Tech Blog
- 第2回 Software Design連載 2021年9月号 「テストが無い」からの脱却 - MonotaRO Tech Blog
- 第3回 Software Design連載 2021年10月号 スナップショットテストの可能性を追求する - MonotaRO Tech Blog
- 第4回 Software Design連載 2021年11月号 Robot FrameworkでE2Eテストを自動化する - MonotaRO Tech Blog
- 第5回 Software Design連載 2021年12月号 リリース作業とエラー追跡の改善 - MonotaRO Tech Blog
- 第6回 Software Design連載 2022年1月号 運用監視の解像度アップとサービス横断的なログ基盤の整備 - MonotaRO Tech Blog
- 第7回 Software Design連載 2022年2月号 大規模Webアプリケーションの開発環境をモダナイズする - MonotaRO Tech Blog
- はじめに
- 内製システムの変遷
- 事業の成長にともなって生まれた、システムの課題
- 独立した小さなAPIアプリケーション開発への転換
- 新しい設計方針への手応え
- まとめと今後の展望
- We're Hiring!
はじめに
モノタロウのシステムを長年支えてきたのは、独自の内製フレームワークを使って開発された、モノリシックな構造のアプリケーション群です。
モノリシックな構造で開発をつづけてきたのには、それなりの理由と利点があります。
しかし、事業の成長とともに、アプリケーションに対する要求や、運用・開発体制のあり方が変化してくると、その設計にも転換が必要になってきました。
本稿では、モノタロウがこれからの成長に備えてレガシー化したアプリケーションの設計方針をどう変えていこうとしているのか、その試みの一つをご紹介します。
内製システムの変遷
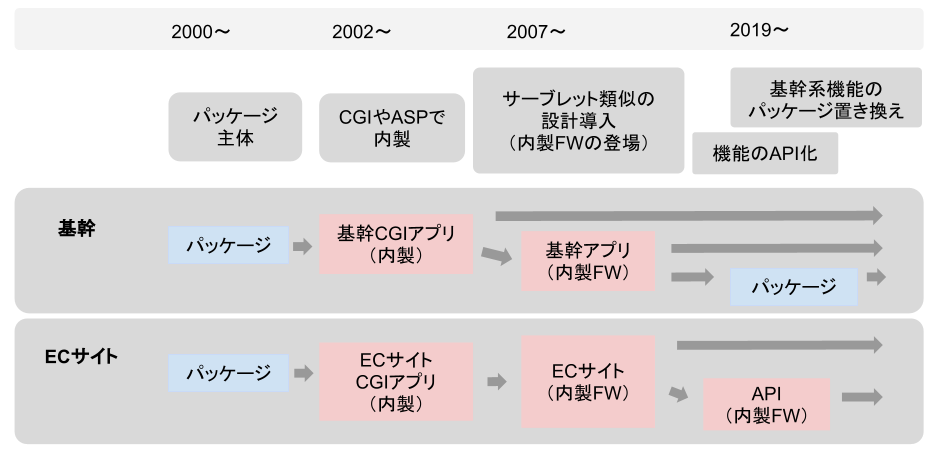
モノタロウの創業は2000年です。当時は、Pythonだけでなく、プログラミング言語全般で、完成度の高いWebフレームワークやライブラリがまだそれほど充実していませんでした。
小さくスタートアップしたモノタロウで、システムの何もかもを最初からフルスクラッチ開発するだけの開発力の余裕はなく、ECサイトや基幹系のシステムは、パッケージ製品とそのカスタマイズからスタートしました。
その後、ほどなくしてCGIやASPを使った内製に転換を図りました。ビジネスの形ができはじめて、サイトやバックオフィスに必要な機能が増えてくると、それらの機能をリクエストに応じて処理を切り替える仕組みや、工夫を凝らしたページコンテンツを生成するための処理を実装するために、パッケージにはない機能が必要になっていったからです。
創業当時の設計は、2022年現在でも、古いシステムのごく一部に引き継がれています。
ECサイトと基幹システムの一部の機能については、2000年代後半に、Javaサーブレットを参考にしたアプリケーション設計でPythonを使って書き換えが行われました。これが、現在まで続く内製システム開発のベースとなるフレームワークになりました。
独自の内製のものとはいえ、フレームワークを持てたことで、機能を追加拡張したいときの開発手順や、定型的な処理を安全に実行するための「型」ができました。開発のためのドキュメントも整備され、開発を進めやすくなりました。
内製の機能は、役割によって「非ビジネスロジック系のライブラリ」「ビジネスロジック系のライブラリ」のような大分類の下に、個別の機能ごとに分類してリポジトリに収容していました。もう一歩進めて、共通ライブラリリポジトリ的なものを作り、いずれは色々なアプリケーション間で共有して・・・ということができればよかったのかもしれませんが、そうはなりませんでした。
当時は、少人数のチームが数個のアプリケーションをメンテナンスする開発体制で、コードサイズもまだ小さく、比較的見通しやすかったことから、アプリケーションからライブラリを分離したり、小さいアプリケーションをたくさん運用することにインセンティブが生まれなかったのでしょう。
ECサイトも基幹系も、一つのアプリケーションに様々な機能が詰め込まれ、拡大していきました。 新たにアプリケーションのプロジェクトができるときは、既存のアプリケーションのリポジトリから、フレームワーク機能を含めたコードの複製を作って、それをベースに開発を立ち上げ、その後は別々のリポジトリで複数のアプリケーションをメンテナンスしていきました。
結果として、ECサイトも基幹システムも、1つのアプリケーションに多くの機能が盛り込まれ複雑化した、「少数のモノリシック構造のアプリ群」の形態へと成長していったのです。
事業の成長にともなって生まれた、システムの課題
独自とはいえ開発フレームワークを持ったこと、モノリシックなアプリケーションに機能が集約された構造は、機能の建て増しを容易にしてくれたことから、モノタロウのサービスの拡大や成長に大きな貢献を果たしてきました。
しかし、事業が成長してサービスや社内業務、お客様や取り扱い商品が多様で複雑になり、システムやそれを支えるIT系部門の組織が急速に拡大すると、課題も目立つようになってきました。
ビジネスに直結しない改修が増えてきた: 現在は、優れたWebアプリケーションフレームワークやデータバリデーション、データベース操作ライブラリなどが登場しています。それらは世界中の開発者に支えられて高い品質を保ち、世の中の標準を先取りしています。そうした技術トレンドから取り残されないためには、独自のフレームワークやライブラリに対して、機能追加や最適化、脆弱性対策などを自分たちだけで行い続けなければならず、本当にやりたいサービスの開発には専念できません。
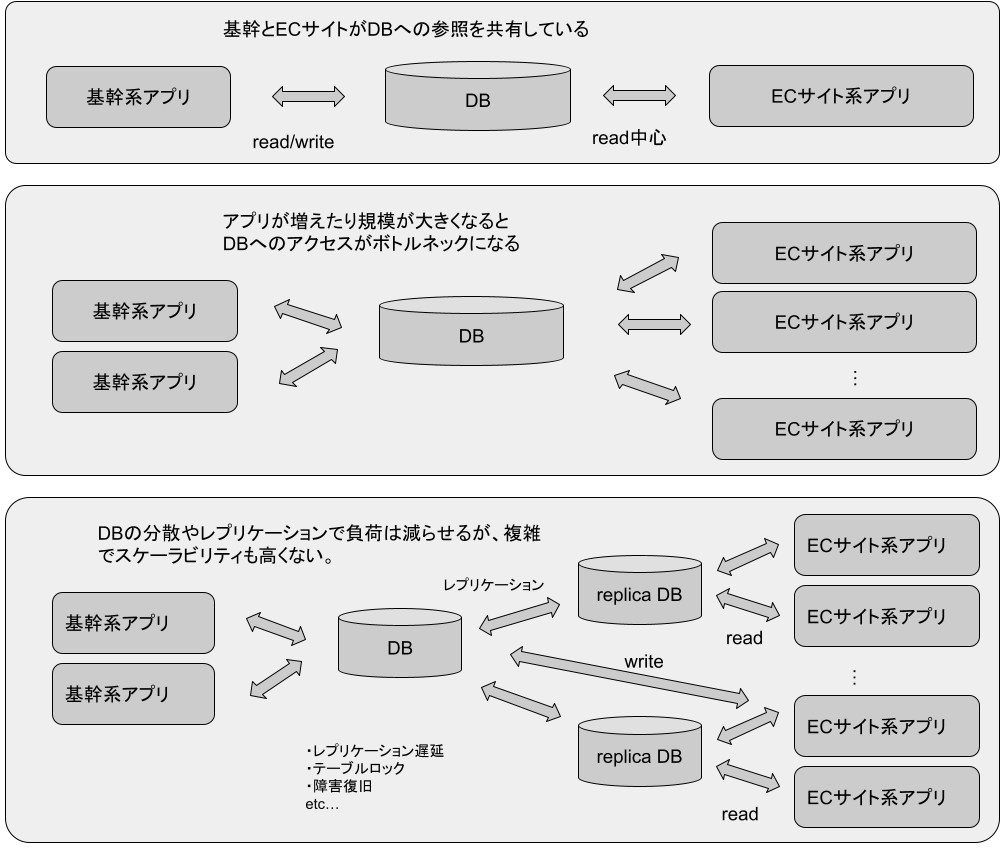
実装が分散する:アプリケーション間で共通の機能をリポジトリごとに別々のライブラリとして実装してきた結果、お互いに挙動やインタフェースが少しずつ異なる状態が発生するようになりました。法令対応などでビジネスロジックを横断的に改修する必要があると、改修範囲の見積りや実施の工数が膨らんでしまいます。
リリースが渋滞する:1つのアプリケーションにたくさんの機能が組み込まれている状況で多数の開発者が同時並行で改修を行うことからリリースの規模が大きくなります。開発者間の調整コストがかさむだけでなく、ステージング中に不具合が発見されてリリースが成功しないリスクも増えました。
テストがない:初期のアプリケーションはユニットテストや自動テストの仕組みがない時代に書かれたこともあり、テストを書きづらい仕組みの実装になっている場合があります。その後も似たような実装で拡張されてきたので、全体としてテストやリファクタリングを進めにくい状態でした。
スケールアウトや非同期化が難しい:物理ホスト上で動かしていた時代の設計であることから、実行環境のスケールアウトや非同期化によるスループット向上が難しいという側面があります。また、多機能でモノリシックなアプリケーションは一部の機能におけるメモリやCPUのリソース消費に引っ張られてスケール制御が必要になることがあり、効率的な制御が難しいという難点もあります。
仕様が忘れられていく:内製フレームワークにはドキュメントがない部分もあります。当時のメンバーが開発から離れるとフレームワークを安全に修正するのが困難になります。
ビジネスの成長にともなって顕在化したのは、これら独自フレームワークとモノリシックなアプリケーションに起因する課題だけではありません。たとえば、ECサイトと基幹システムのデータを保持するSQLデータベースへの負荷増大は、クエリのチューニングやデータベースのスケールだけでは対応しきれなくなってきています。
独立した小さなAPIアプリケーション開発への転換
こうした課題を解決して、これからも事業の成長を支え続けていくには、ソフトウェアの仕組みと、開発体制の両方の面での工夫が必要です。
既存の機能をスムーズに移行しつつ、新しい機能も効率的に開発するには、どのような取り組みが可能でしょうか。従来のモノリシックな形態のままシステム基盤の刷新を進めるという方法も考えられますが、いまの私たちの考え方は、「ある程度まとまった機能ごとに、既存のアプリケーションから機能を独立させて、APIを整備し、そのAPIを活用することで既存の機能を移行する」というものです。
小さな機能に対して使いやすいAPIを整備するという考え方は、サービスを開発する際の新たな設計方針にもなります。以降では、そのような設計方針のもと、推薦システム向けのAPIアプリケーションを開発した事例を紹介します。
推薦システム向けAPIの開発事例
ECサイトを訪れるお客様に最適な商品を見つけていただくため、商品推薦データを提供する機能は様々なページで頻繁に呼ばれます。推薦の基本的な仕組みはシンプルですが、日々様々な工夫によって改良されていくので、素早く実装しリリースすることが求められます。
推薦機能をシステム化するにあたって、内製の多機能なAPIアプリケーションの一部として実現することもできましたが、推薦システムは提供する機能が少なく、ECサイトの他の機能からは比較的独立しており、新たに独立したアプリケーションとして作成しても、ビジネスロジック部分の工数がさほど変わらないことが予想されました。
開発にあたっては、以下のようなことを念頭に進めていきました。
小さくつくる:推薦機能に限った独立したアプリケーションとして設計することで、その開発メンバーが自分たちの担当サービスの開発と運用に専念できるようにする。
内製をできるだけ避ける:業務ロジックのような既存の内製ライブラリを避けられない部分以外は、Python標準のモジュールやサードパーティ製のライブラリやフレームワークを活用して実装し直し、自社だけでメンテナンスしなければならないコードの量を小さくする。
標準に寄せる:自社流の伝統的な設計パターンではなく、フレームワークの標準的な実装パターンに従う。 フレームワークやコンポーネント間の依存をなくす:将来、業務ロジックや雑多なユーティリティの実装をライブラリとしてアプリケーションの外に切り出せるようにするため、フレームワークとの結びつきが起きないようにする。
型ヒントを導入する:Python3で使えるようになった型ヒントを試験的に導入し、プログラミング中にデータ型の不整合が起きるのを防ぐ。
バックエンド呼び出しを非同期化する:内製フレームワークでは同期的な呼び出しをせざるをえなかったが、Python3の concurrent.futuresを積極的に使って処理効率を上げる。
Docker環境で実行する:アプリケーションはDockerコンテナ化して、GKE(Google Kubernetes Engine)で実行する。
これらの基本的な方針のもと、Webフレームワークとしてはコンパクトで国内外のユーザも多いFlaskを選択しました。
データバリデーションに marshmallow と webargs、HTTPアクセスに requests を使うなど、これまで内製の実装でカバーしていた機能をサードーパーティのライブラリで置き換えました。 さらに、Python組み込みの itertools、contextlib、concurrent といった機能を使い、アルゴリズムの自前実装を避けました。
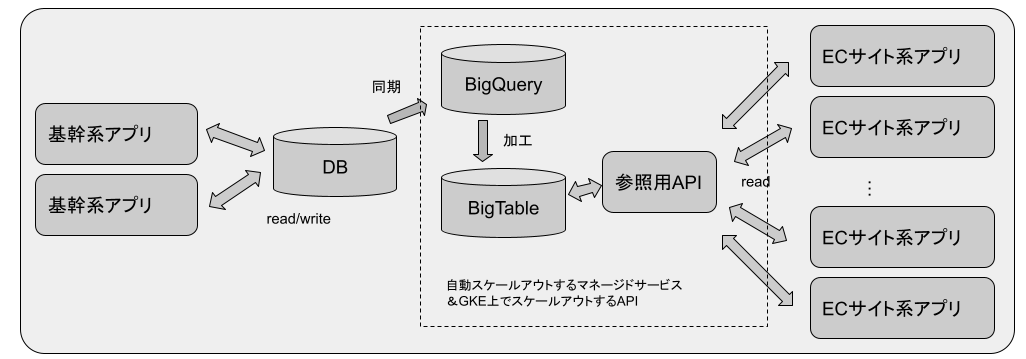
推薦データの参照方法も、SQLデータベースの参照ではなく、当時社内で完成していたDDP(Data Delivery Platform)APIを使いました。 推薦データは高いリアルタイム性が求められるデータではなく、他のシステムと共有のデータベースから読み出すメリットはありません。 SQLデータベースで都度クエリを組んでテーブルからデータを読み出す方式に対して、DDP APIは、あらかじめBigQueryで計算した推薦情報をBigtableに入れておき、そこからキーを指定してデータを読み出します。加工済みのデータを使って単純な参照に特化することで、高速かつ高いスケーラビリティを持っています。 *1
フレームワークやコンポーネント間の依存をなくす
推薦エンジンの内部では、推薦データを取得するために他のアプリケーションのAPIを呼び出します。その際、推薦エンジンの中でFlaskの機能やグローバルな変数を参照すると、依存関係ができてしまいます。
そこで以下のように、初期化した推薦エンジンをFlaskアプリケーションに注入し、そこにリクエストハンドラの中で構築した推薦処理のパラメタを渡すようにしました。パラメタのバリデーション(リクエストデータの型や範囲が正しいかどうかのチェック)とレスポンスの構築もリクエストハンドラで行い、推薦エンジンの挙動とは切り離しています。
依存関係の分離
def create_app(...): """Flaskアプリケーションのコンストラクタ""" ... # 推薦エンジンを初期化する recommender = Recommender( ... product_info_repository=..., # 商品情報参照のためのクラス data_repository=..., # 推薦情報参照のためのクラス(推薦エンジンと依存関係をもたせない) postprocesses=..., # 推薦の後処理テーブル(注入によって呼び出せるようにする) ... ) # 推薦エンジンをアプリに紐付ける with app.app_context(): current_app.recommender = recommender # 推薦エンジン自体もFlaskアプリに注入する ... def recommend(): """推薦処理のリクエストハンドラ""" try: # Flaskのリクエストをバリデーションして推薦処理のパラメタを構築する context_src = ContextSchema().load(request.args) except ValidationError as exc: # リクエストパラメタのバリデーションに失敗した場合 400 を返す abort(400) try: # 推薦処理のコンテキスト(パラメタ)を初期化し、推薦エンジンに渡す context = Context(**context_src) recommendation_result = current_app.recommender.recommend(context) # 注入された推薦エンジンを使う except RecommendationFailed as exc: # 推薦処理失敗のときは空の結果を 200 で返す ... except Exception: # 未知のエラーの場合には、エラーログを出力し raise する(結果的に 500 応答を返す) ... # 推薦処理が正常に完了したら応答を生成して返す response = build_response(recommendtaion_result) return jsonify(response)
型ヒントを導入する
推薦システムのAPI開発では、APIのリクエスト/レスポンスの構造や、推薦処理に使うパラメタおよび内部データの構造を開発中に何度も見直しました。型ヒントを指定していたおかげで、改修によって発生したデータ型の不整合をIDE上で検出、修正できたことが多々ありました。
型ヒントは、プリミティブ型であっても、アプリケーションの文脈に合わせた別名を付けて構造化しています。これにより複雑な構造のデータ型でも型ヒントが指定しやすくなると同時に、データ型を変更した場合に不整合が紛れ込みにくくなります。
推薦エンジンにおける型ヒントの定義例
from typing import NewType, Dict, Any, List … # 推薦エンジンのパラメタ型 LogicIdType = NewType("LogicIdType", str) # 実際にはプリミティブ型でも別名をつけておく MethodIdType = NewType("MethodIdType", str) # 商品関連のコード型 ProductCodeType = NewType("ProductCodeType", int) ... RecommendEntryType = Dict[str, Any] # より複雑な型を定義するときは別名を使うようにする ProductInfoMapType = Dict[RecommendType, Dict[ProductCodeType, RecommendEntryType]] ... RecommendListType = List[RecommendEntryType] UnionResultType = Dict[str, Any] RecommendResultType = Dict[FullUnionIdType, UnionResultType] ...
バックエンドAPI呼び出しを非同期化する
従来の内製フレームワークには、設計上、マルチスレッドで安全に動作することを保証できないという制約がありました。そのため、アプリケーション内から別のWeb APIを呼び出す場合、同期的な実行を余儀なくされていました。推薦システムの開発ではこの制約がなくなったので、concurrent.futures を使って推薦データを提供するWeb APIを非同期で呼び出す実装を採用しています。これにより処理効率と安定性が大きく改善しました。
複数のAPI呼び出しを非同期で実行する
class DataRepositoryDDP(DataRepositoryBase): """推薦データ提供APIからデータを取得するリポジトリ""" def __init__(self, …): self.executor = ThreadPoolExecutor(TPE_WORKER_POOLSIZE) self._threadlocal = local() # スレッド間で共有しない値はスレッドローカルに入れる ... def batch_query(self, queries, …): """複数クエリを一括非同期実行する""" futures_map = {} # クエリの非同期実行を走らせる for query in queries: futures_map[query.id] = self.executor.submit(self.run_query, query.params) # クエリ結果を収集する result_map = {} for query_id, future in futures_map.items(): result_map[id] = future.result() return result_map def threadlocal_session(self): # スレッドローカルなHTTPセッションを生成して保持する if not hasattr(self._threadlocal, “session”): self._threadlocal.session = Session() return self._threadlocal.session def run_query(self, query_params): """クエリを実行する""" session = self.threadlocal_session() # スレッドごとに別のセッションでクエリを実行する session.get(RECOMMEND_DATA_API_URL, …) ...
Docker環境で実行する
コンテナ環境の採用には2つの大きな恩恵がありました。1つめは、デプロイ方式を標準に寄せたことです。Kubernetesのオートスケールやワークロード管理の仕組みを利用できるので、モニタリングやCIとの連携のために独自の仕組みをつくる必要性がなくなります。
もう1つは、Pythonのバージョンやライブラリ、ミドルウェアの変更が容易になったことです。以前は仮想マシン上に実行環境を構築する必要があり、その都度システムインフラ担当の作業が発生していましたが、コンテナ化によってアプリケーション開発者の自由が効きやすくなりました。
なお、GKEの設定やECサイトのサービスに接続するためのネットワークの構成、Google Cloud Monitoringを使ったモニタリングの設定などは、terraformを使って定義し、アプリケーションとは別のリポジトリで管理しています。
新しい設計方針への手応え
新しい設計方針を採用した推薦システムのAPI開発では、内製フレームワークをベースにした従来の開発よりも、サービスの本質的な部分により専念できたという実感があります。
実際、本システムはアプリケーションの設計が固まってから半年ほどでサービスインしていますが、その間の開発作業の多くは、推薦エンジンの仕様変更への対応や非同期化のチューニングといったサービス本来の価値を提供するための時間にあてることができました。
サードパーティのフレームワークやライブラリのおかげで、リポジトリ内に配置されるコードが必要最小限になって見通しがよくなったことも特筆に値します。従来の設計方針では、アプリケーションのコードベースの10%強にあたる20000〜25000行がフレームワーク的な機能の実装に費やされていましたが、新しい設計方針ではその部分は1000行程度(推薦処理に関連するロジックとの比率では5%程度)にまで圧縮されました。
コンテナによるアプリケーション運用については、経験のあるメンバーが少なかったことから、運用開始直後はオートスケールのチューニングや運用基盤の整備に手間取ることもありました。しかし、その後は大きな不具合もなく順調に稼働しています。
現在では、本システムのAPI開発で得た経験に基づいて、商品検索系のAPIなどでも新しい設計方針への移行を始めています。
まとめと今後の展望
内製フレームワークをベースとしたモノリシックで大規模化したシステムの課題と、それをより小さなアプリケーションに分割していく際にAPIを整備して活用するという考え方を紹介しました。さらに、その方針で新たなAPIアプリケーションを開発する事例として、ECサイトにおける推薦システムの設計を説明しました。
サービスの分割と小規模化は始まったばかりの取り組みであり、採用するフレームワークや実装はこれからも少しづつ変化してゆくかもしれません。しかし、ビジネスの規模や開発体制に合わせた粒度でアプリケーションを分割統合していくことや、長期的な生産性維持のために標準的なアーキテクチャを意識してベストプラクティスに学び、最適な作り方を見直し続けていくという姿勢は、これからも続けていきたいと考えています。
We're Hiring!
モノタロウではエンジニア、データサイエンティストを募集しています。
カジュアル面談も実施していますので、ご興味がありましたら、ぜひ カジュアルMTG登録フォーム
よりご応募ください!
*1:データ基盤の導入については弊社テックブログ記事 https://tech-blog.monotaro.com/entry/2021/12/23/090000 も参照ください。