Software Design連載開始
※ (2021/09/02 08:55) 「Pythonを用いて開発を始めたのが2003年」を「Pythonを用いて開発を始めたのが2002年」に修正
こんにちは。金谷です。
このたび、モノタロウにおけるPython大規模開発に関する取り組みを、技術評論社様で発刊されている Software Design に連載させていただくことになりました。 モノタロウがPythonを用いて開発を始めたのが2002年。2021年の現在もPythonを用いた開発が続けられています。 事業の成長に伴い、関連するシステムやエンジニアの数も増え続けていくなかで、いかに安定的に価値を提供し続けられるのか。 モノタロウにおける取り組みを、開発や運用周りを通してご紹介していきます。
本記事の初出は、 Software Design2021年8月号「Pythonモダン化計画(第1回)」になります。
Python製のレガシー&大規模システムをどうリファクタリングするか
モノタロウでエンジニアリングマネージャーをしている金谷です。モノタロウは事業者向けの間接資材を販売するECサイトを運営しています。 ECサイトと基幹システムは2003年頃からPythonを用いて自社開発しており、今ではデータ基盤など多くの領域でPythonを使用しています。
自社開発の対象システムが増えてエンジニアも増える中で浮上してきたのが、理解しにくく変更もテストも難しいといった、システムの保守性という課題です。
モノタロウのシステムにおける保守性の課題
モノタロウが直面した保守性の課題の背景にあったのは、開発当初の2002年には現代では当然となっている開発プラクティスがまだ一般的でなかったことです。 具体的には、次のような技術的負債を抱えたいわゆるレガシーシステムの保守がモノタロウにとっての課題でした。
- 独自Webフレームワーク上で開発し続けている
- 業務ロジックと画面ロジックが混在している
- 自動化されたテストがなく手動テストに多くの時間を割いている
- 組み込み型だけでロジックが書かれる傾向にある
モノタロウのシステムの課題と対策を整理すると、次の3つになります。
- コードレベルの課題 → ユニットテストとリファクタリング
- サブシステムレベルの課題 → 結合テスト、サブシステムの分離と新旧比較テスト
- サービスレベルの課題 → 受け入れテスト、リリース後の監視体制強化
第1回は、コードレベルの課題とそれを解消するためのユニットテストとリファクタリングについてご紹介します。 とくにモノタロウではソースコードの分量も開発に携わるエンジニアも多く、そのような大規模開発の現場では、ユニットテストを導入してリファクタリングを始めるといっても一筋縄ではいきません。 そこには技術面と組織面でそれぞれ解決が必要な課題がいくつかありました。
リファクタリングの対象をどう見つけるか
モノタロウのシステムのとあるGitリポジトリでは、約1400ファイル、25万行のPythonコードを管理しています。 これだけ大量のソースがあると、闇雲にリファクタリングをするわけにもいきません。そこで、まずは開発組織全体でリファクタリングの対象を特定する方針を揃えることにしました。
さまざまなアプローチが考えられますが、モノタロウでは富士ゼロックス(当時)の取り組みを参考に、リファクタリング対象のファイルを定量的に特定することにしました。 具体的には、「よく変更される複雑なファイルで、メンテナンス性がないものは、リファクタリング対象である」という仮説を立てて、Gitリポジトリで管理されているPythonファイルに対して下記の情報を測定しました。
- ある期間内でのGitコミットの数
- コードの複雑さ
ある期間内でのGitコミットの数は、git ls-filesとgit logコマンドを組み合わせてカウントできます。
コードの複雑さについては、Pythonソースコードの品質を数値化するradonというツールを用いて計測しました。 radonには、Pythonソースコードの行数や条件分岐の多さに基づいて、ファイル単位での保守容易性指数(Maintainability Index)と呼ばれる値を返すmiサブコマンドがあります。 Gitコミット回数もファイル単位で計算されることから相性がいい指標であると判断しました。
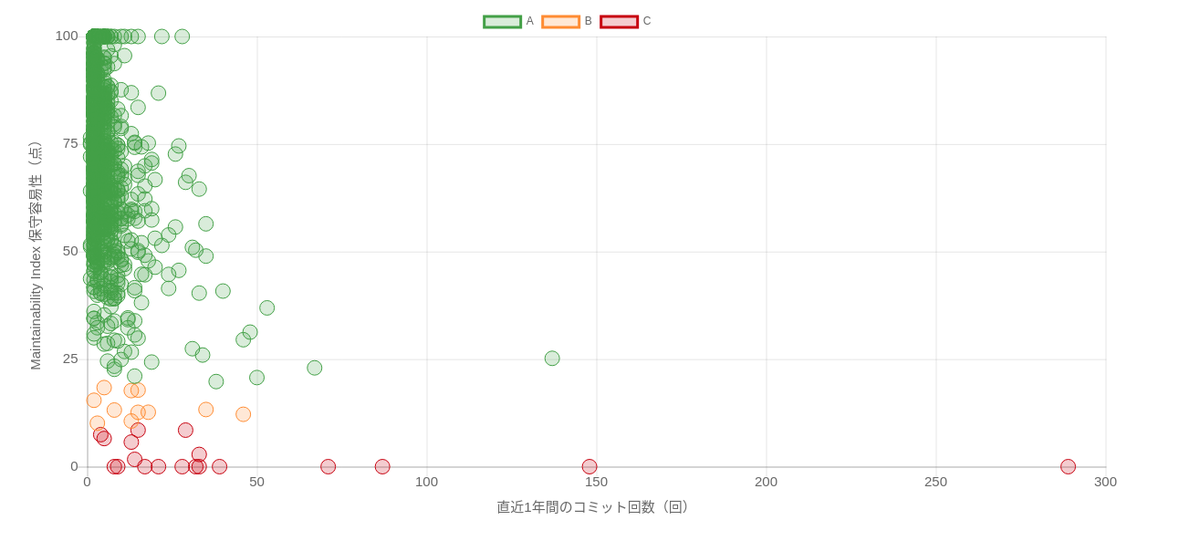
これら2つの量がファイルごとに得られたら、以下の図のように2つの軸に沿ってプロットすることで、全部で4つのエリアに区分できます。 このうちNGエリアにあるものをリファクタリング対象ファイルとして特定し、実際にリファクタリングに着手していきました。

約1400ファイル、約25万行というモノタロウのリポジトリでこの分析を実行した結果を以下の図に示します。 この例の場合には、保守容易性指数が20以下でコミット回数が直近1年間で30回以上のものをNGエリアとみなし、リファクタリングの対象にしました。
なお、このグラフを描くためのデータは、皆さんのリポジトリでも以下のようなコマンドを使って取得できます。気になる方は一度試してみてください。
# radonはpip経由で入手できる $ pip install radon # srcフォルダにあるPythonファイルを対象として分析する例 $ git ls-files | grep -e "^src/.*\.py" | while read file; do commits=`git log --since=2021-01-01 --oneline -- $file | wc -l`; echo "$file $commits"; done | sort > commits.txt $ radon mi -s src | sort > mi.txt $ join commits.txt mi.txt
実際のリファクタリングの作業はおおむね以下のステップで行っています。
radonの循環的複雑度(Cyclomatic Complexity)で、複雑なメソッドを特定する- 対象メソッドに対するユニットテストがなければユニットテストを書く
- 対象メソッドで「不吉な臭い」がする部分をリファクタリングする
- 最終的に、ロジックを別モジュールにする(OKエリアに移動する)
「不吉な臭い」など、リファクタリングの一般論については、『リファクタリング』や『レガシーコード改善ガイド』などの書籍を参照してください。 参考までに、モノタロウのシステムで実際に必要になることが多いのは「メソッドの抽出」、「コレクション型の作成」、「早期リターン」といったリファクタリングです。
また、リファクタリングよりも規模の大きいリアーキテクティングも行っています。詳細は弊社のエンジニアによる発表資料(「Clean Architectureへの取り組み」)をご覧ください。
ユニットテストを組織に定着させる
リファクタリングにはユニットテストが不可欠です。 しかし2003年から大人数で開発しているレガシーシステムには、ユニットテストがない箇所や、ユニットテストに慣れていない開発現場もありました。 そのため、どうすればエンジニア全員がユニットテストを書いて開発フローに組み込む状態になるかを考える必要がありました。
基本的な考え方は、自分が「まだユニットテストを書いたことがないエンジニア」の立場になって「どのような懸念があるか」を洗い出し、その懸念を解消する手段を講じるという方針で進めることにしました。 そのために、「懸念が払拭された状態(中間ゴール)」と、「その中間ゴールに到達するための行動」を、それぞれ下記の表のように整理しました。
| 懸念 | 中間ゴール | 中間ゴールに到達する行動 |
|
|
|
|
|
|
|
|
|
「中間ゴールに到達する行動」を実施していったところ、結果としてユニットテストを開発者全員が書く状態になりました。 ここ最近でも、約3ヶ月で450の新しいテストケースが作成され、ほぼ毎日全テストケースをパスする状態を保っています。
モノタロウにおいてユニットテストを組織に定着させるために必要だった「中間ゴールに到達する行動」のうち、ここではpytestとパラメタライズドテストについて少し補足します。
pytest
モノタロウでは、開発者全員が実際にユニットテストを書ける状態になるうえで、アサーションの可読性を高くすることが重要だと考えました。 この点でPython標準のunittestには、不慣れな開発者にとって次のような課題があると考えられます。
self.assertGreater(a, b)というアサーションがa > bなのかa < bなのかが分かりにくいself.assertEquals(expect, actual)とself.assertEquals(actual, expect)のどちらに合わせればいいのか分かりにくい
def test_pi_unittest(self):
from math import pi
# Assert that pi is greater than 3.14 と解釈する(大変)
self.assertGreater(pi, 3.14)
pytestでは、これらは assert a > b や assert expect == actual と書けるので、「何を検証したかったのか」がすぐに伝わります。
def test_pi_pytest(self):
from math import pi
assert pi > 3.14 # unittestより直感的
さらに、pytestにはレポーティングが分かりやすいという利点もあります。
とはいえ、実際には最初にある程度の量のユニットテストをunittestで書いてしまっていたので、現在すべてのユニットテストがpytest流で書かれているわけではありません。 しかしpytestはunittest流に書かれたテストも問題なく解釈、実行できます。 結果として、テストの書き方はunittest流、アサーションはpytest流、テストランナーはpytestという歪な状態になりましたが、それでもエンジニアたちの開発に支障はないので良しとしています。
パラメタライズドテストによるテストコードとパターンの分離
コードレビュー対象にユニットテストが含まれることで、ユニットテストの可読性も気にする必要が出てきます。 特に気になるのは、テストパターンがユニットテストのコード内に埋もれてしまって網羅性がわかりにくくなってしまう可能性です。
対策として、テストパターンのみを切り替えてテストするパラメタライズドテストを利用します。 これにより、テストの実行とテストパターンの整備を分離し、テストパターンの網羅性とユニットテストの可読性向上の両方が実現できます。
from unittest import TestCase
from parameterized import parameterized
class FizzBuzzTest(TestCase):
@parameterized.expand( # テストパターン
[
(1, "1"), # test_fizzbuzzのnには1, expectedには"1"が入る
(2, "2"),
(3, "Fizz"),
(4, "4"),
(5, "Buzz"),
(15, "FizzBuzz"),
]
)
def test_fizzbuzz(self, n, expected):
from fizzbuzz import fizzbuzz
assert fizzbuzz(n) == expected
なお、下記のように1つのテストケース内に複数パターンのテストを書くこともできるのですが、途中でfailした場合に後続パターンのテストが行われないためオススメしません。
def test_nogood_fizzbuzz(self):
from fizzbuzz import fizzbuzz
assert fizzbuzz(1) == "1"
assert fizzbuzz(2) == "1" # ここでfailし後続は行われない
assert fizzbuzz(3) == "FizzBuzz"
assert fizzbuzz(4) == "1" # ここのfailを検出できない
ユニットテスト導入に向けての技術的な課題解消
最後に、独自フレームワークへのユニットテスト導入で技術的な課題だった点を紹介します。 モノタロウの場合、ユニットテストしにくいコードへの導入を紐解くと、大きく次の3つの課題がありました。
- ユニットテスト対象のソースコードの読み込みと実行の時点で、モジュール読み込みエラーになる
- モジュールに対して変更を加える処理がある(他のテストケースに影響あり)
- 1メソッド当たりのソースコードが長い
このうち「1メソッド当たりのソースコードの長さ」については、すでに紹介したリファクタリングの取り組みの中で解消できました。 他の2つの課題については、「モックの活用」と「モジュールのスナップショット」により解消できたので、最後にその2つについて紹介します。
モックの活用
ユニットテストにおけるモックの使い方には下記のようなパターンがあります。
- モジュールそのもののモック化
- モジュール内の特定関数のモック化
- テスト対象クラスのメソッドのモック化
1つめは、モジュールを読み込む時点で何らかのエラーを返すパターンです。 ライブラリがなかったり特定環境でしか動かなかったりするケースで発生するので、該当モジュールをどこかで読み込む前に、モジュール自体をモックに置き換えてしまうことで回避します。
2つめは、モジュールの読み込みに成功していざ実行する際の挙動を変える場合に使用するパターンです。 たとえば以下のようなソースコードがあったとします。
import faillib # このモジュール読み込みでfailするケース
from failfunc import fail_func
class Production:
def target_method(self, n):
return n * 5
def get_failfunc(self):
return fail_func() + 'ful.' # モジュール実行時にfailするケース
def failfunc_in_production(self):
return self.abc() + 'def' # 自前のメソッドや関数実行時にfailするケース
def abc(self):
raise ValueError('Error function')
このコードに対するユニットテストは、テスト対象のソースコードをインポートする前に、対象モジュールにパッチを当てる実装を入れることで実現できます。 パッチはwith節内でのみ有効で、with節のスコープから抜けるときにはパッチを当てる前の状態に戻ります。
from unittest import TestCase
from unittest.mock import MagicMock, patch
from sys import modules
# ロード時点で失敗するモジュールにパッチを当てる
modules['faillib'] = MagicMock()
class ProductionTest(TestCase):
def test_target_method(self):
from sd import Production
assert Production().target_method(5) == 25
def test_failfunc(self):
# 対象のモジュールを読み込む前にパッチを当てる
with patch('failfunc.fail_func', return_value='success'):
from sd import Production
assert Production().get_failfunc() == 'successful.'
def test_failfunc2(self):
# テスト対象インスタンスの特定メソッドにパッチを当てる
from sd import Production
instance = Production()
with patch.object(instance, 'abc', return_value='abc'):
assert instance.failfunc_in_production() == 'abcdef'
3つめは、対象クラスのインスタンスを作成してテストしたい挙動に変えるときに使うパターンです。 テストケースに応じて例外を返すこともできるので、詳細はモックのドキュメントを参照してください。
モジュールのスナップショット
通常、Pythonのモジュールには内部状態を持たせてはいけません。 Pythonでは、一度読み込んだモジュールはメモリ上に格納され、2回め以降はメモリ上のモジュールを利用します。 もしもモジュール内でキャッシュなど内部状態を持つ実装があった場合、該当モジュールの読み込みが初回か2回め以降かで挙動が変わってしまうことになります。
モノタロウのシステムの自作モジュールには、残念ながら内部状態を持つモジュールが多くあります。 内部状態を持つモジュールを含めたユニットテストは難しいことから、モノタロウではモジュールのスナップショットの仕組みを作ることにしました。 ユニットテストで各ファイルのテスト実行時点にあるメモリ上のモジュールを退避し、テスト終了時にはテスト実行中に変更されたメモリ上のモジュールを破棄して退避していたモジュールに戻す仕組みを作成しました。
おわりに
第1回は、Python製の大規模なレガシーシステムを組織的に安全かつ継続して開発していけるように、複雑なコードを特定してリファクタリングを進めてきた事例を紹介しました。 技術面についてはどうしてもPythonの話題になってしまいますが、組織的な取り組みについてはPythonに関係なく参考になる現場も多々あるのではないかと思います。