こんにちは、SREグループの岡田です。
モノタロウではモノタロウのクラウドネイティブ化の取り組みについて - MonotaRO Tech Blog
にも記載されているようにシステムのモダナイズに取り組んでおり、その一環でEKSのPoCそして実際にECサイトの裏側のAPIを対象にコンテナ化に取り組みました。
この記事では移行時に起こったトラブルとハマったポイントの1事例をご紹介します。
前提
今回移行対象のAPIは100以上のエンドポイントを持つモノリシックなAPIで、ALB + Auto Scaling Groupを利用してEC2で運用されていました。今回は並行稼働しつつ、いくつかのエンドポイントを段階的に露出して不具合があれば切り戻しを行う、問題なければ全てのエンドポイントをコンテナ版に移行するという方針で進めていました。
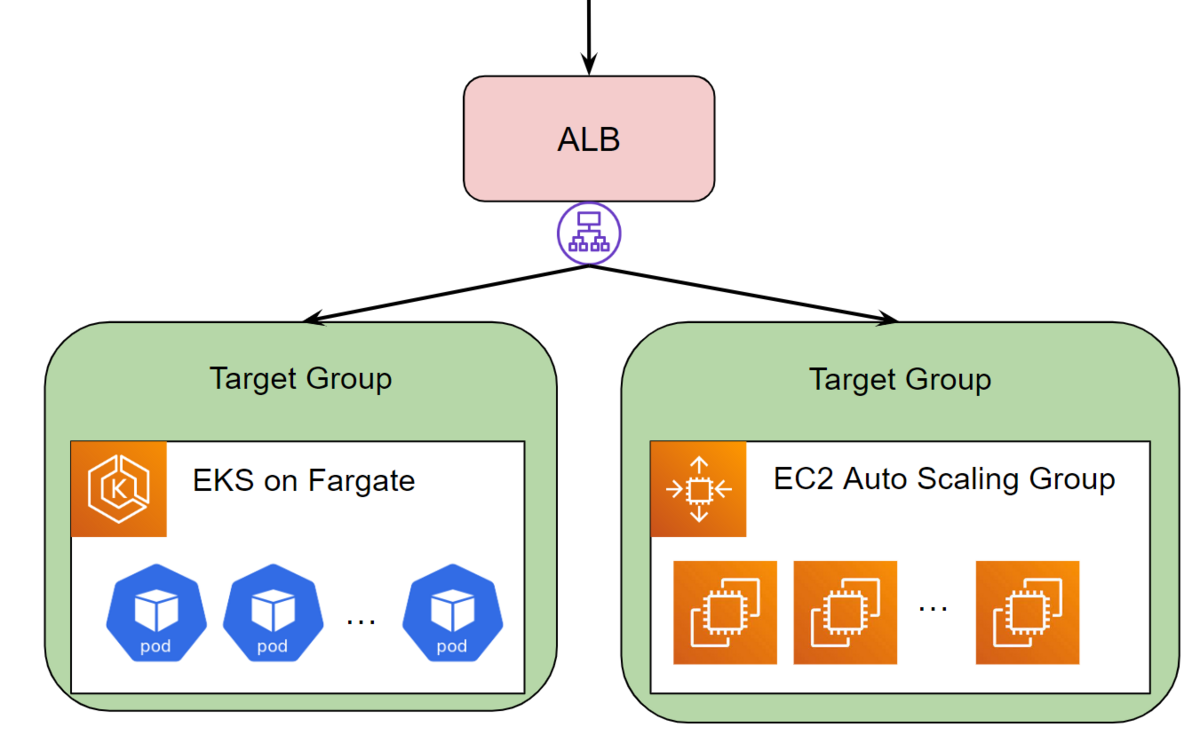 図.構成(実際はアカウントがわかれていたり、コンテナ側のアカウントのALBとの間にNLBが挟まっていたりともう少し複雑になります。)
図.構成(実際はアカウントがわかれていたり、コンテナ側のアカウントのALBとの間にNLBが挟まっていたりともう少し複雑になります。)
起こったトラブル
本件のトラブルは、アプリケーションリリース時にPodが切り替わるタイミングで発生しました。アプリケーションのログにエラーはありませんでしたが、ALBのログにはエラーが数件記録されていました。そのため、アプリケーションまでリクエストが到達していないことが考えられました。
エラー数自体は2エンドポイントのみ移行した段階だったため少なかったですが原因がわからず、一旦切り戻しを行った上で調査を開始しました
トラブルシュート
1. 問題の整理と仮説
当初、問題の発生源を特定するために、エラーが発生したPodのIPを特定し、関連するコンポーネントのログ(例えば、kube-controller-manager(replicaset-controller)、AWS Load Balancer Controllerなど)を集めて調査しました。これらのログを時系列順に並べて、各処理の前後関係や流れを整理しました。
整理
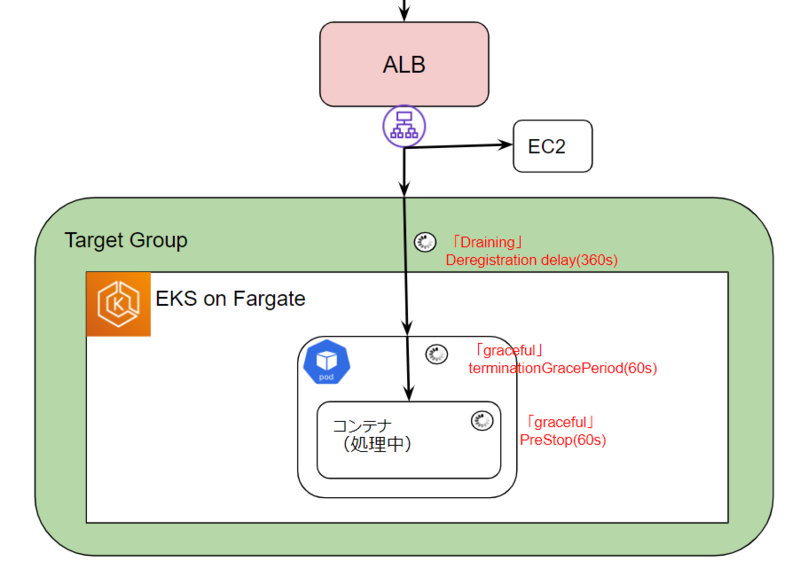
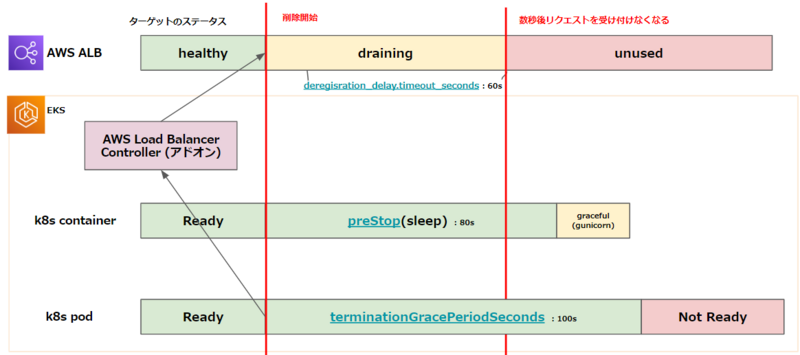
・Podは期待通りterminateになってから60s後に削除されている。
・AWS Load Balancer Controller(EKSクラスタ内からALBへのPodのアタッチ及びデタッチを行うコントローラー)のderegisterリクエストは成功している。
・実際にALBから登録解除された時間は分からない。
・Podを削除するまでの待機時間中かつALBの登録解除前後でエラーが生じている。
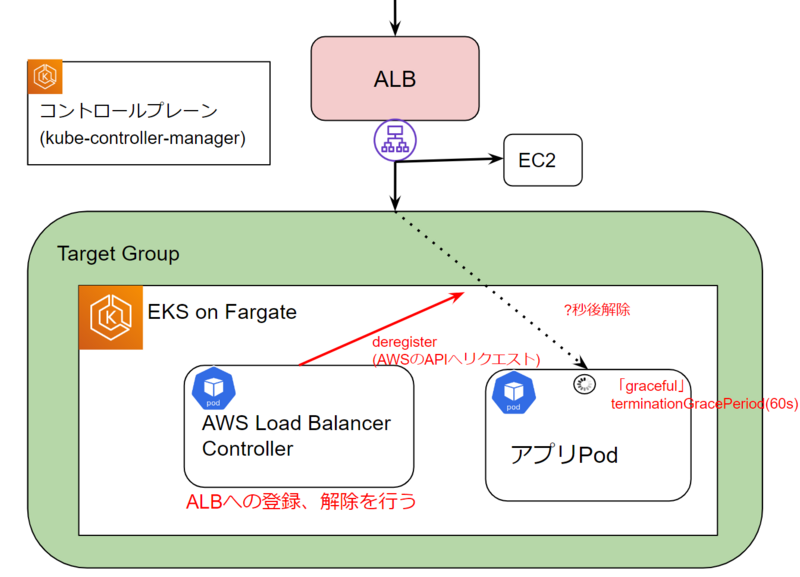
図.事象の整理
| ログ概要 | ログ出力箇所 | |
| 17:57:33 | Podの削除開始 | コントロールプレーンの該当コントローラー(詳細は略) |
| 17:57:34 | ALBからの登録解除をリクエスト | AWS Load Balancer Controller |
| 17:57:46 | ALBへのリクエストログにてエラーが出ていた時間 | ALB |
| 17:58:33 | 実際にPodが削除された時間 | コントロールプレーンの該当コントローラー(詳細は略) |
整理を行う中でPod及びコンテナのライフサイクル管理及びALBとPodの接続回りが怪しかったため、以下のような仮説を立てて一つずつ検証していきました。

図.立てた仮説例
2. 検証
ALBが実際に登録解除された時間など不明点もあったため、私たちはAWSのサポートの方に調査をお願いしつつ並行でこちらでも調査を進めました。起こったエラーの再現と検証をすべく、ある程度負荷をかけた状態で条件を変えながらPodの入れ替えを複数回行いました。
検証1.Podのステータスがterminate状態になってから削除されるまでの時間を変えてみる。
まず初めにPod及びコンテナが削除されるまでの待機時間が短く、それ以上に処理時間がかかったリクエストがエラーになった可能性を検証しました。
今回のケースが起こった時点ではどちらも60sに設定していましたが、時間をさらにのばして複数回検証してもエラーは特に減少しませんでした。
terminationGracePeriodSeconds: 60
lifecycle:
preStop:
exec:
command: ["sh", "-c", "sleep 60;"]
検証2.Pod Readiness Gateを試す。
kubernetes上のPodでは新しいイメージをリリースする際、Rolling updateで新しいPodを起動->ヘルスチェックに成功すると古いPodを削除というステップで段階的に行います。

しかし、EKS+ALBの場合はPodの起動後にAWS Load Balancer ControllerによってALBにアタッチされるというステップがあるため、アタッチが完了するまでに古いPodが削除されてしまうと処理可能なPodがなくなり一時的なダウンタイムが発生する可能性がある事がわかりました。
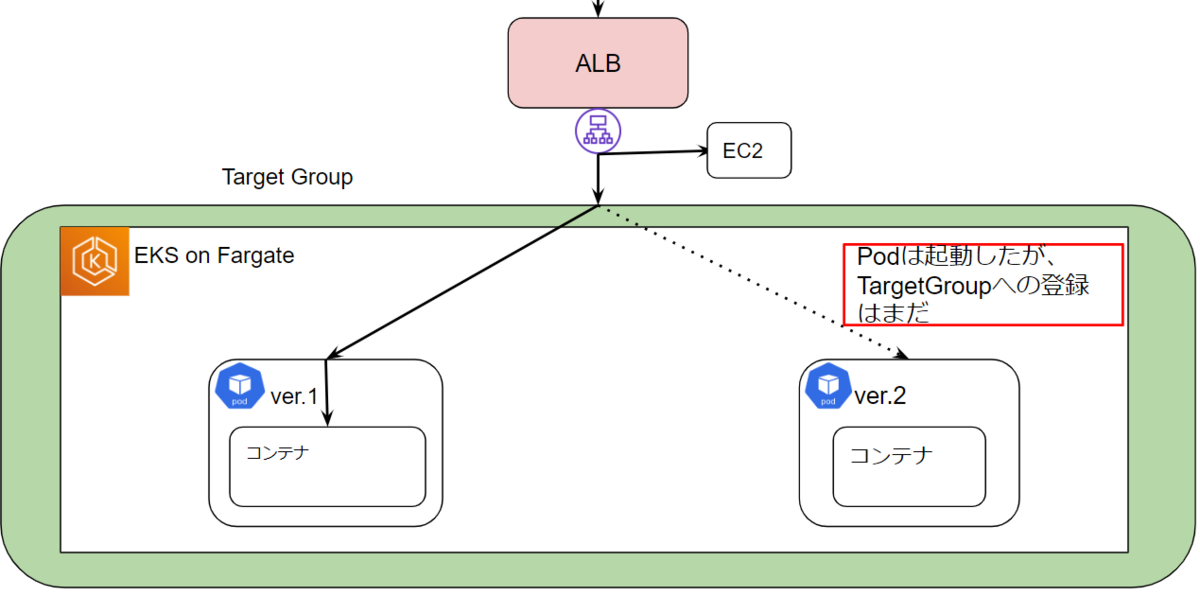
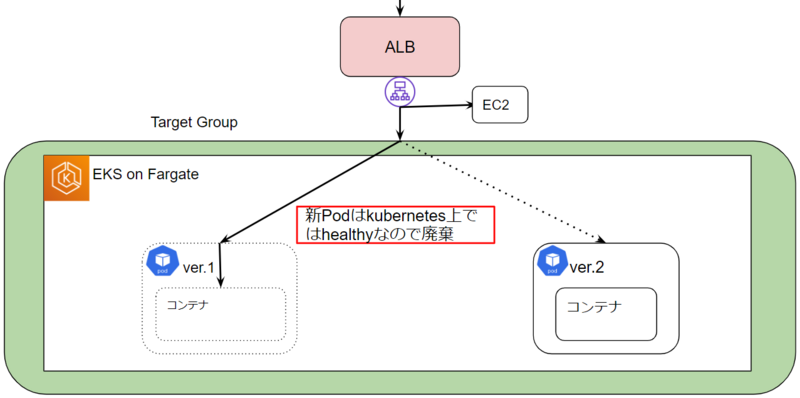
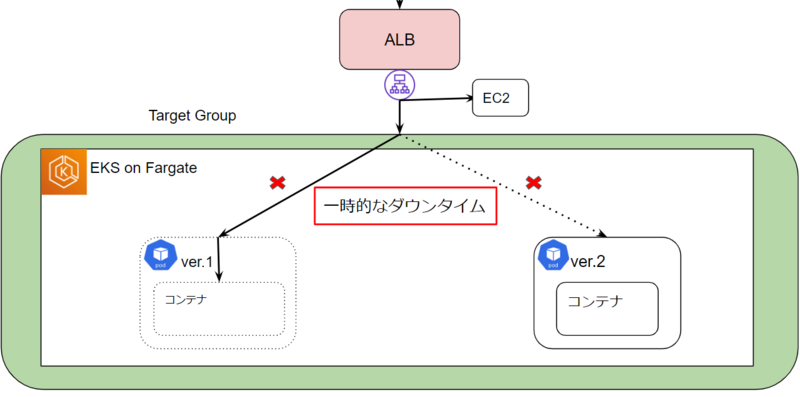
この解決策としてPod Readiness GateというPodのstatusがReadyかどうかの判定をユーザーが制御する仕組みがあり、AWS Load Balancer ControllerでもALBから見てhealthyになってからPodのstatusをReadyにする(古いPodの削除を開始する)という機能があります。
以下のlabelをnamespaceに入れる事でPod Readiness Gateを有効にできるため、早速検証環境で負荷をかけつつ、Podの入れ替え時の挙動を確認してみました。
elbv2.k8s.aws/Pod-readiness-gate-inject: enabled
参考 Pod Readiness Gateについて
設定前は新しいPodのアタッチが始まると同時に古いPodのdrainingが始まるのに対して、設定後は全てhealthyにならないと古いPodがdrainingに入らないことが確認できました。
| 設定前
|
設定後
|

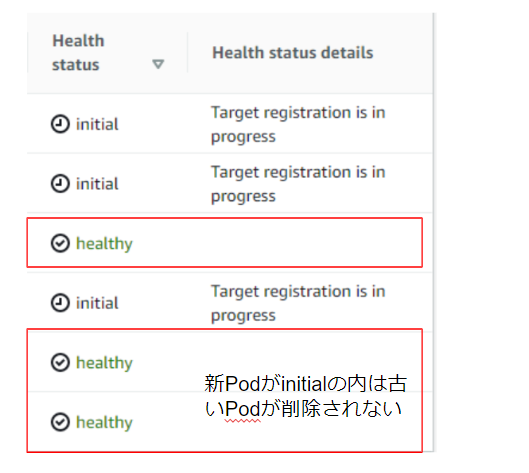
しかし実際にPodの入れ替え中にエラーがでなくなるか検証してみるとエラー数はある程度減少したもののまだ少しエラーが出る状態でした。
(この辺りの段階でAWSサポートの方から回答があり実際に起こったエラーはAWS側のエラーであったことが判明しましたが、検証環境では少しエラーが再現することから調査自体は継続しました。)
■ 回答 この度のエラーに関してはALB側の問題の可能性が高いことが確認できました・・
検証3. ALBのDeregistration delay(登録解除までの待機時間)を短くしてみる。
Podのライフサイクルについては一通り調査したため、次はALBを調査しました。
今回のケースではPodの入れ替え時に起こった事、平常時は特にエラーが起こっていない事から関連しそうな設定はALBの「Deregistration delay」という登録解除までの待機時間を制御する設定のみでした。
調査していくと登録解除されるまでの待機状態であるDrainingについて認識違いをしており、Draining中でもリクエストが完全にふられなくなるわけではない事や、ターゲットが削除されるとエラーが出るケースがある事がわかりました。
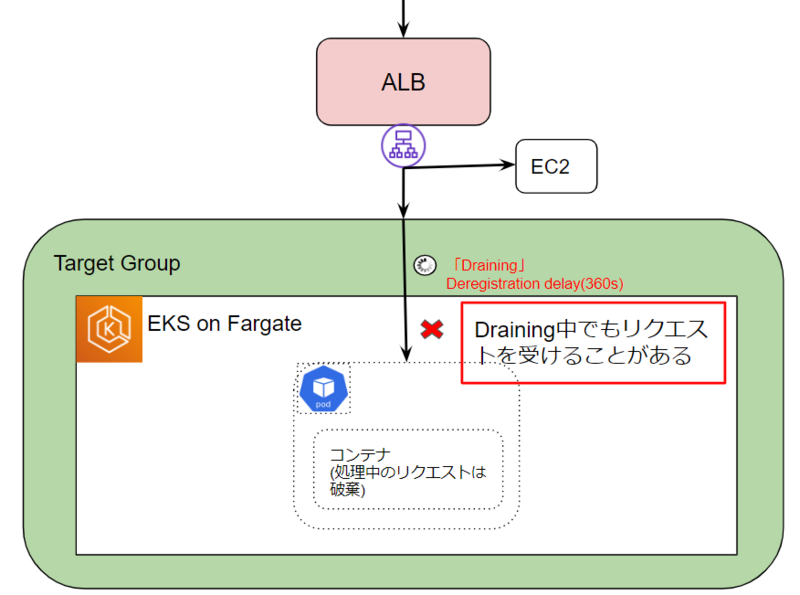
If a deregistering target terminates the connection before the deregistration delay elapses, the client receives a 500-level error response.
参考
Drainingについて docs.aws.amazon.com
Deregistration delayについて docs.aws.amazon.com
実際にこの猶予時間をPodの待機時間である60sより短い時間にして検証を行ったところエラーが起こらなくなりました。
AWSサポートの方にもお聞きすると、Podの待機時間はALBの登録解除までの猶予時間よりもさらに余裕を持たせておくべきという事がわかりました。
■回答内容 現段階のALBの挙動といたしまして、登録解除の遅延が実行されたタイミングちょうどで、リクエストをルーティングしなくなるわけではなく・・ PodのPreStopの時間につきましては登録解除の遅延(Deregisteration delay)よりもある程度(例えば10秒以上)余裕を持って設定いただけますと幸いです。
分かった事
ALBを含めたPod入れ替え時の挙動
EKSではPodの入れ替え時にALBに登録が完了していないにもかかわらず、古いPodの削除を開始してしまうため、登録が完了してから削除を開始するためにAWS Load Balancer ControllerがサポートしているPod Readiness Gateを設定する必要があります。また、ALBでは登録解除までの猶予時間(Draining)中でもリクエストがふられる事があり、Podの待機時間はさらに余裕を持たせておく必要がありました。
(これを機に、以下のように待機時間を見直しました。)
EKSにおけるトラブルシュート
今回のエラーの原因はAWS側の問題でしたが、トラブルシュートを通じて当初意識していなかったEKSのPodのライフサイクルやALBの仕様について理解を深めることができました。
また、マネージドである程度隠蔽されているとはいえコントロールプレーンの各コンポーネントがどのリソースを触るのかや一連のログの追い方、kubernetesのみでなくEKS固有のポイントについても理解を深め、正確な判断ができるようになる必要性を感じました。
段階的な移行のメリット
運用開始当初は今回の移行で新たにできるコンテナレイヤー、特にEKS周りのトラブルに慣れていない状態でした。しかし、即座に切り戻し可能な状態で進める事ができたため、顧客影響を抑えた状態でトラブルシュート経験を積むことができ、本件以外にもテスト環境で検出できなかったいくつか修正が必要な箇所に気づくことができました。
おわりに
実際のトラブルシュートはここまで綺麗なステップで解決できたわけではありませんが、諸々試行錯誤していく過程で当初意識していなかった仕様や挙動について認識し、理解を深めることができました。
既に運用中の方にとっては当たり前の内容だったかもしれませんが、今後同様にEKSでのアプリケーション運用を考えられている方にとって少しでも参考になればと思います。
私たちは現在、複数のアプリケーションのコンテナ化及びマイクロサービス化などを通じてシステムのモダナイゼーションを進めています。また、SREグループではその他にもSLOの推進及び活用、リリース改善などよりハイレベルな運用を目指して日々チャレンジしています。
当記事を通じてMonotaROに興味を持っていただいた方は、カジュアル面談もやっていますのでぜひご連絡ください!