こんにちは、データ基盤グループの吉本と吉田(id:syou6162)です。モノタロウでは基本的にはBigQueryを定額料金で利用していますが、利用者の多い時間帯はFlex Slotsも併用しています。本エントリでは、Flex Slotsの適切なスロット数を定量的に決めるために行なった試行錯誤について紹介します。
モノタロウでのBigQueryの利用状況
モノタロウでは様々な意思決定の場面でデータ活用が行なわれており、その中心的な役割を担っているのがBigQueryです。非常に多くのクエリが日々実行されるため、基本的にはBigQueryは定額料金で利用しています。データの総スキャン量も非常に大きくなるため、定額で安心して使えることは管理者視点からも利用者視点からも重要です。しかし、定額料金は割り当てられるスロット数が一定のため、利用する人数が多くなる業務時間中はクエリの処理時間が長くなりがちという課題がありました*1。
そこで、モノタロウでは追加でスロットを購入できるFlex Slotsを併用しています*2。Flex Slotsはスロット数(100スロット単位)に対して秒単位での課金体系となっており、場面に応じて(業務時間内など)柔軟にスロットを買い増せます。
課題感
クエリの処理時間が長くなりがちな時間帯にFlex Slotsを買い増せば、問題は一見解決できそうです。しかし、Flex Slotsを効果的に使っていくためには以下の2つの課題がありました。
課題感1: 適切なFlex Slotsのスロット数をどう決めるか
「Flex Slotsで適当なスロット数を買い増せばそれで解決!」かというと、そんなことは全くありません。適切なスロット数を決定する必要があるからです。スロット数が足りていなければ適切なデータ活用を阻害してしまいますし、スロット数が多すぎると過剰なコストを払うことになってしまいます。
また、スロット要求数に対してスロット実割当てを増やしても、必ずしも全てのクエリが早くなるわけではないところがBigQueryのスロットスケジューリング*3の難しいところです*4。
課題感2: 過去の期間との実行時間は単純には比較できない
スロットの枯渇状況だけ見ていても、(分析者などの)クエリ実行者の視点に立った正確な状況把握は難しかったため、実際のクエリ実行時間を計測するアイディアが次に浮かびました*5。しかし、実行されるクエリの内容は日々変わっていくため、過去の期間との実行時間と単純には比較できないという課題がありました。
解決策
解決策1: 同一のクエリを定期的に動かし、実行時間をCloud Monitoringで計測
これまで挙げた課題感のうち課題感2の「過去の期間との実行時間は単純には比較できない」を解決するために、以下のことを実施することにしました。
- 組織内の各GCPプロジェクトにおいて、同一のクエリを一定間隔でBigQueryに投げて*6、実行時間を計測する
- 同一のクエリを実行するため、過去の期間との比較がしやすい
- 同一のクエリを実行するため、どのプロジェクトでクエリが遅くなっているか把握しやすい
- 各プロジェクト毎のクエリ実行時間を1つのプロジェクトのCloud Monitoringに集約する
- 状況を一元的に把握するためにCloud Monitoringのカスタム指標に計測結果を投稿する
- ダッシュボードで計測結果を簡単に閲覧でき、アラートの設定も容易であるため
計測のために以下のPythonのスクリプトを作成しました。計測用のクエリ自体がスロットを必要以上に消費しすぎないように、クエリを実行するプロジェクトをサンプリングするなどの工夫をしています。
クエリの実行時間をCloud Monitoringのカスタム指標に投稿するスクリプト
import argparse import concurrent import datetime import time from google.cloud import bigquery from google.cloud import monitoring_v3 TIMEOUT = 180.0 class MetricsSender(): """メトリクスを送信する""" def __init__(self, client, series, monitoring_project): """インスタンス変数の設定""" self.client = client self.series = series self.monitoring_project = monitoring_project def send_metrics(self, monitored_project: str, job_execution_time: float): """BigQueryのジョブ実行時間をCloud Monitoringに送信する""" self.series.metric.labels["monitored_project_id"] = monitored_project now: datetime = time.time() now_seconds: int = int(now) interval = monitoring_v3.TimeInterval( {"end_time": {"seconds": now_seconds}} ) point = monitoring_v3.Point( { "interval": interval, "value": {"double_value": job_execution_time} } ) self.series.points = [point] self.client.create_time_series( request={"name": f"projects/{self.monitoring_project}", "time_series": [self.series]}) class JobMonitor(): """ジョブの実行時間をモニタリング""" def __init__(self, query: str, timeout: float, bigquery_client: bigquery.Client): """インスタンス変数の設定""" self.query: str = query self.timeout: float = timeout self.bigquery_client: bigquery.Client = bigquery_client def measure_bigquery_execution_time(self, monitored_project: str) -> float: """BigQueryのジョブ実行時間を計測する""" try: query_job = self._execute_query(monitored_project) except concurrent.futures.TimeoutError: return self.timeout else: execution_time = query_job.ended - query_job.started return execution_time.total_seconds() def _execute_query(self, monitored_project: str) -> bigquery.QueryJob: job_config = bigquery.QueryJobConfig(use_query_cache=False) query_job: bigquery.job.QueryJob = \ self.bigquery_client.query(self.query, project=monitored_project, job_config=job_config) try: query_job.result(timeout=self.timeout) except concurrent.futures.TimeoutError: raise else: return query_job finally: self.bigquery_client.cancel_job(query_job.job_id, project=monitored_project, location="US") def load_monitored_project_list(query_file_to_load_monitored_project: str, bigquery_client: bigquery.Client) \ -> bigquery.table.RowIterator: try: with open(query_file_to_load_monitored_project, 'r', encoding='utf-8') as f: query_to_load_monitored_project = f.read() except Exception as e: raise e return bigquery_client.query(query_to_load_monitored_project).result() def main( query_for_monitoring: str, query_file_to_load_monitored_project: str, monitoring_project: str, custom_metrics_name_job_execution_time: str, ): bigquery_client: bigquery.Client = bigquery.Client() monitored_projects: bigquery.table.RowIterator = \ load_monitored_project_list(query_file_to_load_monitored_project, bigquery_client) job_monitor: JobMonitor = JobMonitor(query_for_monitoring, TIMEOUT, bigquery_client) metrics_client = monitoring_v3.MetricServiceClient() metrics_series = monitoring_v3.TimeSeries() metrics_series.metric.type = \ f"custom.googleapis.com/{custom_metrics_name_job_execution_time}" metrics_series.resource.type = "global" metrics_sender: MetricsSender = MetricsSender(metrics_client, metrics_series, monitoring_project) for monitored_project in monitored_projects: bigquery_execution_time: float = \ job_monitor.measure_bigquery_execution_time( monitored_project["name"]) metrics_sender.send_metrics(monitored_project["name"], bigquery_execution_time) if __name__ == "__main__": parser = argparse.ArgumentParser() parser.add_argument( "--query_for_monitoring", help="実行時間を計測されるクエリ", ) parser.add_argument( "--query_file_to_load_monitored_project", help="BQジョブ監視対象となるGCPプロジェクト抽出クエリのファイル" ) parser.add_argument( "--monitoring_project", help="BQジョブ監視を管理するGCP Project_id", ) parser.add_argument( "--custom_metrics_name_job_execution_time", help="クエリの実行時間を記録するCloud Monitoring Metricsのカスタムメトリック名", ) args = parser.parse_args() main( query_for_monitoring=args.query_for_monitoring, query_file_to_load_monitored_project=args.query_file_to_load_monitored_project, monitoring_project=args.monitoring_project, custom_metrics_name_job_execution_time=args.custom_metrics_name_job_execution_time, )
カスタム指標の定義はTerraformで行なっています。メトリック投稿より先にカスタム指標の定義を行なっておく必要がある点は注意です。
カスタム指標の定義
resource "google_monitoring_metric_descriptor" "bigquery_execution_time" { description = "BigQueryのクエリの実行時間を計測します" display_name = "bigquery_execution_time" type = "custom.googleapis.com/bigquery_execution_time" metric_kind = "GAUGE" value_type = "DOUBLE" labels { key = "monitored_project_id" value_type = "STRING" description = "監視対象のプロジェクト" } }
これにより、同一条件に整えられた状態でクエリの実行時間を比較できます。
解決策2: 計測用オンデマンドのGCPプロジェクトでもクエリを実行し、理想状態との相対実行時間を知る
「クエリの実行時間はどれくらいであるべきか」、つまり「スロット数をどれくらい買い増せばよいか」という課題感1がまだ残っています。クエリ実行者としては早ければ早いほどよいですし、予算承認者としてはコストは低ければ低いほどよい、というトレードオフの関係が存在します。
これを両者で定量的に議論できるように、(仮想的な)理想状態におけるクエリ実行時間と比較することにしました。具体的には以下のことを行ないました。
- 計測専用のオンデマンドのGCPプロジェクトを用意し、解決策1で挙げたものと同様にクエリの実行時間を計測する
- 計測専用のプロジェクトであり、2000スロットを専有して使えます
- これを仮想的な理想状態と仮定します
- 経験的にはこの条件であれば快適に分析できることが多かったため、この仮定を置いています
- 定額料金のプロジェクトでかかっているクエリ実行時間とオンデマンドのプロジェクトでかかっているクエリ実行時間の比を取る
- 理想状態との実行時間を比の形で知ることができる
Cloud MonitoringのMonitoring Query Languageを使うと、実行時間の比を以下のように簡単に計算できます。
{ fetch global::custom.googleapis.com/bigquery_execution_time
| align mean_aligner(180m)
| max
; fetch
global::custom.googleapis.com/bigquery_ondemand_execution_time
| align mean_aligner(180m)
| max }
| join
| div
以下が具体的なグラフです。時間帯によって、実行時間の比が大きく変動していることが分かります。
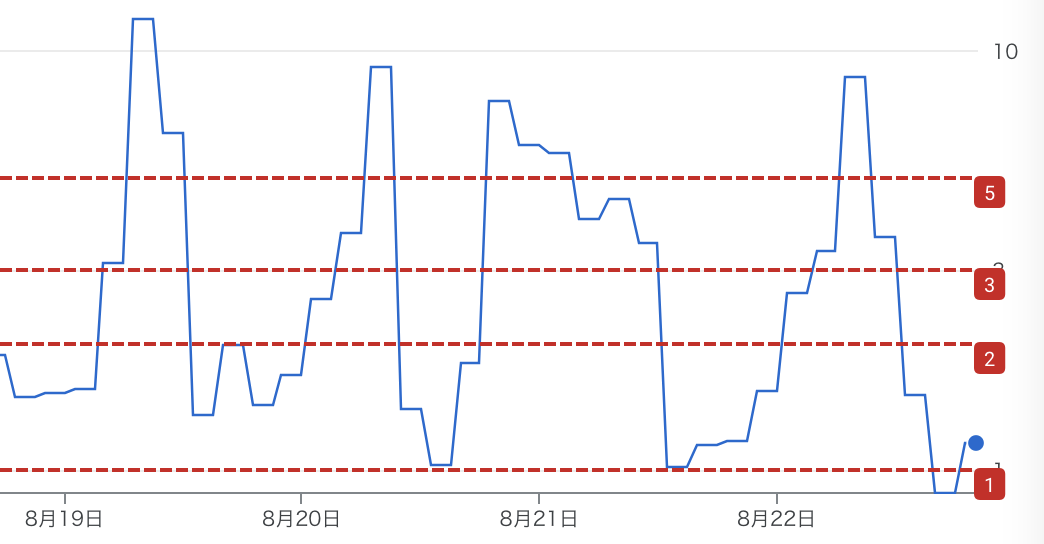
こういったグラフによって、クエリ実行者と予算承認者が以下のようにある程度定量的に議論できます(基準となる数値はあくまで例です)。
- 特定時間において、理想状態の10倍もクエリ実行時間がかかっており、分析者のuser experienceや生産性が落ちている
- せめて3倍以内になるまでスロットを買い増すべきだ
- クエリ実行時間が理想状態の2倍以内で済んでいる
- 理想状態よりは遅いが、コストの問題もあるので妥協して欲しい
細かいスロット数の調整はまだこれからですが、適切なスロット数を決定するための土台は整備できたかなと思っています。
まとめ
スロット数をいくつにすべきかという悩ましい問題に対して、分析者や予算承認者の視点に立ちつつ意思決定するためのモノタロウのデータ基盤チームでの試行錯誤について紹介しました。
モノタロウは日々意思決定を行なっているデータドリブンな会社であり、データ基盤グループに期待される役割も大きくなっています。コストを適切にコントロールしつつ、分析者に快適な分析環境を提供することに興味を持つ方のご応募をお待ちしております。
*1:後述で補足しますが、重いバッチクエリは別のオンデマンドのGCPプロジェクトで実行していることも多く、今回対象としているクエリはインタラクティブな分析用のクエリを想定しています
*2:定期バッチのような総スキャン量が概算しやすく、他のクエリの実行状況に影響されたくない重要なクエリなどは例外的にオンデマンド料金でBigQueryを利用しています
*4:詳細についてはGoogle CloudのCustomer Enginnerの方が書かれたGoogle Cloudではじめる実践データエンジニアリング入門を読むのがオススメです
*5:INFORMATION_SCHEMA.JOBS_BY_ORGANIZATIONを使うなどの方法があります
*6:バッチの実行にはGKE上のArgo Workflowsを利用しています