- はじめに
- MonotaROの販促とパーソナライズチラシについて
- 間接資材の推薦における課題
- 「もう一度購入する枠」における推薦手法
- リピート行動を考慮する推薦手法
- RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-based Recommendation(AAAI'19)
- ReCANet: A Repeat Consumption-Aware Neural Network for Next Basket Recommendation in Grocery Shopping(SIGIR'22)
- Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation(RecSys'24)
- 最後に MonotaRO DS研究会について
- 参考文献
はじめに
データサイエンス部門で推薦アルゴリズムチームに所属している織田裕樹です。
MonotaROでは後述するパーソナライズチラシのアルゴリズムの開発に取り組んでいます。
MonotaROには全体でおおよそ30名ほどのデータサイエンティストが所属しており、
検索・推薦・サプライチェーンなどのドメインごとに小チームに別れて、技術リサーチ・実験結果の共有・サービス適用への具体的な議論等を行う研究会と呼ばれる取り組みが存在します。
本記事では、弊社のデータサイエンス部門における推薦研究会でサーベイを行った、リピート購入行動を推薦アルゴリズムに取り込む手法に関する現在の研究について共有を行い、 記事の最後にMonotaROにおいて活動が行われている研究会についても紹介いたします。
MonotaROの販促とパーソナライズチラシについて
MonotaROの推薦チームでは大きく2つの機能開発を推進しており、
- monotaro.comにおけるサイト上における推薦機能
- チラシ・メール・カタログなどのサイト外での推薦機能
の開発を行っています。
他社ECと比較して見かけることの少ない推薦機能の一つに、パーソナライズチラシがあり、 MonotaROではお客様一人一人にカスタマイズしたお客様専用の冊子をお送りしております。
具体的には、過去のMonotaROにおける購入履歴を元に、 お客様のアカウントごとに業務の関連度の高い商品リストや商品特集ページを一つの冊子にしてお送りしており、 この取り組みを、2021年ごろから行っています(※1)
私の担当業務は、上記の作成したコンテンツを冊子内でパーソナライズ化することがメインの業務になるのですが、上記の改善のポイントとなる、間接資材の推薦におけるユーザー行動の特徴についてお話しします。

※1. MonotaRO 2024統合報告書より抜粋.
間接資材の推薦における課題
MonotaROは主に法人向けの業務用途で活用する間接資材をメインに取り扱っています。
間接資材とは、定義上は法人の事業活動における商品やサービスの製造に直接使われない資材「全て」のことを指しており、全てとある以上、膨大なカテゴリ・商品の取り扱い(※2)を行っています。
また、一部の間接資材の特徴として、
- 建設業における軍手や工具
- 飲食業における弁当箱やビニール袋
など、事業運営において定期的な購買が必要になる商材も存在します。
上記のような商材を含めた間接資材を取り扱っている性質上、以前購入したアイテムのリピート購入が売り上げに占める割合も少なくありません。また、2,420万SKUもの間接資材を扱っている性質上、商材のカテゴリの幅も非常に広く、商材ごとのリピートのされやすさについても商品により大きく違いがあることが確認できています。
そのため、顧客のリピート購入行動をどのように推薦に反映させるかについて先行研究のリサーチを行いました。本記事では現在確認できた推薦手法に関する幾つかのアプローチとその主要論文について紹介いたします。

※2. MonotaROで取り扱っている手袋の例
手袋のラインナップだけでも、膨大な種類・ユースケースがあることが確認できます。
「もう一度購入する枠」における推薦手法
Buy It Again: Modeling Repeat Purchase Recommendations (KDD'2018)
顧客のリピート購入をレコメンドに活用するという観点においてはオーソドックスな手法の一つに「もう一度購入する枠」をWebサイト上に設けて、過去の購入商品を候補商品として推薦を行う手法があります。
研究の先駆けはAmazonにおける「もう一度購入する」枠における推薦で、顧客の過去購入アイテムを候補商品として再購入確率の推定を行い、スコア順に商品を並び替えて推薦を行うという手法です。
論文においては、「過去購入商品の時刻tにおける購入確率」を推定する非常に一般的な形式のタスクとして定義されており、推定する確率モデルを差し替えることで、パーソナライズ度合いや購買パターンの考慮を変更することができます。
論文においては、Amazonの実データを元として実際に検証が行われたモデルが紹介されており、購入確率の推定の式はベースラインとなる手法から、よりユーザーの実際の行動に基づくパーソナライズ手法まで、以下で紹介する4つの手法が紹介されていました。

数式を眺めてみると、上記二つは、当該商品を購入した平均的なリピート購入を元に推定するモデル。下記二つは、ユーザーの固有パラメータとしてガンマ分布を与えて、過去の購入回数・前回からの購入のrecencyを考慮してリピート確率を推定するモデルとなっていることが確認できます。
このうち、パーソナライズモデルであるPoisson-Gamma(PG) / Modified Poisson-Gamma(MPG)モデルについて掘り下げて中身を確認してみると、ポアソン分布のパラメータλ (平均と分散に相当)を推定するというタスクは両者で共通していますが、
PGの場合はλがピークとなるタイミングが、 t=0 購入直後) の場合となっているのに対し、MPGの場合は、当該商品の平均的な購入間隔 t_mean の場合にピークとなるようにモデルが設計されています。
狙いとしては「再購入確率が最大化するタイミングは、ユーザー固有の購買の周期性に依存している」という実データの購入パターン分析に基づいたものであり、非常に合理的な式になっています。
推薦アルゴリズムとして考えるとシンプルなモデルになりますが、その事業に与えるインパクトとしては大きく、オフライン性能でnDCGが+39%ものリフト。オンラインテストでは+1.6%ものCTRリフトの改善が見られたという結果が報告されています。 推薦アルゴリズムの改善、というとどうしてもモデルを複雑化させる方向で思考してしまいがちではある中で、UX的な視点での課題設定を行い、効果を創出できたという事が非常に重要な結果であると考えています。
Personalized Category Frequency Prediction For Buy It Again Recommendations (RecSys'23)
また、上記の発展手法としてTarget.comにおけるRecSys23の論文Personalized Category Frequency Prediction For Buy It Again Recommendationsについても紹介します。
こちらの論文の課題意識としては、target.comの商品のリピート回数の分布を見ると、大半の商品において「リピートされずに1回購入で終わってしまう」割合が高いことが確認できており、 このことに起因して「商品単位でのリピート率の推定がうまく機能しない」という実務でも発生しうるリアルな課題に取り組んでいます。
本研究においては、Purchase Category-Inter Categoryモデル (PC-IC)と呼ばれる手法を新たに開発し、
- 購入が滅多に発生しない商品のフィルタリングを行う
- 商品単位ではなく、カテゴリ単位での購入確率を推定することでスパース性の影響を除外
- カテゴリ内でのリピート購入アイテムの重要度を「カテゴリ間の相互作用を含めて」リランキングする
という手法で、商品単体のリピート確率を推定するタスクを上手く回避する仕組みを導入することで解決していました。
興味深かった点としては、推定したカテゴリ単位の購入確率を元に単純に並び替えるという手法ではなく、カテゴリごとのリピート率をインプットとして全結合層に入れることで、カテゴリ間の相対的な重要度を考慮した上で商品を並び替える、 という手法を取っていることで、推薦対象が特定のカテゴリに偏りすぎない工夫が施されていました。
こちらもベースライン手法と比較して+16%ものnDCGリフトが確認。オンラインテストでもベースラインと比較してCTRが+6%リフトが確認されたと報告されています。
リピート行動を考慮する推薦手法
上記のBuy It Againの推薦タスクとは独立して、明示的な購入行動パターンを取り入れることで、リピート推薦のタスクを切り出すことなく、全体の推薦機能を向上させることを目的とした研究も存在します。
こちらの研究の興味深いところとしては、データセット特性には依存するという制約はありつつも「購入行動としてのリピートを考慮することで、新規商品の推薦の品質向上が確認できる」という報告結果が少なくないことです。
ここからはあくまで推察ですが、単純に過去購入履歴を元にしてランキングモデルを作成する場合にありがちな、
- 購入済アイテムが上位に集中してしまい、関心度の高い新規アイテムの推薦順位が上がりにくい
- 購入済アイテム自体は重要度が高い一方、適切な購入タイミングからは外れている
等の「推薦におけるノイズ商品を適切に除外できる影響」や「リピートを考慮したことによるユーザー行動に対する理解」が、全体の推薦に良い影響を与える可能性があるのではと考えています。
以下では、リピート購入行動をニューラルネットワーク内に取り込むことで推薦品質を向上させたと報告があった論文のうち、代表的なものを紹介していきます。
RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-based Recommendation(AAAI'19)
推薦タスクの設定としては、いわゆるセッションベース推薦で、セッション内における過去購入(or クリック)アイテムの系列に対して、次回購入(or クリック)アイテムを推薦する手法を提案しています。
著者によるPyTorch実装が公開されているため、こちらの内容を元にアーキテクチャの紹介を行います。

推薦のステップの概略を説明すると、
過去購入アイテムの系列に基づくアイテムごとの潜在表現をGRU経由で得る
1.の潜在表現を元に、過去系列に基づくユーザーの潜在表現ベクトルを獲得し、
系列とユーザーの潜在表現を元に過去購入していない商品の購入確率を推定する
1.の潜在表現を元に過去購入アイテムの購入回数を考慮した重要度をAttentionを用いて算出し、
系列の中における過去購入アイテムの重要度を特徴量としてSoftmaxを用いて購入確率を推定する
1.の潜在表現の系列を元に、次の購入アイテムが
- Explore-mode (新しいアイテムの購入)
Repeat-mode(過去購入済みのアイテムの再購入)
のいずれになる確率が高いかどうかの確率を推定
2, 3, 4の確率値を元に、次セッションにて当該アイテムが購入される確率を推定
というステップで、顧客が今「新しいアイテムを探している(Explore-Mode)」のか「過去購入したアイテムを探している(Repeat-Mode)」のかを過去の系列長の情報から推定するというタスクを上手くニューラルネットワーク内に内包できる仕組みを構築できています。
オフライン実験の結果でいうと、三つのデータセットに対してベースラインと比較してMRR@k, Recall@kの観点で上回る性能が得られたことが報告されています。
ReCANet: A Repeat Consumption-Aware Neural Network for Next Basket Recommendation in Grocery Shopping(SIGIR'22)
RepeatNetとは別にNext Basket Recommendationにおいてリピート行動を考慮したモデルがこちらで紹介するReCANetです。
特徴としては、リピート購入行動をアイテム単位で直接予測するという枠組みでバスケットの予測を行っており、ユーザー×アイテムの時系列に沿った購入・消費パターンそのものを学習させるという仕組みが取り入れられています。
ReCANetは実装が公開されていませんが、同様にステップに分けて手法の概略について紹介します。
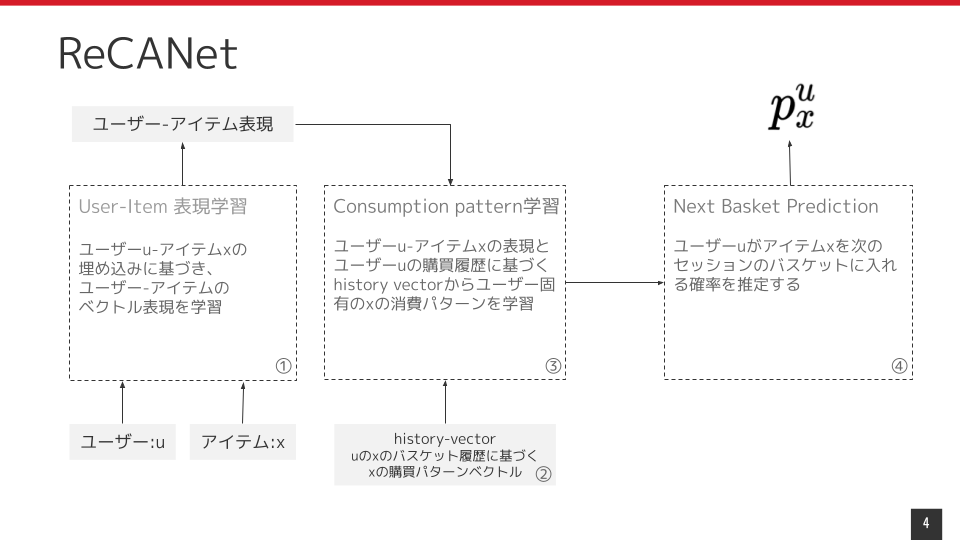
推薦のステップの概略を説明すると、
ユーザー、 アイテムの情報を元にユーザー-アイテム表現を得る
アイテムの過去購入履歴を元に、バスケットに投入される頻度・購入リーセンシー・連続購入間隔などを考慮した、
バスケット系列に対するhistory-vectorを作成する
1, 2の情報をLSTMに投入することで、ユーザーがそのアイテムに対してどのような時間軸で購入が行われるかに関する
購入パターンの表現を獲得する
2.3の情報を元に、次のバスケットにアイテムが投入される確率を予測する
1~4.までのステップを全てのアイテムに対して行い、購入確率順に並び替えることで、次のバスケットに含まれるアイテム群を予測する
ユーザーとアイテムの相互作用を含めた関係性と、ユーザーのアイテムの購入パターンを考慮することで、時系列の中でどのような消費パターンになっているか、を明示的にモデリングするという仕組みのため、枠組みとしては非常に分かりやすいモデルになっています。
こちらの手法についても、6つの食料品のショッピングデータセットにおいて、全てのベースライン手法と比較してRecall@k, nDCG@kで勝利したという結果が報告されています
また、アブレーション実験の結果から、history vectorを除外した時の性能悪化が最も大きいという結果が得られています。
これはユーザーのアイテムに対する固有の購入パターンを明示的に取り入れることで、モデル性能が良化する可能性について示唆しています。
Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation(RecSys'24)
上記二つのネットワーク群の更なる発展形として、こちらの論文では、音楽の聴取系列に関するNext Basket Recommendationのタスクにおいて、PISA(Psychology-Informed Session embedding using ACT-R)というモデルを提案しています。
繰り返し再生される音楽の系列情報を元に、ユーザーの短期的な嗜好と長期的な嗜好についてのベクトル表現を得ることで、系列の時系列に依存しない一貫した嗜好性と、直近のセッション系列に基づく聴取パターンの両方を上手く反映した推薦モデルの作成を行っています。
PISAも実装が公開されているため、こちらの実装に沿ってステップごとに紹介していきます。
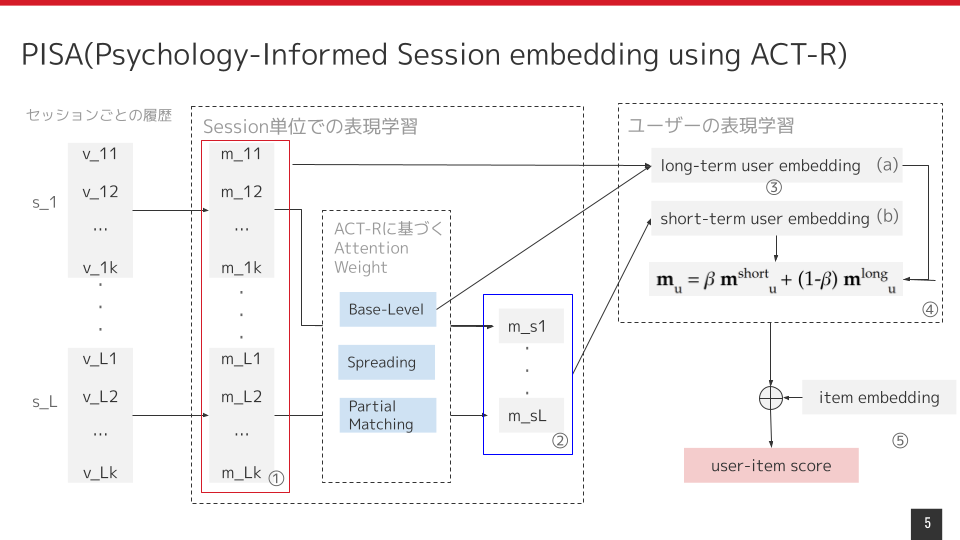
過去セッション系列において視聴した、学習済みの楽曲埋め込みモデルを用いてembeddingを作成する
セッションごとの楽曲embeddingリストから、楽曲ベクトルの中での活性化度合いを表す重みを
下記の三つのモジュールに基づいて算出し、総和を取ることでセッションの表現を得る
- Base-level Component: 楽曲が過去どの程度聴取されたか
- Spreading Component: セッション内の他の楽曲との共起度合いが高いか
- Partial Matching Component: セッション内の他の楽曲と埋め込みの類似度が高いか
2.で得られたセッション単位の表現の系列を元に性質の異なる二つのベクトル表現を得る
- Base-level Componentが大きいtop20個の楽曲ベクトルを平均することでユーザーの長期の嗜好性を表現したベクトル表現を得る
- セッション表現系列に対してSelf-Attentionを適用することで、系列のパターンに基づくユーザーの短期の嗜好性を表現したベクトル表現を得る
3.で得られた二つのベクトル表現の重み付け和を取ることでユーザーのベクトル表現を得る
4.で得られたユーザーのベクトル表現と楽曲のベクトル表現の内積を取ることで、楽曲のランキングを得る
上記の説明で特徴的な点としては、明示的なリピート・探索モジュールを導入する訳ではなく、セッション内での楽曲ごとの関係性を含めた相対的な重要度と、セッションシーケンスの中における重要度の両方を考慮することで 、時間と共に変化する自然な繰り返し聴取のパターンや楽曲の探索傾向について、自然に考慮できるようなアーキテクチャになっています。
気になる結果ですが、リピート楽曲に絞ったRecall@k, nDCG@kにおいてRepeatNet,ReCANetを含む既存手法と比較して改善が見られたことに加えて、未聴取の楽曲に絞ったRecall@k, nDCG@kにおいても大きく改善が見られたことが報告されています。
この事から明示的にリピート購入か否かをモジュールに組み入れることで大きく改善が見られたRepeatNetと比較して、実際のExplore-Repeatパターンについては時系列に依存した嗜好性のシフトが発生しやすい可能性があり、ドメインによってはその微妙なユーザーの変化を捉えられるモデルが今後の主流になっていくのかもしれません。
最後に MonotaRO DS研究会について
最後に自社の取り組みの宣伝にはなってしまいますが、MonotaROのデータサイエンス部門においては、データサイエンス領域における研究会がドメインごとに存在しており、主に「検索」「推薦」「マーケティングサイエンス」「サプライチェーン」「エンタープライズビジネス」などの分野におけるMonotaROにおけるデータサイエンスの活用について分科会ごとに活発に議論を行っています。
また、社内のデータサイエンティストは所属している研究会とは別の研究会の議論にも自由に参加することができます。
本記事も社内勉強会をきっかけとして生まれた記事の一つで、実際の研究会においては論文紹介だけでなく、実際のMonotaROにおけるデータを用いたオフライン・オンライン実験の結果等を踏まえ、自社の推薦機能にどう生かせるかについて議論が行われる環境となっています
業務で磨いたデータサイエンス技術を実務で活用したい。専門性の高い仲間と自身のスキルを磨きたい。という方は、ぜひカジュアル面談にお越しください。
参考文献
- 本記事で紹介した資料
- 本記事で紹介した論文
- Buy it again: Modeling repeat purchase recommendations - Amazon Science
- Personalized Category Frequency prediction for Buy It Again recommendations | Proceedings of the 17th ACM Conference on Recommender Systems
- [1812.02646] RepeatNet: A Repeat Aware Neural Recommendation Machine for Session-based Recommendation
- ReCANet: A Repeat Consumption-Aware Neural Network for Next Basket Recommendation in Grocery Shopping | Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval
- [2408.16578] Transformers Meet ACT-R: Repeat-Aware and Sequential Listening Session Recommendation