はじめに
はじめまして、データサイエンスグループの岡林です。普段はbanditなどの強化学習を用いてUIの最適化に取り組んでいます。 このブログでは最近MonotaROが注目しているbanditの概要を紹介しつつ、その中でも事業特性にあったbanditアルゴリズムにフォーカスし、論文を解説します。
MonotaROとBandit
Banditの着目理由
MonotaROでは、商品単位レベルでのUI最適化に取り組んでいます。例えば、商品に応じて商品ページのコンテンツ文言などを変化させ、より適切なUIを提供することに取り組んでいます。具体的には、UIのパターンを何通りか考え、その中で表示する商品に適したUIパターンを提示していきたいと考えています。
MonotaROでは、最適なUIパターンを決定するために、ABテストを実施して各パターンの性能を評価しています。しかし、商品単位で最適なUIを評価するためには、商品ごとにABテストを実施する必要があり、評価サンプルを収集するのに時間がかかってしまいます。そこでcontextual banditに着目しました。contextual banditとは、確率的banditを拡張した考えです。
まず、確率的banditについて説明し、その後contextual banditについて説明させていただきます。
確率的banditとは、「複数の選択肢(arm)から1つを選択し、その選択肢から報酬を得るが他の選択肢からは報酬を得られない」という環境において、得られた累積報酬和の最大化を目指す逐次決定問題です。 例えば、以下の図1のように、UIパターンA・Bのうち、商品がより購入されやすいUIを決めたいとします。このとき、armはUIパターンA・Bの2つで、報酬は「購入したかどうか」の2値となります。はじめ、確率的banditはAとBどちらがより購入されやすいかがわからないため、ランダムにAとBをユーザーに表示します(探索フェーズ, ① - ④)。ある程度sampleが溜まると、過去のsampleからA・Bそれぞれの購入確率を推定し、購入確率が高いUIパターンをより多くユーザーに表示します(活用フェーズ, ⑤- )。確率的banditは、このように探索と活用を繰り返しながら、徐々に最適なarmを決定していくアルゴリズムです。
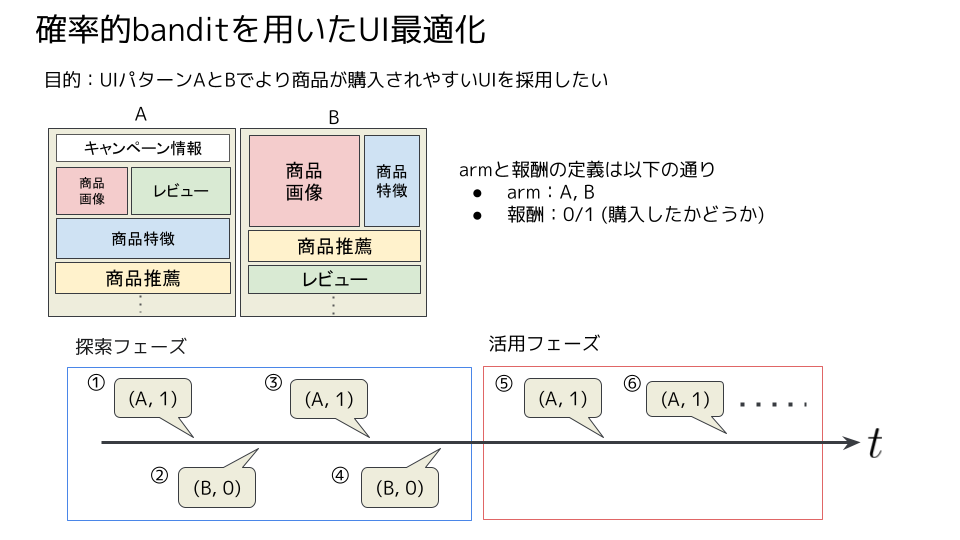
確率的banditでは、armから得られる報酬がある確率分布に従って発生することを仮定します。その確率的banditに汎化予測機能を取り入れたのが、contextual banditです。contextual banditでは、ユーザーや商品情報を表す特徴(context)に応じて報酬がある確率分布に従うことを考えます。 商品単位でのUI最適化の際に、contextに商品情報を組み込んだcontextual banditを用いることで、その商品自体のサンプルは少なくとも、類似商品のサンプルをもとに最適なUIを決定することを期待できます。
MonotaROにBanditを導入する際の課題
しかし、単純にcontextual banditをそのまま導入しようとしても上手くいきません。それはcontextual banditが考える仮想環境とMonotaRO ECサイトの実環境ではいくつかの乖離、課題点が見られるためです。そのため、この課題点を克服する必要があります。 課題はアルゴリズムとデータパイプラインの2つに分かれます。今回はアルゴリズムに関する課題を挙げていきます。データパイプラインの課題に関しては後日別記事で取り上げます。アルゴリズムの課題として、例えば以下があります。
- 報酬確率分布が一定でない
- 報酬が遅延する
- 複数の報酬要素を考えたい
1つ目から順に解説していきます。
1つ目の「報酬確率分布が一定でない」についてです。contextual banditでは、報酬がある確率分布に従っており、その確率分布が一定であるという環境を考えます。しかし、MonotaROはその環境に当てはまりません。MonotaROでは、ユーザーの多くが法人・個人事業主であるため、平日のam8:00 - pm 6:00 くらいは購入率が高く、それ以外は購入確率が低いです。また、毎日様々なキャンペーンをしています。例えばカテゴリ特価ではキャンペーン日の特定のカテゴリは割引が適用されます。そのため、特定日の特定カテゴリが一時的に購入率が高くなることがあります。
2つ目の「報酬が遅延する」についてです。contextual banditでは、即時に報酬が得られることを前提にアルゴリズムが組まれています。しかし、報酬によっては保証できない場合があります。例えば、図1の場合、UIを表示したあとにその商品を購入するまでの時間はユーザーや状況に依存します。「必ずいつまでに報酬が発生する」という保証はありません。そのため、contextual banditは報酬が発生したのかどうかを判断できず、学習ができません。
3つ目の「複数の報酬要素を考えたい」についてです。例えば、contextual banditをもちいて売上が最大になるarmを選定したいとします。しかし、売上を追い求めた結果、登録率や離脱率のような購買行動やUXに関する指標が悪化することは避けたいです。そのため、報酬には、売上だけでなく登録率などの他の要素も考慮したいです。しかし、contextual banditでは通常1つの報酬要素のみを考慮します。
これらの問題に対して、近年様々なcontextual banditの改良手法が提案されています。3つの課題それぞれに対応する研究分野と参考論文を以下の表でまとめました。
他にもbanditには利用シーンに応じた様々な改良手法があります。A map of bandits for e-commerce では、ECサイトにおけるシーンごとのbandit手法の紹介があり、改良手法をキャッチアップするのに非常にためになりました。
| 課題 | 分野 | 参考論文 |
|---|---|---|
| 報酬確率分布が一定でない | non-stationary bandit | A Linear Bandit for Seasonal Environments |
| 報酬が遅延する | delayed bandit | Linear Bandits with Stochastic Delayed Feedback |
| 複数の報酬要素を考えたい | multi-objective bandit | Bandit based Optimization of Multiple Objectives on a Music Streaming Platform |
この記事では、アルゴリズムの課題1の「報酬確率分布が一定でない」に取り組んだ A Linear Bandit for Seasonal Environments を紹介します。
A Linear Bandit for Seasonal Environments
論文概要
A Linear Bandit for Seasonal Environments は、Benedetto et al. (From Amazon)から発表されたICML 2020 Workshopの論文です。論文の概要は以下のとおりです。
- contextual banditではstationaryな報酬分布を仮定するが、時間的に変化するnon-stationaryな報酬分布は想定していない。しかし、現実はnon-stationaryなものがほとんど。
- 本論文はnon-stationaryな報酬分布だけでなく、seasonallyな報酬分布も考慮した
- 本論文の手法では、Base BanditとShadow Bandit という2つのcontextual banditを用いて、報酬分布の変化に適応する
- シミュレーターによる実験において、non-stationaryの先行研究と比べて本論文の手法の性能が良かった
背景と動機
アルゴリズムの課題1でも言及しましたが、contextual banditでは、「報酬はある確率分布に従っており、それは時間変化しない」という環境(stationary)を仮定しています。しかし、実際は報酬分布が時間変化する環境(non-stationary)がほとんどです。本論文では、具体的に以下の例を挙げています。
- 日毎のプロモーションで、カートインするかどうかのベルヌーイ分布が変化する
- 一時的なイベントによってユーザーの嗜好が変化する(本論文はB2Cの音楽配信Amazon Musicを例に上げている)
また、報酬の分布が季節性(seasonally)を持っていることもあります。seasonallyの具体例として、定期的に発生するプロモーションなどが挙げられます。seasonallyでは、分布は時間経過で変化し、なおかつ再度同じ分布が到来するということを考えます。そのため、定期的に分布が変化するたびに再度学習するのではなく、適切に分布の変化を検知し、同分布の期間のログをすべて使用して学習することが望ましいです。本論文ではnon-stationaryに加え、seasonallyも考慮した手法を提案しています。
提案手法
本論文の提案された手法All-Season banditでは、Base BanditとShadow Banditと呼ばれる、役割が異なる2種類のcontextual banditが登場します。Base Banditは、ある報酬分布に対応したcontextual banditであり、複数存在します。このBase Banditの集合をBase Bandit 集合と呼びます。Shadow Banditは、直近のデータのみを学習したcontexul banditで、常に1つ存在します。本論文では、Base BanditとShadow Banditの具体的なcontextual bandit手法としてLinear Thompson Sampling (LinTS) を採用します。LinTS以外でも、ベイズ手法などを用いて報酬分布を推定する手法であれば、何を採用しても大丈夫です。
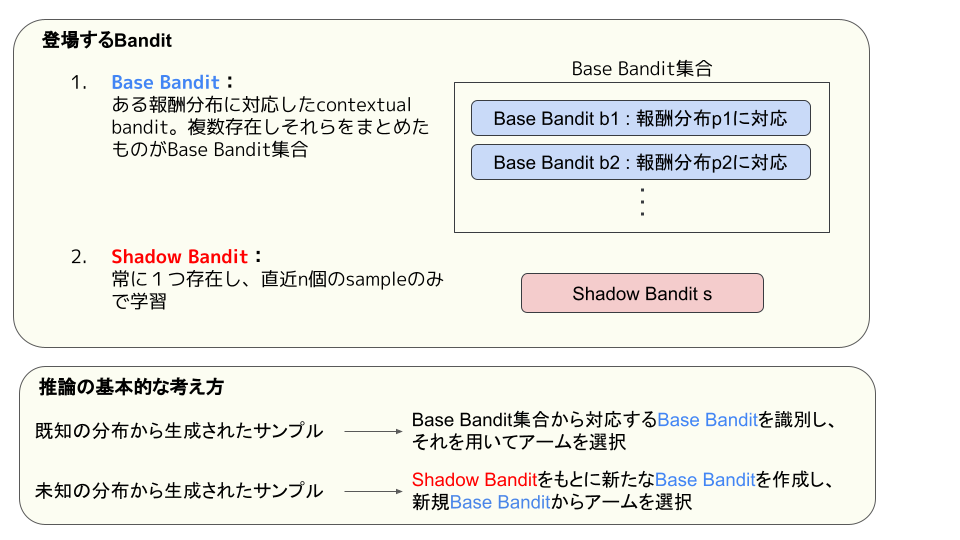
提案手法による、アルゴリズムの課題1「報酬確率分布が一定でない」の対処方法のイメージを説明します。
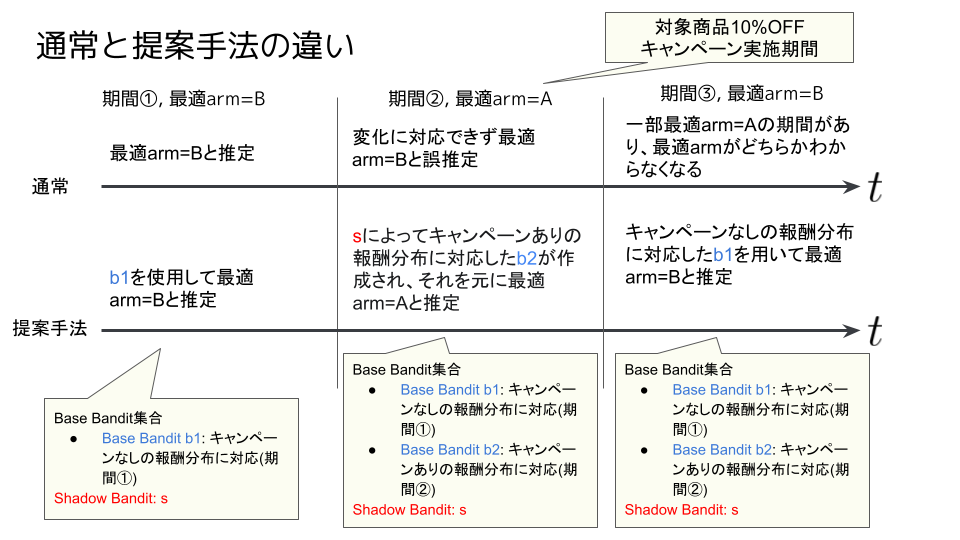
図1と同じ問題設定を考えます。その上で、以下の図3のように、ある期間はキャンペーンが実施され、その期間はキャンペーン情報を表示するUIパターンAが、それ以外はUIパターンBが最適armであるとします。この場合、通常は期間①で最適arm=Bと推定した結果を引きずり、期間②で最適armが変化しても対応できずにBを出し続けます。提案手法では、期間②で報酬分布が変化したことを検知し、shadow banditからキャンペーンありの報酬分布に対応したBase Bandit: b2を作成し、それを元に最適arm=Aと推定します。このように、分布の変化を検知して、分布に対応したBase Banditでarmを選択、もし分布に対応したBase BanditがなければShadow Banditから対応したBase Banditを作成するという流れで報酬分布変化に対応します。次に、より詳細なアルゴリズムレベルの説明をします。
バッチ単位で処理するAll-Season banditのアルゴリズム概要は以下のとおりです。
推論ステップ
の確率に従って、Base Bandit集合とShadow Banditの中から、使用するcontexual banditを選択します。jはBase Bandit集合の各要素とShadow Banditそれぞれの示すindexです。
- 選択されたcontextual banditを用いて、アームを選択し報酬を得ます。
学習ステップ
- 以下の手順でShadow Banditの更新と再作成を行います。
- もし推論ステップで一度でもShadow Banditが選ばれたら、そのShadow BanditをBase Banditに昇格し、Base Bandit集合に追加します。
- Shadow Banditを初期化し、バッチ内の直近 n 個のsampleで学習させます。
- 各Base Banditを、推論ステップで選択したsampleだけを用いて学習させます。
- Base Bandit集合のサイズが、予め設定した最大サイズよりも大きければプルーニング処理をします。プルーニング処理は以下のとおりです。
- Base Bandit集合の各要素を作成し、各ペアにおける事後分布のjensen shannon divergenceを計算します。
- jensen shannon divergenceの最も小さいペアのうち、事後分布の分散が大きいほうを削除します。
- 以下の方法で推論ステップで使用する確率
- 各contextual banditにおいて、バッチ内の全sampleに対する尤度
を計算します。
- 計算した各尤度を正規化することで確率
- 各contextual banditにおいて、バッチ内の全sampleに対する尤度
- 以下の手順でShadow Banditの更新と再作成を行います。
Shadow Banditは常に直近 n 個のsampleを学習するため、直近の傾向を把握しています。もし、未知の報酬分布が出現した場合は、Shadow Banditの尤度が大きくなり、次の推論ステップではShadow Banditが選択されやすくなります(図3の期間②のケースに対応します)。対して、既知の報酬分布であれば、Shadow Banditよりも学習データが多いため、対応するBase Banditの尤度がより大きくなるだろうと考えられます(図3の期間③のケースに対応します)。
しかし、既知の報酬分布であっても、誤ってShadow Banditが選択されると同じ分布に複数のBase Banditが作成されます。この場合、同一分布から生成されたsampleが複数のBase Banditで分散して学習されてしまい、上手く学習が進みません。この問題点を踏まえて、プルーニング処理があります。プルーニング処理は、Base Bandit集合の大きさが一定を越えると実施され、類似度の高いBase Banditペアの片方を削除します。
実験
本論文では、実験1:合成データを用いた実験 と実験2:MNIST・Fashion-MNISTを用いた実験 の2つの実験を行っています。 実験1では、適当に設定した正規分布に従う報酬分布を時間経過で変化させることを行いました。この実験から、次のことがわかり、意図通りAll-Season が時間経過に適応したと述べられています。 これまでに一度も現れていない報酬分布へ変化すると、Shadow Banditが選ばれる確率が1に近く、Shadow Banditが機能している。 既知の報酬分布へ変化すると、その報酬分布に対応したBase Banditが選ばれる確率が1に近く、新規にBase Banditが作られず追加学習ができており、seasonallyに適した動きをしている。 実験2では、MNIST・Fashion-MNISTを用いて、Sliding-Window LinTSや、BoB、DenBandなどの既存手法との性能比較を行いました。この実験を通して、All-Season Banditはどの既存手法よりも平均獲得報酬が高くなることがわかり、性能の高さを示しました。
まとめ
A Linear Bandit for Seasonal Environmentsの概要解説をしました。この論文では、contextual banditの課題点であるnon-stationaryに対して、複数のcontextual banditを組み合わせることで対応するという手法を提案しています。
contextual banditはシンプルであるために、自由度が高く課題に柔軟に対応できると思わせてくれた論文でした。 この論文で気になったのは、同一分布であっても複数のBase Banditが作成される可能性です。実験でどのような条件下でこの現象が観測されるのか、その影響はどの程度かを知りたかったのですが、言及されていなかったのが残念です。 追試をして、この問題点を分析できればと考えています。また、類似Base Bandit を削除するプルーニング処理も気になりました。類似度があるしきい値以上であるBase Banditペアは同一分布のデータから学習した可能性が高いです。そのため、このペアのどちらかを削除するのではなく、1つに統合させることでより学習速度を早めることができないかと考えました。
おわりに
今回のテックブログでは、最近MonotaROで注目しているbanditの概要と、banditを事業特性に合わせるための1つの手法である、All-Seasonの論文解説を行いました。
データサイエンスグループ(DS)では、検索や推薦、プロモーションといった分野におけるECサイトの課題においてデータマイニングや機械学習、最適化など技術を用いた施策、改善を行っています。これらの技術は日進月歩であるため、グループ内で新しいアルゴリズムや技術のキャッチアップを定期的におこなっており、具体的な取り組みとして、週に1回DS研究会と呼ばれる、論文をDSメンバーに共有する勉強会を実施しています。このブログで取り上げた論文もDS研究会で共有しました。banditアルゴリズムに関する論文は今回解説したもの以外にも多くあります。今後もDS研究会などで議論した内容を元に、MonotaROにあったアルゴリズムを開発し、ECサイトの改善に活かしていこうと考えています。
このようにデータマイニング、機械学習、最適化などのアルゴリズムを学びつつ、理論や知見を事業に活かし改善することに興味がある方は、データサイエンティストとのカジュアル面談に是非ご応募ください。