新年あけましておめでとうございます。モノタロウでエンジニアをしております大西です。本年もよろしくお願いいたします。
本年もMonotaRO Tech Blogでは社内の様々な取り組みを定期的に更新して参りますので、お時間の空いた際にお読み頂けると嬉しく思います。皆様のお役に少しでも立つことができれば幸いです。
今回は、リリースにかかる時間の増加や、リリースに関する作業の属人化を体制変更によって解消した経緯と、大規模な開発体制におけるリリース作業や監視業務でのエラーやアラートの管理方法についてご紹介します。
本記事の初出は、 Software Design2021年12月号「Pythonモダン化計画(第5回)」になります。 過去の連載記事は以下を参照ください。
- 第1回 Software Design連載 2021年8月号 Python製のレガシー&大規模システムをどうリファクタリングするか
- 第2回 Software Design連載 2021年9月号 「テストが無い」からの脱却
第4回 Software Design連載 2021年11月号 Robot FrameworkでE2Eテストを自動化する
リリースと監視の改善について
今回は、日々成長していく大規模システムのリリースと、その不具合を追跡して安定運用していくための監視のしくみについて、どのような改善が可能かを紹介します。
前半では、比較的大規模なシステムにおいてリリースフローが抱えがちな課題と、その改善へ向けてモノタロウのECサイトが採用したアプローチを紹介します。後半では、リリースや定常監視において発生するエラーやアラートを大人数で共有、管理するために、エラー追跡システムSentryを導入した事例を紹介します。
規模の拡大に伴うリリースの肥大化
モノタロウのECサイトの画面機能は、舞台裏では参照系(商品ページ生成など)と更新系(ユーザー登録や注文など)の大きく2つのサービスで構成されています。これら2つのサービスは、機能的にはほぼ分離しているのですが、歴史的な経緯もあって同時にリリース作業を行っています。
事業の成長とともに開発内容が多様化し、規模も拡大したことで、この「同時リリースにかかる時間の増加」が問題になっていました。具体的には、週1回のリリースに含まれる修正案件の数が、多いときには2つのサービスで合わせて40件に達するという状態でした。リリース対象の案件はどれなのか、それぞれ準備はできているのかなどの確認も煩雑で、必要以上に時間がかかっていることも問題でした。
それに加えて「リリースに関する作業の属人化」という課題もありました。2つのサービスの開発チームのそれぞれで、経験豊富な一部のメンバーにしかリリースが実施できず、改善に向けた取り組みもままならない状況でした。
リリース専任チームの立ち上げ
これらリリースにまつわる課題を解決するためにモノタロウが講じた対策は、リリース専任チームの立ち上げでした。専任チームがリリースのしくみを改善しつつ、それぞれの開発チームから依頼を受けてリリースの実務を一手に担当するという体制です。
専任チームでは、まずリリースプロセスを整備し、誰でもわかるような手順書を作成しました。これにより、経験値の高いメンバーにリリース作業が属人化する状態を解消し、基本的には誰でもリリースを実施できるようにしました。
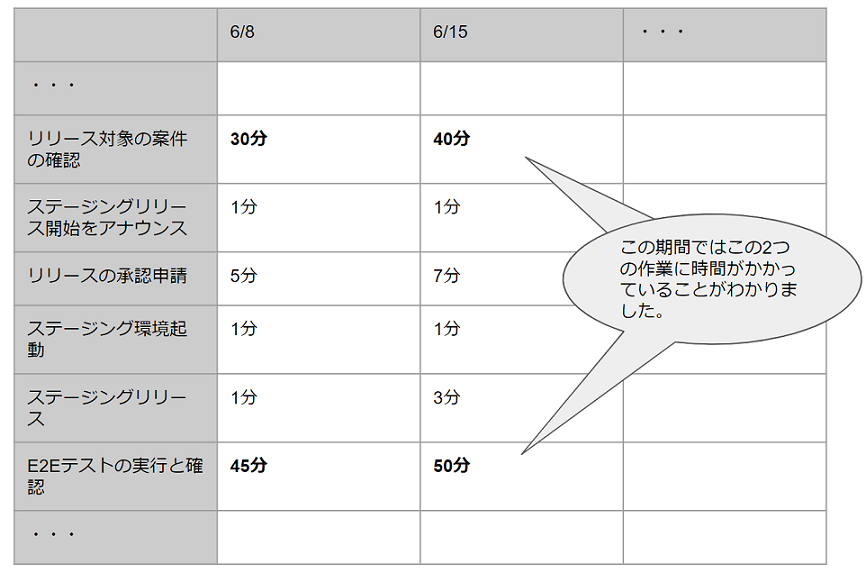
次に、リリースプロセスの計測をはじめ、「何に時間がかかっているか」をプロファイリングしました。はじめは「リリース準備が完了するまでの時間」といった大きな単位での計測でしたが、徐々に、前述の手順書のステップごとに時間がかかっている箇所を特定してそれを解消する施策を実施していきました。図1はそのときの計測結果の様子です。毎回のリリースで実際にかかった時間を各行のステップごとに記録していき、洗い出しました。その結果、次のようなことがわかってきました。
リリースに関与している案件や、個々のリリース状況の確認に時間がかかっていた
E2Eテストの実行時間が増えてきていた
リリース手順全体のステップ数が多く、短期的な改善が難しいことから、関連する案件の数が少なかったとしても一定時間かかってしまう
以降では、計測に基づいたリリースの改善でとくに効果があった施策をいくつか紹介します。リリース作業も、ソフトウェアそのものと同様に、計測とそれに基づいた改善の積み重ねによって課題を解消できることをお伝えできればと思います。
リリース状況を一括で確認できるボードを自動生成する
モノタロウにおける開発では、イシュー管理にJIRAを採用しています。そこで、まずはJIRAのREST APIでリリース対象の案件を取得してGoogleスプレッドシートに出力するツールを、 Google Apps Scriptで作りました。このスプレッドシートのことを、社内では「リリースボード」と呼んでいます。リリースボードを作成したことで、大量の案件の確認が簡単にできるようになり、リリースにかかる時間を短縮できました。
E2Eテストの実行時間を並列化で改善する
モノタロウでは、ステージングと本番環境のリリース後に、Jenkinsを使ってE2Eテストを自動で実行しています。そのテストケースはECサイトの主要機能を網羅するものとなっており、 1 回の実行に30分ほどかかっていました。Jenkinsのジョブ実行の一部を並列に実行するように変更することで、このテストにかかる時間を約半分に短縮しました。
リリース回数を減らす
短期的にリリースの問題を改善する時間が取れなかったこともあり、もし影響があった場合には元に戻すという判断のもと、周囲と調整してリリースの頻度を見直すという施策も実施しました。
具体的には、以前は毎週2回だったリリースを、専任チームを立ち上げたタイミングで週1回へと変更しました。リリース作業にかかる時間が約半分に減ったことで、開発者が開発に専念する時間を増やすことができ、単純ながら効果が大きい施策だったと言えます。
リリース作業の改善は終わらない
ここまで、当初の課題であったリリースにかかる時間の増加やリリースに関する作業の属人化を、リリース専任チームの設置という体制変更によって解消した経緯を紹介してきました。もちろん、体制変更だけで当初の課題が解消したわけではありません。「きちんとした計測や主体的なフローの改良には、そのための体制が必要である」という認識のもとで体制変更に取り組み、それが功を奏した結果です。
ただし、現状が最適なリリースの体制かというと、そうとも言い切れないと考えています。リリースの頻度を抑えているということは、一度のリリースにおいて発生する変更が多くなっている状態です。たくさんの変更があれば、それだけ関与する人の数も多くなり、調整が必要な場面も増えます。それを緩和するには、全体を一括でリリースするのではなく、互いに独立した小さな単位で個別にリリースする方針のほうが望ましいでしょう。
現在は、専任チーム化によって当初の課題は解消したものの、それによってまた新たな課題も見えてきた段階だと言えます。サービスを小さく分割していくなど、引き続きリリース作業の改善につながる取り組みを続けていく予定です。
リリースや監視に伴うエラーの運用
ここからは、大規模な開発体制におけるリリース作業や監視業務でエラーやアラートをどのように共有、管理しているかを紹介します。モノタロウの開発チームは10以上あり、開発者数の総勢は100名を超えるので、こうしたイベントを運用するためのしくみが欠かせません。
以前は、これらのイベントが発生した場合、その情報を開発者がそれぞれメールで受け取るだけでした。メールによる運用には次のような課題がありました。
エラー内容やスタックトレースがテキストで見づらい
1通ごとに開かなければ内容がわからない
いつから発生しているエラーかわからない
対象ユーザーの規模がわからない
「担当者が着手済み」「無視して良い」といった情報を共有しづらい
モノタロウではこれらの課題に対処するため、エラーやアラートの一元化と集約、分類、可視化、そして対応ステータスの管理に対するニーズに最も適合した機能を持ったツールとして、2018年にエラートラッキングシステムであるSentryを導入しました。
導入以前は大量に発生するエラーの発生条件や発生箇所の特定に手一杯で、改善まで手が回っていない状態でしたが、現在ではSentryによって円滑にエラーやアラートの運用が可能になったことで、エラー件数を大幅に削減することも実現できています。
Sentry SDKの導入
SentryはソフトウェアにSDKを組み込んで使います。このSDKを使うことで、ソフトウェアの中でエラーやアラートが検出されたとき、Sentryサーバにその情報を送出できます。これを受け取ったSentryサーバが、エラーやアラートを整理、可視化して表示するというしくみです。
SentryのSDKは、モノタロウで利用している Python や JavaScript のほか、PHP、Java、Ruby、.NET、Goなどさまざまな言語環境に対応しています。
リスト1に、アプリケーションの中でSentry SDKを初期化し、エラーを検出したときにどんなデータを追加で送信するかを設定する例を示します。このコードはモノタロウで実際に利用している実装に基づいた例で、内製のWebフレームワークからユーザー情報やヘッダ情報を引き出し、それらを送信するデータに設定しています。
▼リスト1 Sentryの利用例
from sentry_sdk import configure_scope from sentry_sdk.integrations.logging import LoggingIntegration def setup_sdk(): """Sentry SDKをセットアップする""" sentry_sdk.init( dsn=<sentryのurl>, # 警告レベルのログはSentryにも送る integrations=[LoggingIntegration(event_level=logging.WARNING)], environment=config.SENTRY_ENVIRONMENT, ... ) def setup_scope(): """Sentryに送信するデータを設定する""" with configure_scope() as scope: # 内製フレームワークでリクエスト・セッションオブジェクトを得る req = Request() session = Session() # リクエストURL scope.transaction = req.get_environ_request_uri() # ユーザを区別するID:botの場合はまとめる user_id = "Akamai-Bot" if req.is_from_bot() else digest(session.session_id) # スコープ(送信データ)を構築する scope.user = {"id": user_id} scope.set_tag("host_type", "b2b-website") # リクエストヘッダ・WSGI環境変数を送信データに追加する scope.set_extra( "request", { "headers": { "User-Agent": req.get_user_agent(), "Referer": req.get_referrer(), ... }, "env": { "REMOTE_ADDR": req.get_environ_remote_addr(), ... }, },
なお、Sentryはエラー監視以外にも利用できます。たとえばモノタロウでは、不要なソースコードを削除したい場合に、「そのソースコードが実際に使われていないか」を確認するためにSentryを利用しています。具体的には、削除したい箇所にSentry SDKで警告が送信されるようなコードを仕込み、システムを一定期間監視して該当する通知がなければ削除するようにしています。
エラーの特定と共有を助けるSentryの画面表示
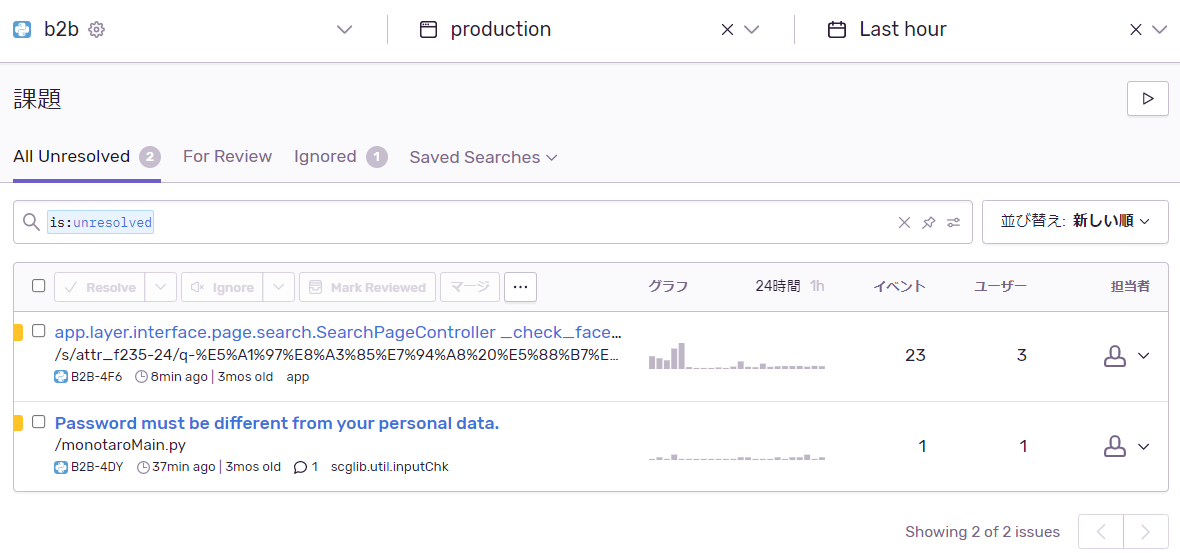
Sentryを有効にした状態でエラーが発生すると、エラーに関する情報がクラウド上のSentryサーバに送られ、Web UIで確認できるようになります。一覧画面(図 2)では、同じ内容のエラーが集約されて1つのエラーとして表示されます。発生件数とユーザー数を手動で集計する必要はありません。また、エラーごとに発生件数(1時間および24時間以内)の棒グラフ、初回発生時刻と直近の発生時刻が表示され、一目で状況を確認できます。フィルタ機能も充実しており、デバイス、ブラウザ、サーバ名、発生期間、キーワードなどを指定してエラーを絞り込むことができます。
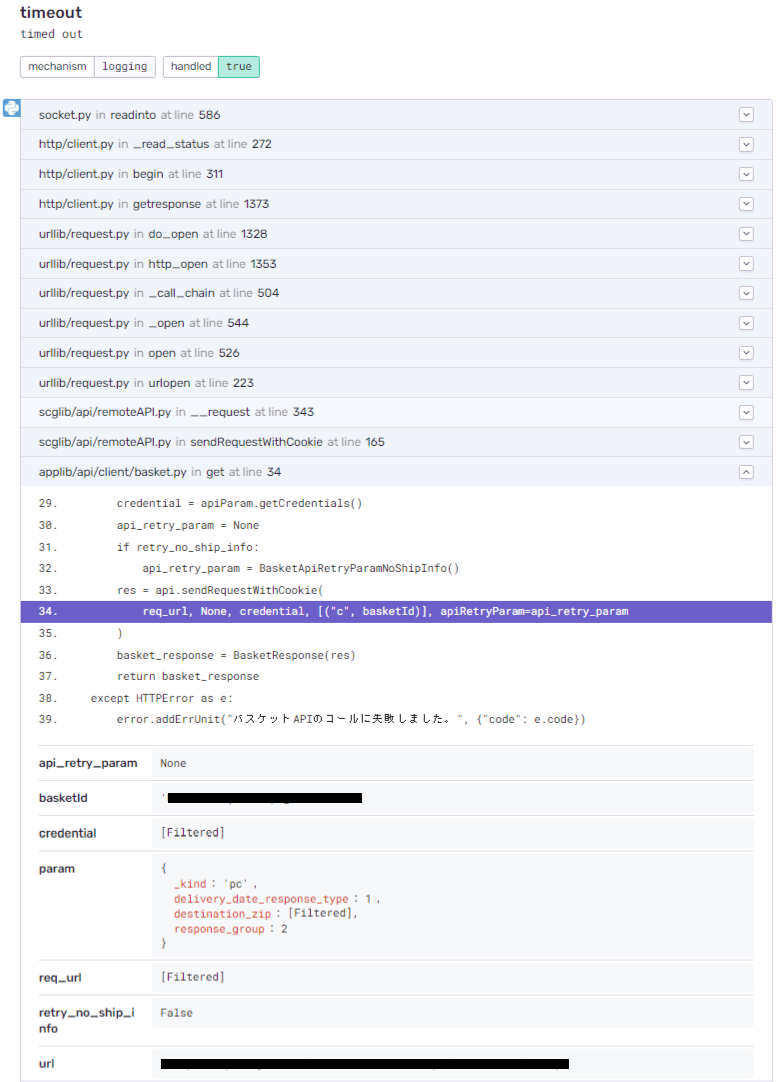
詳細画面ではスタックトレース を確認できます(図 3)。Sentryの導入前は、メール通知のスタックトレースをテキストで確認していましたが、スタイルが適用されたWeb UIで視覚的に原因を特定できるようになりました。スタックトレースには前後のソースコードと変数の内容も表示されるので、これらの情報もエラーの原因を特定する際に活用できます。
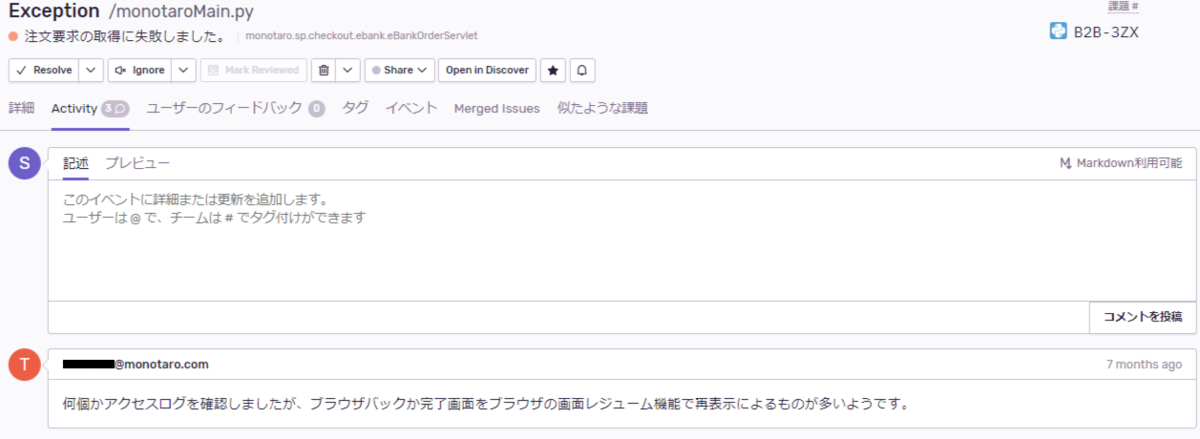
詳細画面には、エラーごとに担当者をアサインしたり、コメントを記載したりする機能もあります(図 4)。モノタロウでは、コメントとして調査結果を記載するというルールにしています。ステータスも設定できるので、対応済みのエラーはステータスを「解決済み」に設定することでフィルタによって非表示にしたり、通知が不要なエラーのステータスを「無視」に設定することで必要最低限の情報だけが受け取れるようにしたり、さまざまな工夫ができるようになっています。これらの機能を活用することで、Sentry導入前には難しかった複数のグループ間でエラーの状況の共有もしやすくなりました。
さらに詳細画面には一度開いたメンバーのアイコンも表示されます。これにより「そのエラーをどのメンバーが確認しているか」を把握できるのも特徴です。
リリースや定常監視でSentryを活用
モノタロウで実際にどのようにSentryを活用しているのか、少し紹介します。
リリースを実施した際は、リリース前後のエラーや警告の発生数を表示し、新規に発生したものや、既存のエラーで発生数が増加しているものがないかをSentryで調べます。リリース起因であると推測されるエラーが見つかったときは、詳細画面の情報を見て、リリース専任チームが原因となったリリースを特定したり、開発担当者が対応に着手したりします。
なお、ECサイトの運用で不具合が発生した場合は、不具合によって影響を受けたユーザー数を推定する必要もあります。モノタロウでは、Sentryにエラーなどの情報を送信する際、セッションごとに一意な値へと集約して送信しているので、そこから「何人のユーザーが何回影響を受けたか」を把握できます(ちなみに、botやクローラーのアクセスは全体が1ユーザーとしてカウントされるように集約しています)。
リリースがない日でも、監視担当チームが前日に発生したエラーを毎朝Sentryで確認し、その結果をサマリーにしてSlackに投稿しています。調査が必要なエラーが発生した場合、監視担当チームが一次対応を行ったうえで、それが直近のリリースと関係がある問題であれば、その案件担当者が引き継いで調査と改修にあたります。
Sentryでスタックトレースが表示されない場合
最後に、モノタロウでSentryを導入する際に少しだけ苦労した、文字コードに関する注意点を共有したいと思います。
SentryはSDKを組み込んだソースコードを、 UTF-8でエンコードされているものとみなすので、それ以外の文字コードを利用しているシステムに導入すると、デコード処理に失敗してWeb UI上でスタックトレースの内容がまったく表示されない場合があります。Sentry導入当時、我々のソースコードはPython 2ベースであり、エンコーディングもcp932としていたことから、導入前の動作確認でこの問題が発生しました。
この問題に対しては、SentryのSDKでソースコードの解析に利用されているPythonコードをリスト2のようなパッチによって動的に差し替える、という回避策を導入していました(現在はモノタロウのシステムが、デフォルトエンコーディングがUTF-8になったPython3に移行しているのでこの回避策は必要なくなっています)。
import sentry_sdk from six import PY3 if not PY3: # Python2のときにのみパッチする # オリジナルの get_lines_from_file を退避する _orig_get_lines_from_file = sentry_sdk.utils.get_lines_from_file # utf-8とcp932でのデコードを順に試すデコーダを定義する def force_to_utf8(s): if not isinstance(s, bytes): return str(s) for encoding in ['utf-8', 'cp932']: try: u = s.decode(encoding, 'strict') # デコードを試みる return u.encode('utf-8', 'xmlcharrefreplace') # デコードできたら utf-8 bytes で返す except: pass # オリジナルの get_lines_from_file をラップして、戻り値をutf-8エンコードして返す def cp932_aware_get_lines_from_file(filename, lineno, loader=None, module=None): pre_context, context_line, post_context = _orig_get_lines_from_file(filename, lineno, loader, module) return ( None if pre_context is None else [force_to_utf8(s) for s in pre_context], None if context_line is None else force_to_utf8(context_line), None if post_context is None else [force_to_utf8(s) for s in post_context]) # sentry_sdk の機能を差し替える sentry_sdk.utils.get_lines_from_file = cp932_aware_get_lines_from_file
おわりに
今回は、モノタロウのECサイトシステムにおけるリリースフローの改善と、リリース後や定常監視におけるエラー追跡の改善について紹介しました。こうした業務は、人手でなんとか乗り切っている現場も少なくないと思いますが、開発の規模が大きくなるほどシステマチックなしくみへの取り組みが効いてくる部分です。開発内容や組織の文化によって最適な手法は異なると思いますが、ここで紹介したモノタロウの事例が読者のみなさんの現場における改善のヒントになれば幸いです。