おしらせ:12/23 に後編記事がでました!
こんにちは、データ基盤グループの香川です。
現在モノタロウではBigQueryに社内のデータを集約し、データ基盤を構築しています。 およそ全従業員の6割が日々データ基盤を利用しており、利用方法や目的は多岐に渡ります。 データ基盤グループはこれまでデータ基盤システムの開発保守と利用者のサポートを主な業務として取り組んできましたが、これら多岐にわたる社内のデータ利用における課題の解決及びさらなるデータ活用の高度化を目的として、今年の5月よりデータ管理を専門に行う組織として新たに体制を再構築しました。
そこで改めて組織として取り組むべき課題や方向性を決めるために、まず自分たちの現在地を知ることが重要と考え、データ基盤の歴史を振り返り、社内のデータ活用における課題やそれを取り巻く状況がどう変わってきたのかをまとめることにしました。最終的に、これらの歴史の振り返りはスライドにまとめて社内で発表することにしました。
本記事はこの発表の内容を文字に起こしたものになります。 かなりボリュームもあるため、前半後半と分けてお伝えします。前半となる今回は、モノタロウが現在のBigQueryによるデータ基盤を作るまでの変遷について紹介します。
- データ基盤の変遷の概要
- 2010年頃のデータ基盤
- 販促基盤とDWH(2010~2015)
- データ基盤構想とBigQueryの導入(2015~2017年)
- 同期システムの改良とBigQueryデータ基盤の展開(2018)
- 最後に
語り手 データ基盤グループマネージャー:香川

データ基盤の変遷の概要
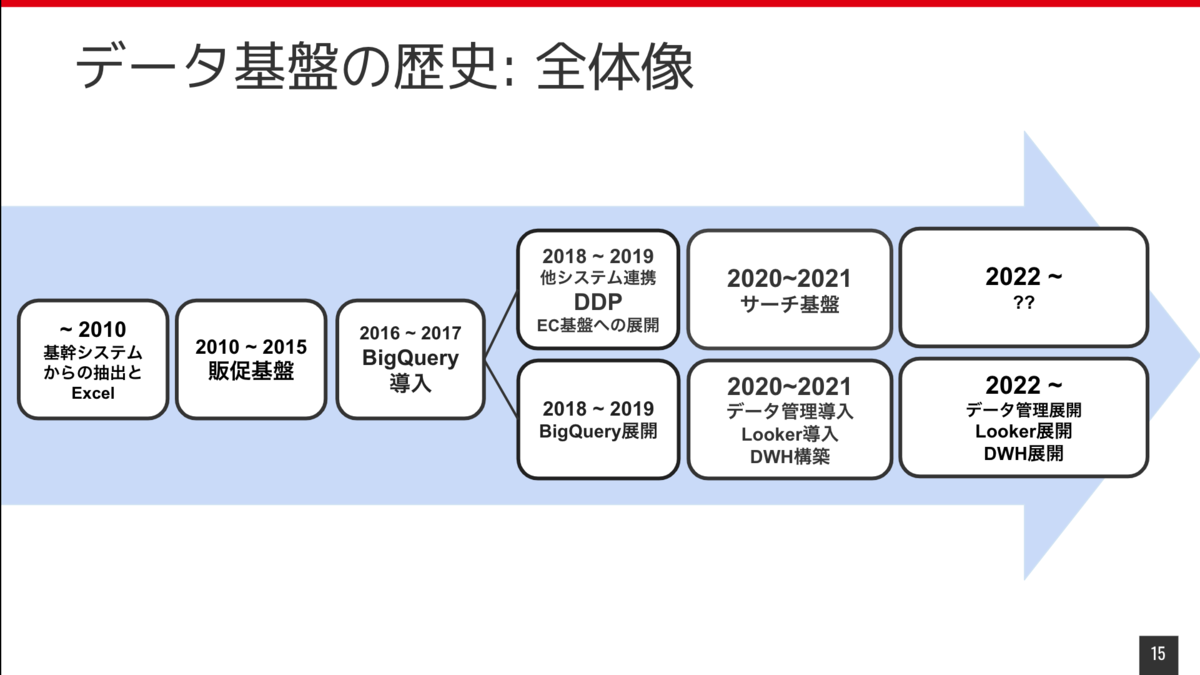
今日はデータ基盤の歴史とこれからについてお話をしようと思っております。
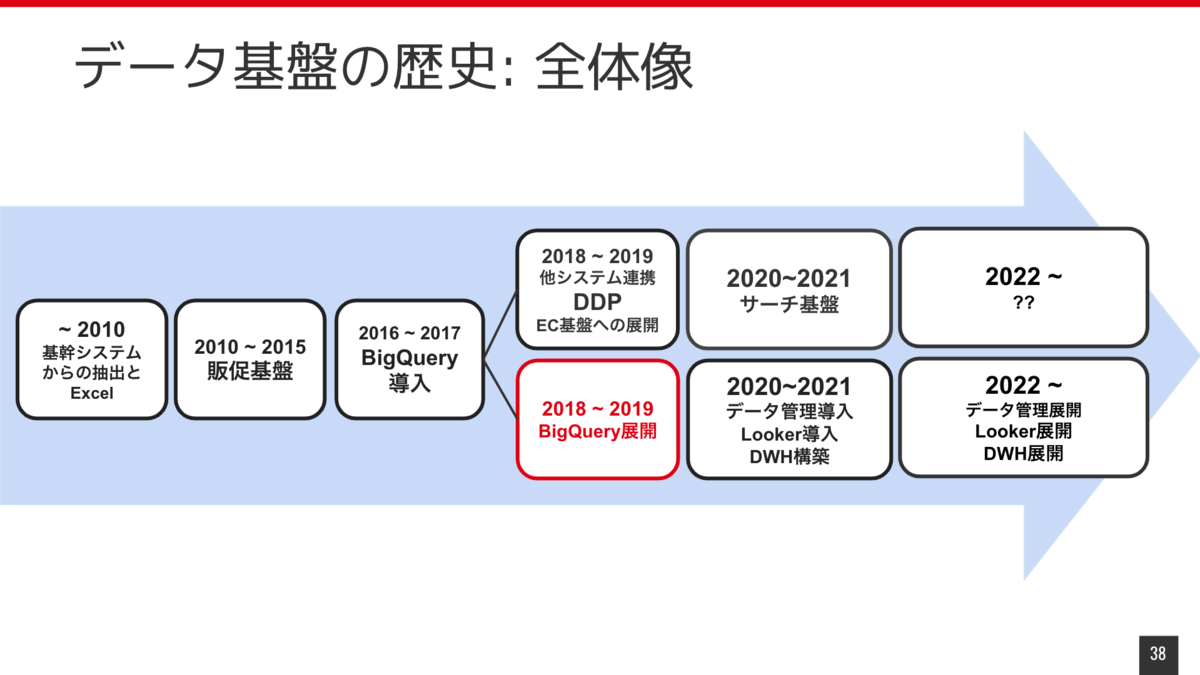
データ基盤の歴史の全体像を先にお見せします。
まず2010年以前です。私は 2016年入社なので在籍していないため、推測も混じっていますが、基幹システムとExcelを使ったデータ利用がほとんどだったのではないかと思っています。 2010年ぐらいから販促基盤が出来て、それを利用してデータ分析による高度なマーケティングができるようになりました。
そこから2016年ぐらいにBigQueryが導入されて、より全社にデータの活用がどんどん広がっていくようになりました。
ここからちょっと分岐があります。 上のラインがシステムでのデータ活用に関してで2018年ぐらいはデータ基盤上のデータをシステムへ提供するためにDDPって呼ばれてるような基盤作ったりしていました。 下のラインではBigQueryをデータ分析や利用の基盤としてどう活用するかについての部分で、 BigQueryの展開を行って、勉強会やったりとか、いろんな社内に展開するための取り組みをやっていました。
その後、2020年ぐらいからLookerの導入や、データ管理そのものをもっと積極的にやっていこうというところで今年に入ってからは新たにデータ管理のための組織を立ち上げて進めています。
次に各パートについて細かくお話をさせていただこうと思います。
2010年頃のデータ基盤
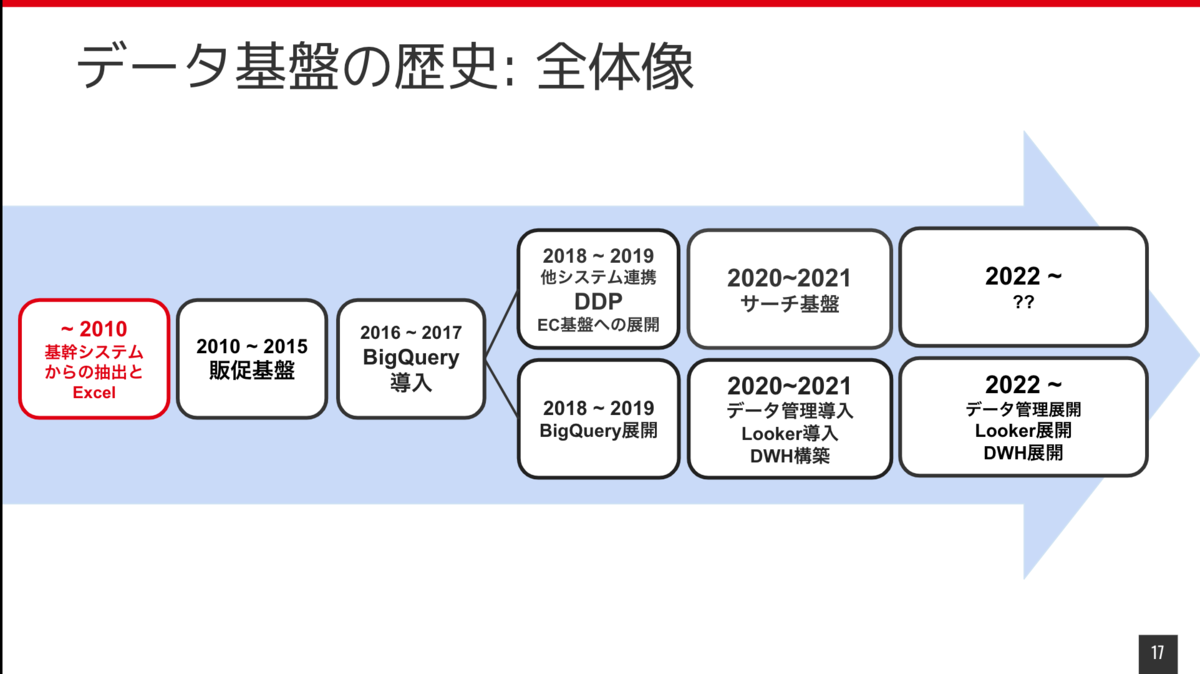

まず2010年以前です。 社内のシステムのデータのほとんどは MySQL にありますが、基幹システムの機能としてデータ抽出の機能を提供していないものについて、非エンジニアが分析などで利用したい場合はエンジニアに抽出依頼をしてデータを取得していました。 また業務で定常的に必要なデータでかつ基幹システムから取れないものは MS Accessで 直接MySQL から取得して、そのまま MS Access もしくは Excelで加工して利用するというようなことが行われてました。

この時代の課題は、基幹システムの機能で提供していないデータの取得は都度エンジニアに依頼が発生するという点です。コミュニケーションや作業コストも高く、自由にデータを利用できるという状態からはほど遠かったと思います。
また MS Accessでのデータの直接取得は統制管理の観点からもリスクが大きい状態だったと思っています。
販促基盤とDWH(2010~2015)


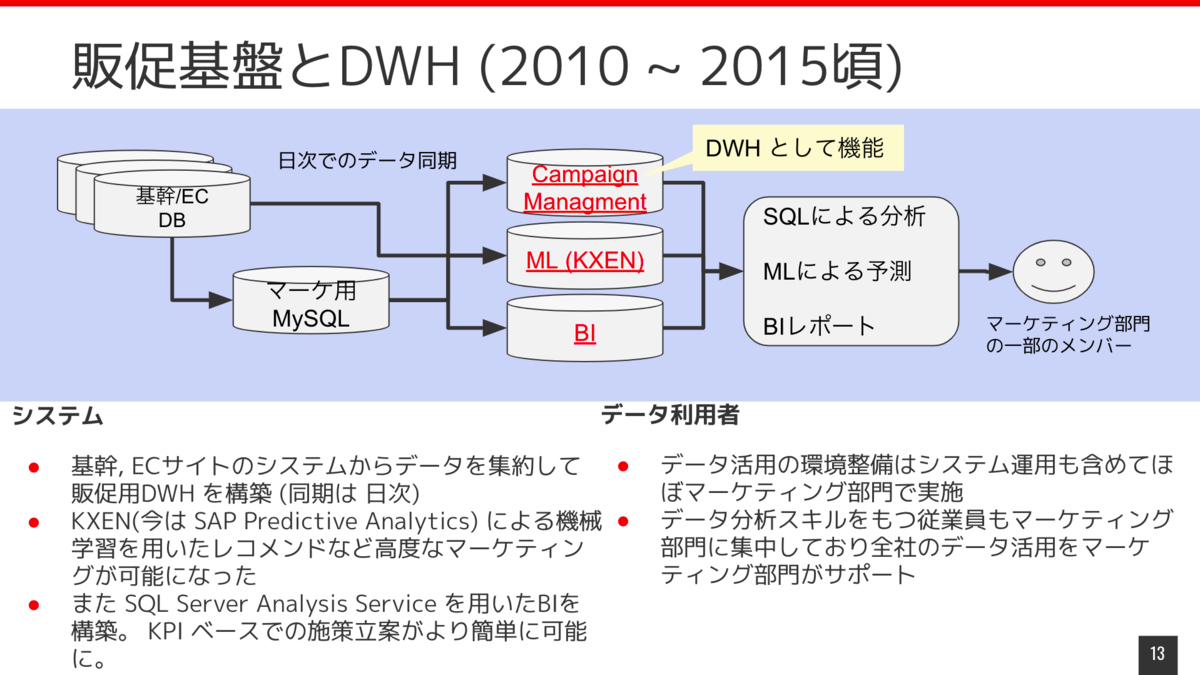
2010年ごろからデータを利用してマーケティングを行うための基盤として販促基盤ができました。
販促基盤では基幹システムやECサイトのデータベースのデータを日次で同期、集約して DWHを構築していました。 機械学習をするためのツールとしてKXEN(今は SAP Predictive Analytics)というものがあるんですが、DWHにあるデータを連携して学習と推論を行い様々なマーケティングの最適化をおこなっていました。 また当時販促基盤のデータベースとしてSQL Serverを利用していましたが、 SQL Server Analysis Services というものがあって、これ利用してBI を構築して提供していました。 これによってマーケティング部門以外のメンバーもKPIベースで施策立案したりできるようになってきました。
データの利用状況としては、データ分析スキルを持つ人材はほぼマーケティング部門に集中していて、全社のデータ活用をマーケティング部門がサポートするというような感じになっていました。

で、その後2015年ぐらいまでこの状態が継続します。 時間が経てば売り上げも上がりますし、トラフィックも上がりますし、扱うデータの量もどんどん増えていきます。ですが、システムそのものはそんなに拡張はされなかったんで、どんどんリソースは枯渇していき、サーバのハードウェア自体のメンテナンスなんかも課題として上がるようになってきました。 データの利用状況としても、データ分析スキルを持つ従業員は相変わらずマーケティング部門に集中しているという状態が継続してます。 他部門から利用者を募ればいいのではという指摘も過去にあったかと思うんですが、システムの状況や運用体制やサポート体制から、なかなか他のメンバーに広げていくのが困難になっていました。
いろいろ課題はありますが、別ホストにある複数のDBのデータを集約してDWHを構築したり、機械学習を利用して販促を行ったりと小規模でもDWH、 機械学習基盤、 BIが構築されたというのは成果としてかなり大きいものがありました。
この販促基盤を構築したことで、基盤を利用していたグループをはじめとして、マーケティング部門にSQLを使ってデータを利用する文化が醸成されたというのがあるのではないかと思います。 またBIによってマーケティング部門以外でもデータを見て意思決定できる環境が一定できたのが成果としてはあります。
私は2016年2月に入社して直後にこの販促基盤の運用担当になったので、販促基盤を利用しているグループの方と業務する機会は多かったんですが、非エンジニアなのにほとんどの方がSQL書けて、かなり驚いた記憶があります。 普通エンジニアじゃないとSQL書けないものだと思ってたんですけど、こんなみんな書けるんだっていう。
課題は先ほど少し言及しましたが、基本的にマシンリソースが枯渇していて、そのためにパフォーマンスのちょっとしたハックをするための実装がいろんなところで行われていて、そういったものが複雑性を招いて変更が困難になっていたり、現状の理解が難しかったりと運用コストが高くなっていました。 また変更が容易でないため、データの同期テーブルの追加も困難になって、提供できるデータも限定されていました。ユーザ管理も煩雑でスケールができない状態で、全社的なデータ活用基盤っていう観点ではまだまだ不十分でした。
データ基盤構想とBigQueryの導入(2015~2017年)

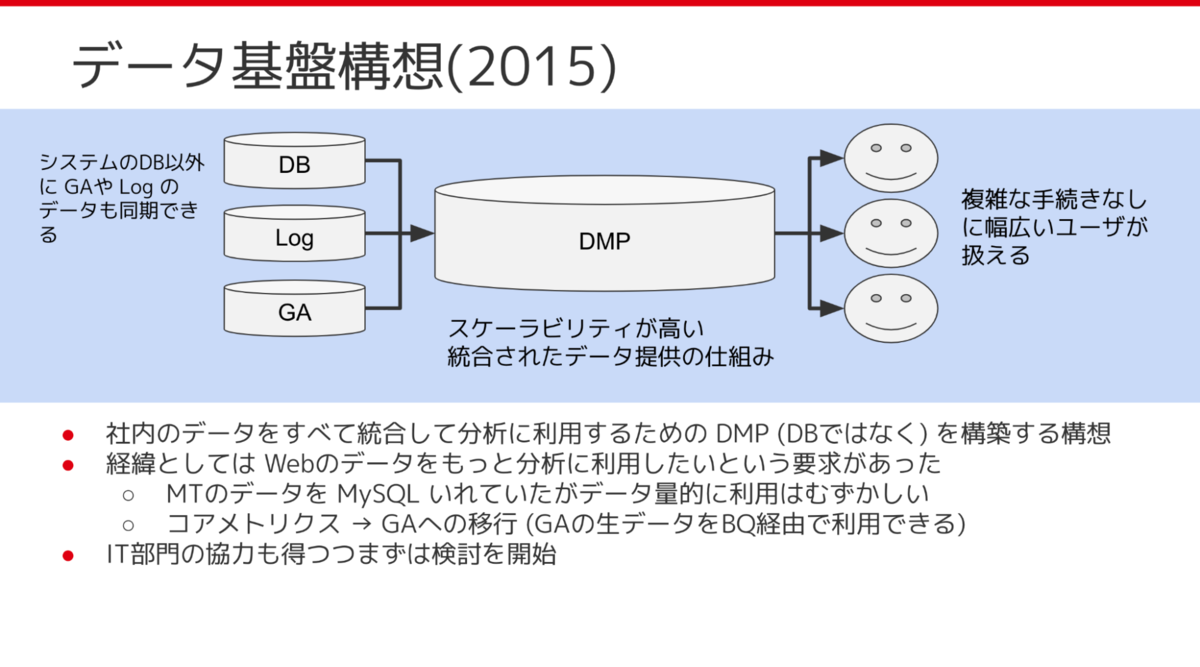
販促基盤であった課題を解決するため、2015年にデータ基盤構想を当時のデータ分析グループ内で企画しました。 背景としては Google Analytics (GA) や ECサイトのシステムで取得しているユーザ行動ログデータを既存の分析基盤上でももっと活かしたいというのがありました。当時 ECサイトで取得しているデータなんかは MySQL に入れてたんですが、データ量の問題もあり MySQL や 販促基盤のDB(SQL Server) 上では分析が難しくなっていました。 データ基盤構想の実現にむけてまずは、マーケティング部門のデータ分析グループ内で Treasure Data の検証と導入をすすめました。 BigQuery上に Export されたGAのデータや分析に必要なデータを Treasure Data に同期して分析を行うという形で、とりあえず一つの分析タスクがうまくできるか検証をすすめていたのですが、当時のTreasure Data の技術的な制約やそもそもGAのデータがBigQueryにあるのにわざわざ同期するという構成にも課題感があり、結局 BigQuery上にデータ基盤を構築しようということになりました。 ちょうどそのころ組織の再編がおこなわれ、マーケティング部門以外の部門でもデータの活用をすすめていこうということで、データ分析のスキルをもつメンバーが、別の部門に異動しデータ分析の業務を展開していきました。

データ基盤を構築するぞとなってから、まずどういうものを目指すのか、目標を決めたのですが、まずはあまり深い議論のないまま社内のデータを全部集めようとなりました。 社内にはMySQLで限定しても 2,000近くテーブルがあるためこれを全部集めるにはどうしたらよいか検討した結果、Change Data Capture という MySQLのバイナリログを利用する方法でトライしてみようとなりました。結果としては結構うまくいって、500テーブルぐらいを単一のシステムでニアリアルタイムに同期できるようになりました。
BigQueryのおかげで販促基盤の時代と比較して、圧倒的なスケーラビリティを得ることができて、利用ユーザも大幅に増やすことができました。

BigQueryを導入したことによってどういう成果が出たのかというと、販促基盤のころから比較すると扱えるデータ量としては約10倍、作成されたレポート数もだいたい10倍ぐらいと。SQLを使って何らかの業務でデータを活用するメンバーも、4倍の40人以上ぐらいになりました。
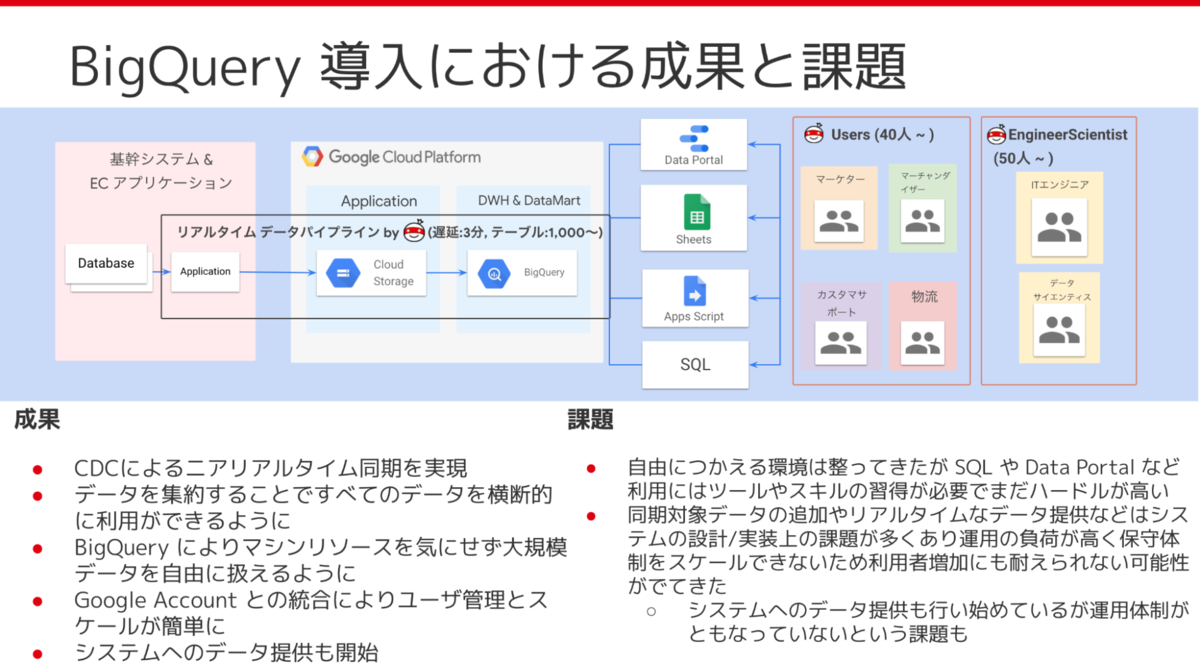
数字以外のところの成果と、課題についてもお話をしておきます。 まず成果について、一つは Change Data Capture でニアリアルタイムで同期でデータを集約することができるようになったことです。 社内の主要なデータのほとんどを横断的に、かつ鮮度の良いデータを利用できるようになったことで、分析以外の大規模データ処理基盤としての利用などにも展開されました。 またBigQueryは Googleアカウントと統合されてるので、ユーザ管理がとてもに簡単になって、それによっていろんな部署のかたに使ってもらえるようになりました。
課題としては、データを自由に使える環境は整ってきたんですけど、結局SQLとかData Portalの習得が難しく、全社展開にはちょっとハードルが高いかなというのがありました。 また実際作ってみると設計とか実装上の課題が結構見つかって、運用負荷が高くて保守体制がスケールしにくくなっていて、利用者の増加に今後ちょっと耐えていけないんじゃないかっていう可能性が出てきていました。 あとはさっき言及した大規模データ処理基盤としての利用です。このときBigQueryで行っていた処理はそこそこクリティカルの処理だったんですけど、運用体制が伴ってないところでも結構リスクを抱えていました。

一旦ここまでを振り返ってみます。 まずはデータ基盤構築の優先順位の部分です。 MonotaROではデータを活用する文化がマーケティング部門のメンバーを中心にかなり醸成されていて、かつ、SQLを書けるユーザがたくさんいたのが大きいポイントかなと思ってます。 そういう環境の中では、BIなどを高度に作り上げるよりかは、とにかく網羅性高くデータを集めて、またとにかく自由に利用できる環境を用意するのが結構重要だったんじゃないかなと思いました。
あとは、未来のボトルネックを解決するということです。 BigQueryへの同期方法として Change Data Capture でやってみようってなった理由の一つとして、同期するテーブルの追加のコストが高いというものがありました。同期の依頼があって、翌日または翌々日、あるいは週をまたいでデータを提供するという感じで、場合によっては依頼の翌日に別の依頼がきて、それでリリース予定のコードををいろいろ書き換えて、もう一回リリースのスケジュールし直してといったコミュニケーションが発生していました。 こういったオペレーションは新しいデータ基盤では不要にしようと思っていました。
CDCによる同期だと同じホストのバイナリログを全部同期しているので同期テーブルの追加に関してはかなりコスト低くできるようになっていました。そのため社内にデータ基盤が展開され利用者が増えても同期対象の追加に関してスムーズにできていました。 当時そこまで深く考えていたわけではないですが、基盤を作る上で現在のニーズに応えることより未来のボトルネックをちゃんと解決するという観点で基盤を設計していかないといけないなと思います。
同期システムの改良とBigQueryデータ基盤の展開(2018)

データ同期システム、ニアリアルタイムで同期するためのシステムなんですけど、いろんなスクリプトを集合したようなシステムになってしまってたので、いろんな処理を実行するのにいちいちコマンドを叩く必要があったり、手動の運用が多くなってました。またデータ品質担保のための仕組みも結構複雑になってて、運用コストが高い状態でした。 また、当時開発と運用を私が一人でやっていて、また販促基盤の運用やマネージャなどもやっていたので、どんどん属人化が加速していました。
結果として、チーム拡大時に属人化している部分の運用をうまく引き継げない問題が出てきてました。 あとは任意のタイミングのデータを生成できたりとかリアルタイムでテーブルを作ってそれを提供するようにしていたんですけど、それをやるには設計上BigQueryの費用がものすごくかかるようになってしまっていて、要するにポテンシャルを活かしきったデータ基盤にはなってなかったのが課題としてありました。

これら課題を解決するために、バイナリログを使って同期するアプローチはそのままに実装としては完全にリプレースしました。 v2では、suffixに _now が付いてるビューを通せば誰でもリアルタイムに同期されたテーブルを参照できるようになりました。これによって各種運用も自動化し、運用負荷が低くなりました。

この v2 の同期システムを作るのと並行してSlackの問い合わせチャネルを作るなどサポート体制も構築を進めました。
またデータ基盤グループで他部門の業務的なサポートもやるようになりました。 あとはスプレッドシートによるSQLのスケジュール実行ツールなどのツールを作って提供するというのをやりだしたのも2018年ぐらいですね。 さらに社内のユーザにBigQueryの説明会や勉強会を実施しました。ほかにも SQLの勉強会だったり Data Portalの勉強会も2018年に何度かやったりとか。それ以外にも社外のかたにお願いして講習をするかたちで、BigQueryやSQLの勉強会をすることもやってたりします。

MySQL以外のデータの同期にも取り組んでいて、WMSのデータや、検索エンジン用のデータ、ApacheとかNginxなどのWebサーバのログなども同期するようになりました。

このBigQueryの展開っていうところの成果と課題についてちょっと振り返っておきます。 成果としては、データ基盤について全社ミーティングで社長に言及していただいたりとか、そういうのがあって結構利用者が全社に広がって、200 ~ 250人ぐらいが何らかの手段でBigQueryを利用してるとい感じでした。
また、販促基盤のBIで作成したレポート10個ぐらいをいろんな部署と協力しながら全部Data Portalに移行することもやってたんですけど、これのおかげでいろんな部門でData Portalを使ってデータを可視化するということが浸透しました。あとはこれまでBigQuery側が日次の同期のデータしかないという状態だと基幹システムで取得したデータとBigQueryを一緒に利用するみたいなケースだと難しかったんですが、それがニアリアルタイムで同期ができることになって、そういった業務で利用するというケースも増えました。 データ基盤グループでもスプレッドシートと組み合わせてちょっとしたツールを作っていました。
その一方で課題として、スプレッドシートとGASの組み合わせ利用がすごい広がって、業務でのデータ活用が進む一方で MS Accessと同じようなちょっと統制がとりにくくなるという問題があったりします。
また同様に利用者と機会が増えたことで統制をとるのが難しくなったというのがあります。他の部門の方のサポートは当時もずっとやってたんですけど、このサポートにかかる工数がかなり大きくなっていて、他の業務の時間を圧迫するようになっていました。
こういった形でデータを全社に提供するって今まで当然やったことない取り組みなので、ルールも全然整備できてなくて、「こういった場合どうしたらいいですか」、「こういう人がこういうデータ欲しいって言ってるんですけどどうしたらいいですか」みたいな問い合わせがたくさんくるんですが、それを判断するためにの根拠になるようなポリシーやルールがやはり十分になくて、都度ボトムアップでここはこういう懸念があるからいい、駄目だ、みたいな議論をして決めていたのが大変でした。
他に利用者が増えることによってデータに対しての知識レベルも差がでてきて、データにアクセスはできるんですけど、「どのテーブルとどのテーブルをどうJOINしたら欲しいデータがとれるのか分かんないです」っていうような課題が増えてきました。
これに対してもサポート体制が追いつかず、データ基盤グループメンバーでもそもそもどういうデータがあるのかわからない、データそのものに対してのナレッジが集約できてないという課題がありました。 またいろんなデータソース拡充したので、システムの拡大に応じてその運用負荷がまた再び上がってきたというのがあります。

ここでまた一旦振り返りと学びを挟みます。 基盤の機能開発と組織の能力開発のバランスを取るのは重要かなというのを改めて思ってます。 組織の能力開発というのは、何を言ってるのかっていうと、データを活用する目的に照らし合わせて考えると、各メンバーのデータの知識だったりとかSQLのスキルとか、ITスキルを組織として高める、進めることかなと。 これが進むと基盤のシステムとしての機能開発をちょっと遅らせることができます。 システムは作れば作るほど、保守もそうですし、いろんな依存性も高まってくるので、システムにとっての重要な決断ができにくくなっていくものだと思うんですが、組織のメンバーの能力開発を進めることでシステムの開発を遅らせ、より知見が溜まり判断精度が上がったときにシステムの拡張をするということができます。こういった点は基盤の開発の観点で重要なのかなと改めて思います。 ユーザのためと思って安易に機能を作り込むのが中長期的には必ずしも正解とは限らないというのがあるかなと。
次に個別案件での最適化を安易に行わない。これは当たり前の話ではありますが、これまでWMSとか検索システムが保持しているデータとか、ログデータの同期を、それぞれ別のツールとかミドルウェアを使って同期の実装を行ったんですけど、このシステムからこういうデータ同期してほしい依頼って次々出てくるので。適材適所といえば響きはいいですが振り返ってみるとただの局所最適だったみたいなことがあって。全体を見通した上でミドルウェアとかツールを選定すべきだったなというのが学びとしてはあります。
最後に
本記事ではデータ基盤の歴史の振り返りの前編としてBigQueryの導入と展開までを紹介しました。後編ではBigQueryによるデータ基盤をさらに活用するための基盤展開ならびにデータの統制管理、そしてモノタロウにおけるデータ基盤の今後について、また歴史の振り返り全体を通しての学びについて紹介する予定です。
この記事をよんでモノタロウのデータ基盤に興味を持った方は 10/28(木) にデータ基盤・データマネジメントをテーマとしたイベントを行いますのでぜひご参加ください。
またカジュアル面談なども随時行っていますので詳細を聞きたいかたは下記のメールアドレスまでお気軽にお問い合わせください。
問い合わせ先: recruit-data-platform@monotaro.com