こんにちは、マーケティング部門広告グループの小林です。この記事ではオンライン広告運用に使っているデータ変換処理をdbtに移行した過程と得られた効果についてご紹介します。
モノタロウでは、全社的なデータ活用研修などにより、マーケティングのようなビジネス系の部署でも、SQLを自身で書いてデータ抽出を行い、数字に基づいた意思決定を行っています。その一方で、集計後の数値のズレやドメイン固有のデータの品質管理など、活用が進んだ企業ならではの課題というのも表面化してくるようになってきました。
オンライン広告運用においては、投下した費用など配信実績のレポーティング、広告媒体へのデータ送信などのいわゆるELTを安定的に回す仕組みが必要になりますが、処理の自動化やデータの品質まで求められるようになると、「データが抽出できる」だけでは限界が見えてきていました。そこで今回、マーケター自身がデータを管理する立場になれるように、ビジネス側の広告運用チームにデータ変換ツールdbtを導入するプロジェクトを立ち上げました。
広告運用チームの業務内容とデータパイプライン
なぜdbtを選択したかをご説明する前に、バックグラウンドとして当社の広告運用チームの業務内容や広告主が必要とするデータパイプラインとはどういったものなのかについてご紹介します。
モノタロウでは、新規顧客獲得の経路として検索エンジン上に配信する広告に注力しているため、年間数十億の費用を投下する日本有数の検索エンジン広告主となっています。もう1つの特徴としては取扱い点数が1900万点と膨大なため、商品を訴求するための広告のバリエーションも多くなっており、EC業界特有の巨大な広告アカウントを運用しています。
また、当社の広告運用チームはインハウス運用(代理店にオペレーションを任せず自社で運用すること)の体制を取っています。そのため、日々のオペレーションとしての予算管理だけでなく、広告の費用対効果を改善するために必要な分析用のデータなども全てBigQueryに格納し、BigQuery上でSQLを書いてオペレーションを回しています。加えて高度なSQLが書ける一部のメンバーについては、複雑なデータ変換処理(複数の広告媒体からの配信実績レポートを1つのテーブルにまとめる、広告媒体に送信するデータを複数のデータソースから加工するなど)の作成も行っています。
一方で、そうしたデータ加工処理を動かすスケジューラー・インフラの知識は十分になかったので、数年前からマーケティング領域を管轄するエンジニアチームと定常的に連携し、Argoを主要なインフラ環境としてデータパイプラインを運用しています。
そのパイプラインを流れる広告データには大きく分けて2種類あります。
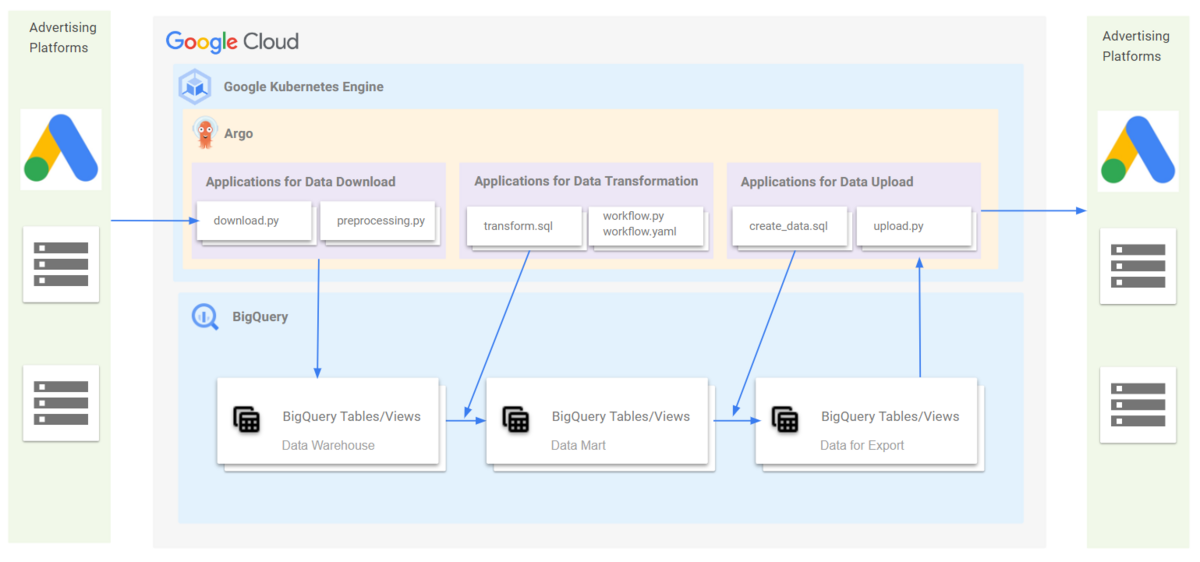
個々のアプリケーション内でデータ変換処理も行っていました。
1つはオペレーションのためのデータです。例えば、Google検索などで表示される商品画像つきの広告(ショッピング広告)を配信するためには、毎日最新の商品情報を広告媒体に送信する必要があります。商品情報を正しく送信できないと、広告とサイト上で商品価格が異なってしまったり、販売が終了した商品を広告として掲載してしまったりするので鮮度と正確性が求められます。
もう1つは分析のためのデータです。日々消化した広告費用だけでなく、新しく作成した広告文は効果があったのか、広告をクリックして流入したユーザーは実際に商品購入や新規登録まで辿り着けたのかなどの発展的な分析は、当社のような巨大なアカウントでは各種ツールの管理画面からでは全体状況を把握することが困難なため、広告APIから取得したデータをBigQueryに格納し加工した上で分析する必要がありました。
過去数年間は、データの送受信はエンジニアチームが担当、データマートの作成やデータ分析は広告運用チームが担当、という役割分担に基づいてオペレーションの運用・拡大を行っていましたが、直近では以下のように、主に3つの課題があることが分かってきました。
見えてきた課題
課題1:扱うデータ量が加速度的に増えてきた
これは広告費や商品点数、配信する広告メディアが、事業の成長と連動して増えてきたことも一因ですが、競争が激しくなる広告業界において競争優位を保っていくために、データ分析に求められるレベルが上がってきたことも原因でした。
分析できるデータがまだBigQueryにあまりなかった時代は、メディア(Google広告、Yahoo広告など)ごとに費用対効果を平準化させる程度でしたが、最近では事務用品カテゴリで販売している商品は新規顧客の獲得にどう貢献できているのかといったカテゴリ単位の分析や、「軍手」という広告キーワードから遷移するページは広告掲載を強化すべきか、等より細かな分析が必要になってきました。
そうした要求を達成するためには、これまでBigQuery上に格納していなかった新しい広告レポートを取得する必要がありますが、結果として管理するデータが増え続けていくことになりました。
当初はエンジニアチームに取得してもらったデータをviewで一部加工を行いつつ、特定のデータセットに集約して分析しやすい状態にしていましたが、やがてエンジニアが大量のレポート取得用バッチ作成の工数を確保できなかったり、データが増えすぎたことでデータパイプラインのメンテナンスが追いつかなくなり、いつの間にか元データやviewが壊れていたりするなど、品質や作業完了までのリードタイムが悪化していく状態になっていきました。
また、広告媒体APIから取得できるデータ自体にもカラムの増減や値の変更などの仕様変更が想定よりも多く、データ加工関連の処理を定期的に改修・リリースする工数も必要であることが運用を始めて徐々に分かってきました。
課題2:ドキュメントが不足していて利用者が欲しいデータに辿り着けない
データの種類が増えた結果、利用者がデータを理解する認知負荷も上がってしまいました。スプレッドシートやLooker Studioで管理対象のテーブル一覧を用意したりなど簡易的な仕組みを使った取り組みは続けていましたが、一覧表自体も都度メンテナンスが求められ検索性もあまり良くないなど要求を満たせておらず、普及が進まない状態になっていました。
メンバー向けにデータ利用の課題についてヒアリングを行うと、キャリアが長いメンバーはデータ整備が追いついていないことを指摘する一方で、ジュニアメンバーはドキュメントの情報が少ないため欲しいデータを見つけることが難しくなっていると感じており、メンバー間の情報格差も広がってきていました。
課題3:ELTがアプリケーション内で混在することによるエンジニアの負担増
ELT処理は一度作って終わりではなく、エラー発生時のリカバリやバグ修正などの定常運用に加えて、ABテストの実施などビジネス目的での改修も頻繁に発生します。
このとき問題となったのは、SQLを含むデータ加工の処理を各アプリケーション内に配置していたため、BigQuery上でのデータ変換処理が少し変わるだけであっても、エンジニアによるレビューとデプロイが必要になり、希少なエンジニアリソースをさらに逼迫させていました。
結果として、エンジニアチームは定常運用とビジネス側から依頼される小規模改修に追われ、バックログに重要だが工数の大きいタスクが数か月待ちの状態で積みあがっていく事態になっていました。
dbtの導入に至るまで
こうした課題は広告配信に深刻なトラブルこそ引き起こしていませんでしたが、現状の仕組みでは維持が精一杯ということが分かってきたので、マーケティング領域管轄のエンジニアリングマネージャーと相談の結果、以下の方針で改善を進めることになりました。
ELTでの役割を明確に分担する
ELTの設計思想そのものではありますが、各アプリケーション内でデータ変換処理(Transform)は行わず、全ての変換処理はBigQuery上で広告運用チームが専任で行うことにしました。すなわち、広告側からデータを受信するバッチは受け取ったrawデータをそのままロード、送信する場合は加工済のデータを呼び出すだけになります。この方式を採用することで、アプリケーション内にELTが混在する問題が解消され、マーケティング側のメンバーはエンジニアのサポートなしでデータ変換処理の改修ができるようになると考えました。
データ変換処理をマーケティング側のメンバーのみで管理できるような仕組みを用意する
一方で、マーケティング側に役割の移譲を行うためには、SQLのバージョン管理、スケジューラーなどの安定した運用を行うためのインフラが必要になります。なお、SQL以外のコーディングが中心になると学習コストが高くなってしまう為、KubernetesがベースのArgo WorkflowやPythonでのコーディングが必要なAirflowなどは使わないことを前提としました。
これらの制約を元にソリューションを検討した結果、マーケティング側で導入するツールの第1候補となったのがdbtでした。
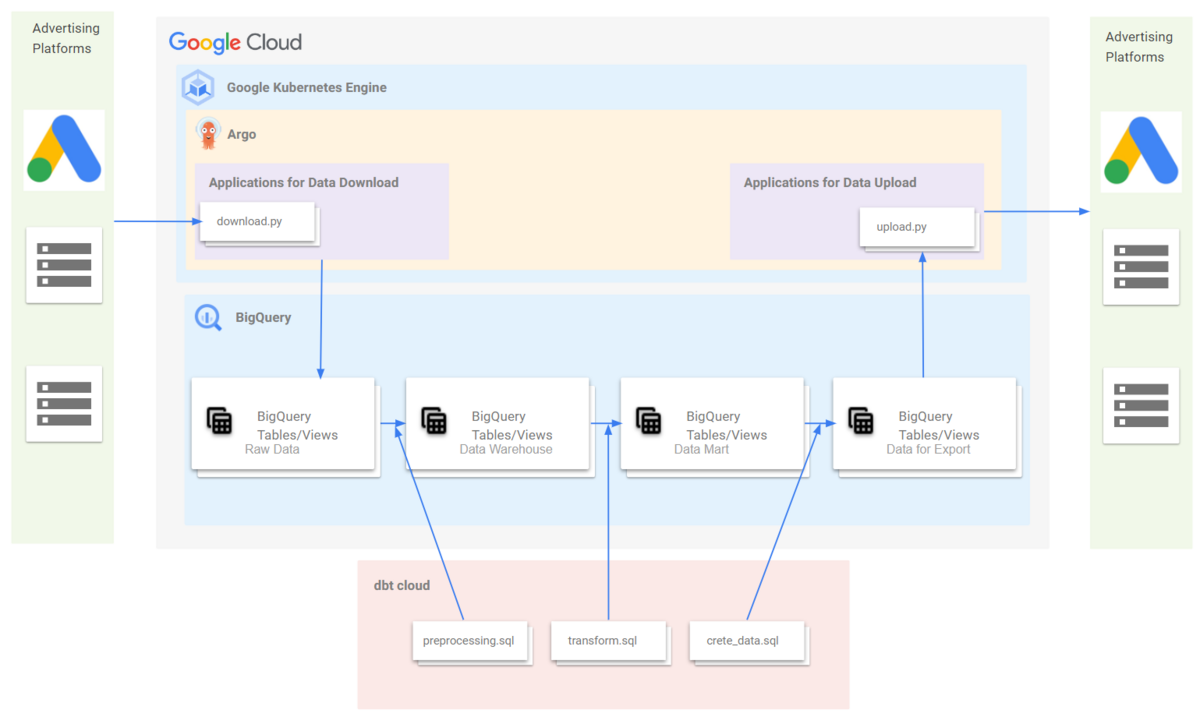
データ変換処理は全てdbtに移行させ、各アプリケーションはデータを加工なしに転送するだけにしました。
dbtを選択した理由
dbtはここ数年で急速に広まっているSQLをベースとしたデータ変換処理のためのツールです。BigQueryなどのデータウェアハウス内での処理に対してソフトウェア開発のようなテストやバージョン管理ができるなど、SQLが苦手とする領域をカバーすることができます。そのほかにもデータ依存関係の可視化や自動ドキュメント作成などの機能もあることが特徴です。
なおdbtにはCLIから操作するOSS版のdbt coreとIDEやスケジューラーが用意されたSaaS製品のdbt cloudがありますが、今回は非エンジニアが使う前提だったのでインフラも付いているdbt cloudを利用することに決めました。
dbt cloudのPoCにあたっては、OSS版の利用経験があるデータエンジニアや、マーケティング領域担当のエンジニアと共同で行いましたが、SQL以外にはgitとpythonに関して基礎的な知識さえあれば良いことが分かったのも導入の決め手でした。
広告運用チームは元々エンジニアとして入社した人はゼロですが、データサイエンティストなどエンジニアリングスキルが高いチームと距離が近い組織だったため、メンバーの過半数はgitとpythonの使用経験があり、いわゆるAnalytics Engineerとしての基礎スキルはある状態だったので、dbtの学習コストはほぼないと判断しました
(注:類似製品のDataformは検討していた当時はクローズ状態だったため、検討対象から外しました。今後のアップデート次第で改めて検討する可能性はあります。)
dbtの導入によって得られた効果
まだ過渡期ではありますが、現時点で既に導入前の課題を解決できたと感じられた点についていくつか紹介します。
効果1:リリース工数を大幅削減できた
これまでは広告チームで運用していたデータ分析用のviewなどは、自動的にリリースする仕組みを用意していなかったため、bqコマンドやGUIでの操作など手動での作業が必要になっていました。
しかし、dbt cloud導入後は以下のコマンドを含むjobを実行して成功を確認するだけになりました。
dbt build state: modified+
state:modified+を含むこのコマンドは、レポジトリ内で変更があったファイル及び、そのファイルに依存する後続処理のみ実行・テストしてくれるコマンドになります。マージ済みの最新のmasterブランチと、早朝に取得しておいたmasterブランチの差分のみ実行するようにdbt cloud側で設定しておくことで、リリース作業の負荷を極限まで減らすことができました。
効果2:リリース前~運用開始後の品質が明確に向上
dbt導入以前も重要なSQLはプルリクエストを作成してレビューを挟むルールを用意していましたが、全てをテストすることが難しいと感じていた領域でした。コードを読んで正しさに自信がなければ、最終出力結果に対してuniquenessを確認するためのクエリを書いてみたり、ビジネスKPIと比較して妥当な集計結果かを逆算したりということはしていましたが、それでも本番環境にリリースしてからチェックが漏れていた箇所にバグが見つかったり、後続の処理で想定外のエラーを引き起こしたりということはなかなか減らせていない状況でした。
この課題もdbt導入後に劇的に改善しました。dbtではuniquenessやnot nullなどのテストをyamlファイルに定義し、dbt testコマンドとして実行することができます。そのため、事前に変更箇所と後続処理に対してテストコマンドを実行し、その結果をプルリクエストに記載しておくことで、テストにパスしたという証拠が残せるため、SQLを頭から解読せずともプルリクエストのレビューを素早く行えるようになりました。
その他にも、インプットとなるデータに信頼性がない場合は外れ値検知のテストコードを書いておくことで、リリース後のdailyのテストからデータに異常があることにすぐ気付けるようになりました。
効果3:ドキュメンテーションの品質が向上
最後はdbtの自動ドキュメント作成機能です。個々のテーブルやviewの情報だけでなく、データ間の依存関係、さらにはexposuresと呼ばれる機能を使って出力した結果がダッシュボードやエンジニアチームのバッチ等、どこでどのように使われているかも記録できるなど、これまでに使っていたドキュメントに比べて大幅に多機能なためdbtのカバレッジ拡大に伴い既存のドキュメントはほぼ全て置き換える予定です。
exposures: - name: batch_sending_XXX_to_XXX_ads type: application maturity: high url: https://{repository_link} description: "XXX送信用のバッチ" depends_on: - ref("export_XXX__prod__XXX") - ref("seed_XXX__prod__account_id_list") owner: name: Marketing Engineering Team email: {email}
今後の展望
dbtは利用しているチームのデータ活用における生産性を上げるのはもちろんのこと、他のチームにも良い影響を与えられるのではないかと期待しています。
データ分析の業務は往々にして未知のドメインに飛び込み、定義さえ分からないデータと格闘することから始めないといけないことがあります。特にオンライン広告というドメインは、プロダクトのドメイン外での活動が中心になり、周囲から見ると未知のKPIに囲まれた、孤立していてコラボレーションが生まれにくいチームになってしまいがちなので、dbtでのドキュメンテーションによるデータの可視化を通じて、チームをまたいだデータ活用を推進できるような環境作りをさらに進めていきたいと考えています。
また、dbtの移行がさらに進んできたときに出てくる以下のような検討事項
- dbt cloud APIを使って、外部のスケジューラーから重要なjobの実行状態を管理できるか
- 複数チームがdbtを使い始めたときにrepositoryをどう管理していくか
などについてもいずれ紹介できればと思っています。
最後に
今回紹介したAnalytics Engineeringのプロジェクトは広告運用チームの業務のごく一部です。サイト上の広告に関連する行動データの計測方法をエンジニアと一緒に考えたり、他チームのKPIと集計定義を統一していくなど、データ活用の分野だけでもたくさんのプロジェクトが動いています。
また、広告チームの分析スペシャリストはビジネスとの距離が非常に近いポジションです。データを整備するだけでなく、データ分析から得られたインサイトをオペレーションに反映し、ビジネス成果を創出してみたいメンバーを募集しています。
本記事のデータ活用の内容に加えて、マーケティングドメインでのデータ分析に興味のある方はぜひカジュアル面談でお話できたらと思います。また、当社マネージャー陣のマーケティング領域に関するインタビューも是非ご覧ください。