モノタロウのプラットフォームエンジニアリング部門 コンテナ基盤グループの宋 明起です。
私たちは、アプリケーション開発者からコンテナシステムの認知負荷を取り除き、アプリ開発に専念できるコンテナ基盤の構築と基盤を改善し、開発者はより楽に、より安全にアプリケーションのデプロイと運用できるように支援しています。

背景
モノタロウでは以下の記事にあるようにバックエンドのAPIをコンテナ化から始め様々なレイヤーの様々なアプリケーションをEKSの上で運用しています。
- EKSコンテナ移行のトラブル事例:ALBの設定とPodのライフサイクル管理 - MonotaRO Tech Blog
- EKSコンテナ移行のトラブル事例:推測するな計測せよ -CoreDNS暴走編- - MonotaRO Tech Blog
- EKSコンテナ移行のトラブル事例:FargateにおけるAZ間通信遅延の解消 - MonotaRO Tech Blog
EKSのノードについては運用負荷の軽減やセキュリティの観点でEC2よりもAWS Fargateの方が優れていると思い、Fargateを選んで運用するようにしましたが、AWS Fargateの場合、Fluent-bitをSidecarで運用する必要があり、次の課題がありました。
- Sidecar (ロギング、Datadog、DNS Cache)の実装がDeploymentになっていて、開発者の認知負荷が増えたこと
- アプリケーションのデプロイと起動が遅い
- Pods起動順序制御が難しい
上の課題を解決するため、ノードをEC2に切り替え、Sidecarで運用していたFluent-bitをDaemonSetで運用するように変えました。
EKSのFargateとEC2ノードについて詳細の話はまた別のブログでご紹介させていただく予定でございます。今回は、その中で、ロギングについてご紹介します。
Sidecarの場合は一個のアプリケーションに対して1つのFluent-bitが動いていたのですが、DaemonSetの場合では、1つのFluent-bitが複数のアプリケーションログを扱う必要がありました。
Fluent-bitをDaemonSetで動かすことで考慮した構成やテスト、そして、運用中発生したトラブルとそのトラブルの対応方法についてご参考になるように書いてみようと思います。
基本設計
方針
- Sidecarの場合、開発者は自分たちのアプリケーションに対してFluent-bit configの設定を管理するだけで良かったのですが、DaemonSetの場合は、複数のアプリケーションのロギングを扱う共有的なconfigになります。そのため、運用のコストと、障害のリスクを避けるため、各アプリケーションごとにconfigファイルを分け、開発者は自分たちのアプリケーションのロギングconfigのみに触れるようにしたい
- 同じく、Fluent-bitは複数アプリケーションのログを扱うので、Resource使用についてどのようなアプリケーションがどれくらいResourceを使うかをアプリケーションごとに特定しモニタリングができるようにしたい
構成
logging ├── configs │ ├── app-a.conf (Input、 Filter、 Output) │ ├── app-b.conf │ ├── app-c.conf │ ├── fluent-bit.conf (Service、 Metrics設定、共通filters、@INCLUDE app configs) │ └── parser.conf ├── daemonset.yaml └── kustomization.yaml (configMapGenerator)
- logging/configs/{アプリケーション}.conf : 各アプリケーション用Fluent-bit configは別のファイルにして、各開発者は自分のアプリケーションに対するConfigファイルのみに修正するようにしました。
- fluent-bit.conf : Fluent-bit service設定や、Metrics設定などsystem的なconfigが入っています。
- parser.conf: 共通的なParser処理をparser.confファイルに整理しました。
- daemonset.yaml: Fluent-bitのDaemonSet manifest。Fluent-bitが他のアプリケーションより先に配置されるように、DaemonSetに「priorityClassName: system-node-critical」設定をしました。
- kustomization.yaml: KustomizationのconfigMapGeneratorを利用して、2つのファイルにまとめました。
- configMapGeneratorでまとめるとマージの順番がRandomになっていて、Fluent-bit 設定より、アプリケーション設定が上に配置され先にロードされる問題がありました。そのため、Fluent-bit設定とアプリケーション用configを分け、Fluent-bit設定から、アプリケーション用configをincludeする方式でしました。 ちなみに、/fluent-bit/etc ディレクトリにconfigファイルを入れると、自動的に読み込まれるので、アプリケーション用configは自動的に読みこまれないように、別のディレクトリにマウントするようにしました。
- fluent-bit/etc/fluent-bit-config
- fluent-bit/configs/fluent-bit-apps-config
- configMapGeneratorで、configファイルが修正されると、自動的にhashSuffixが更新され、DaemonSetが再起動されるのですが、HotReloadの導入することで、configファイル名が変わらないようにdisableNameSuffixHash:trueを設定しました。
- configMapGeneratorでまとめるとマージの順番がRandomになっていて、Fluent-bit 設定より、アプリケーション設定が上に配置され先にロードされる問題がありました。そのため、Fluent-bit設定とアプリケーション用configを分け、Fluent-bit設定から、アプリケーション用configをincludeする方式でしました。 ちなみに、/fluent-bit/etc ディレクトリにconfigファイルを入れると、自動的に読み込まれるので、アプリケーション用configは自動的に読みこまれないように、別のディレクトリにマウントするようにしました。
サンプル
fluent-bit.conf
[SERVICE]
Flush 1
Grace 5
Log_Level info
Health_Check On
# 共有Parserファイル
Parsers_File /fluent-bit/etc/parsers.conf
# 各情報やmetricsを取得するためのHTTPサーバーを有効化
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_PORT 2020
# Bufferingデータ(Backlog chunkなど)の保存先を指定とBuffering metricsの有効化
storage.path /var/fluent-bit/state/flb-storage/
storage.metrics On
# Fluent-bit hot-realodの有効化
Hot_Reload On
[INPUT]
name fluentbit_metrics
tag internal_metrics
scrape_interval 2
[OUTPUT]
name prometheus_exporter
match internal_metrics
host 0.0.0.0
port 2021
## Include application config
@INCLUDE /fluent-bit/configs/*.conf
app-a.conf (Aアプリケーション用config)
[INPUT] Name tail DB /var/fluent-bit/state/flb_app_a_container.db Path /var/log/containers/app-a-* Tag <pod_name>.<namespace_name>.<container_name> Tag_Regex (?<pod_name>[a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)- Read_from_Head True Skip_Long_Lines On Parser crio storage.type memory [FILTER] Name parser Match_Regex ^.*sample-app-a.*\.sample\. Key_Name log Parser docker Preserve_Key False Reserve_Data False [FILTER] Name rewrite_tag Match_Regex ^.*sample-app-a.*\.sample\. Rule $name ^.*ACCESS_LOG$ app-a.sample.request false [OUTPUT] Name forward Match_Regex ^.*sample-app-a.*\.sample\. Host aggregator.example.com Port 24224 Retry_Limit False
Kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
...
configMapGenerator:
- name: fluent-bit-config
namespace: kube-system
files:
- configs/fluent-bit.conf
- configs/parsers.conf
- name: fluent-bit-apps-config
namespace: kube-system
files:
- configs/app-a.conf
- configs/app-b.conf
- configs/app-c.conf
- configs/util/json.lua
モニタリング
1つ(node)のFluent-bitが複数アプリケーションのログを扱うので、Fluent-bit resource使用率のモニタリングと、各アプリケーションごとのresource使用率もモニタリングができるようにしました。
- OpenMetricsから次のようなMetricsを取得し、Datadog側でモニタリングできるようにしました。
- 各Inputやfilterのbuffer memory使用率
- Memory buffer overflow モニタリング
- Retry record数
- Fluent-bitのエラー: Fluent-bitのエラー発生有無
- Input/Output Record数: ログ数
- Input file count:各ノードのFluent-bitが扱っているログファイル数
- hostごとにInput record数:各ノードのFluent-bitが処理しているログ数 (Per secondに閲覧可能)
- OpenMetricsのFluent-bit エラーでは検知できないエラーもありまして、Fluent-bitのログをGCPのCloud loggingに送信するようにして、Fluent-bitログの閲覧も楽にでき、モニタリングと、エラーログからアラート設定も可能になりました。
サンプル
fluent-bit.conf
[SERVICE]
HTTP_Server On
HTTP_Listen 0.0.0.0
HTTP_PORT 2020
storage.path /var/fluent-bit/state/flb-storage/
storage.metrics On
[INPUT]
name fluentbit_metrics
tag internal_metrics
scrape_interval 2
[OUTPUT]
name prometheus_exporter
match internal_metrics
host 0.0.0.0
port 2021
[INPUT]
# Fluent-bitコンテナログをtailする
Name tail
DB /var/fluent-bit/state/flb_logger_container.db
Path /var/log/containers/fluent-bit-logger-*
Tag <pod_name>.<namespace_name>.<container_name>
Tag_Regex (?<pod_name>[a-z0-9]([-a-z0-9]*[a-z0-9])?(\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-
Read_from_Head True
Mem_Buf_Limit 20MB
Skip_Long_Lines On
Parser crio
storage.type memory
Refresh_Interval 1
[FILTER]
Name parser
Match_Regex ^fluent\-bit\-logger.*\.kube\-system\.
Parser fluent_bit_log_parser
Key_Name log
Reserve_Data False
[FILTER]
# (量が多いので) Debugログは送らないようにする
Name grep
Match_Regex ^fluent\-bit\-logger.*\.kube\-system\.
Exclude severity ^debug$
[FILTER]
# Log entryにpod名追加
Name lua
Match_Regex ^fluent\-bit\-logger.*\.kube\-system\.
script /fluent-bit/configs/append-pod-name.lua
Call append_pod_name
[OUTPUT]
# Fluent-bitログをaggregatorを通って、GCP Cloud loggingに送信
Name forward
Match_Regex ^fluent\-bit\-logger.*\.kube\-system\.
Host aggregator.example.com
Port 24224
Retry_Limit False
Require_ack_response True
daemonset.yaml
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "2021"
ad.datadoghq.com/fluent-bit-logger.checks: |
{
"openmetrics": {
"init_config": {},
"instances": [
{
"openmetrics_endpoint": "http://%%host%%:%%port%%/metrics",
"namespace": "kube-system",
"metrics": [".*"]
}
]
}
}
障害
障害1. Memory overflowエラーが発生
クラスタのB/Gアップデートで、FargateからEC2ノードに段階的にアプリケーションを移動してみたのですが、50%のリリースで、以下のようなメモリーエラーが発生、ロールバックしました。
[input:emitter:emitter_for_rewrite_tag.21] error registering chunk with tag: appslog.app-a.request
原因: Input (tail)にMem_Buf_Limitを設定したのですが、各Filter(rewrite_tag)にもMemory buffer設定が必要でした。default値は10mbで、rewrite_tag filterが10mb以上のメモリを使うと上のエラーが発生します。
対応:
- 各rewrite_tag filterにEmitter_Mem_Buf_Limitを50mbに設定しました。
- flush intervalを「1」に調整することでメモリー使用率調整ができた。(Fluent-bit 2.xではdefualt設定は5だったのが、Fluent-bit 3.xではdefaultで1になっています)
再現:
Nodeに入って、大量のログを出力してみると問題を再現することができました。
LOG='2024-02-16T01:13:40.873097286Z stdout F {...}'
FILE_PATH='/var/log/pods/app-a_app-a-756b8ddd-gqcs7_e17ac0d7-19e8-440b-bb4c-1086c9234cb0/app-a/0.log'
while true; do echo $LOG >> $FILE_PATH; done
エラーログ: [input:emitter:emitter_for_rewrite_tag.21] error registering chunk with tag: app-a.app-a.request
調査: メモリー使用率を確認してCapacity Planningする
- Fluent-bit podの中から、次のコマンドで、Fluent-bit memory dumpを実行(ログに出力)し、memory使用の詳細確認ができました。
- $ kill -CONT $(pgrep fluent-bit)
- rewrite_tag filterにEmitter_Nameを設定して、Memory dumpからどのようなメモリーかを分かりやすくしました。
メモリー使用率を確認するため、rewrite_tag filterのEmitter_Mem_Buf_Limitを多めに100mbに設定と、2つのTerminalを開いて、
(Terminal 1) Fluent-bit podの中にShellで入って、以下のコマンドを実行することで、毎秒Fluent-bit memory dump をログに出力することができます。
$ watch --interval=1 kill -CONT $(pgrep fluent-bit)
(Terminal 2) Fluent-bit ログをモニタリングしながら、
$kubectl logs fluent-bit-logger-w7mrt -f | grep -5 app-a.app-a.request
以下のようなコマンドで、Sleep値を調整しながら、何log per secondでログ出力できるか確認とメモリー使用率も確認できます。
// 680/sec程度ログを出力する (while sleep 0.001; do echo $LOG >> $FILE_PATH; done) & time (sleep 180; kill $!)
Emitter_Mem_Buf_Limitのdefault 10MBでは約500/secのログを処理できることが確認できました。
// 680/sec程度ログを出力する
Ouptut:
app-a.app-a.request (emitter)
│
├─ status
│ └─ overlimit : no
│ ├─ mem size : 11.0M (11497456 bytes)
│ └─ mem limit : 95.4M (100000000 bytes)
--
├─ down chunks: 0
└─ busy chunks: 0
├─ size : 0b (0 bytes)
└─ size err: 0
参考:
Dump Internals / Signal [https://docs.fluentbit.io/manual/v/1.5/administration/dump-internals-signal]
障害2. 大量のログが欠損になっている (refresh_interval)
LBのアクセスログとApplicationのログを比較してみると、大量のログが欠損になっていることが分かりました。
K8s 基本設定だと、ログファイルは10Miごとにローテートされ、5つまでのログファイルを保管します。
原因:Fluent-bitのログファイルを読み取るサイクルよりも、ログファイルローテートの方が早くて、間のログファイルを飛び越えた。
対応:Tail Inputのrefresh_intervalを「1」に設定する
調査:
ログファイルをウォッチする秒間隔(Refresh_Interval)の Defalut値は 60秒。 Defalut 60秒間隔でログファイルをウォッチしていて、60秒以内でログファイルが2回以上ローテートされると、ローテートされたログファイルが検知できず、ログ欠損に繋がる可能性がある。
ログファイルリストの更新(refresh)が実行される前、ログファイルがローテートされると欠損になる例、

再現するには、refresh_intervalを、逆に、約300sなど幅広く設定して、手動でログファイルを何回かローテートしてみると、間のログファイルが収集できないことを確認できます。
Refresh_Intervalをより短く設定すると、ログファイルリストの更新(refresh)サイクルの間にログファイルがローテートされ読み込まれない問題を解決できます。
変更後、CPU使用率と、Memory使用率もモニタリングしてみたのですが、あまり変化はありませんでした。

*HotReload導入
Fluent-bitのconifgを更新する際にPodの再起動を行っていますが、再起動前のPodがログファイルのどの位置(offset)まで読んだのかをローカル(Node)DBで記録しています。しかし、新しいPodの起動前にログファイルがローテートされると、ローテート前ファイルの記録されたOffsetから最後のログまでが欠損になる可能性があることが確認できました。
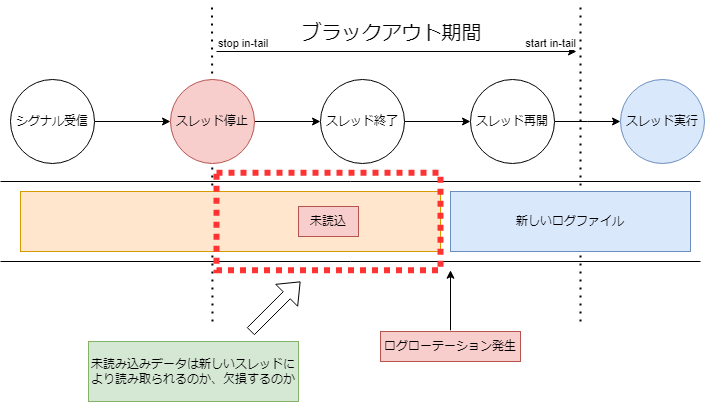
ですので、そのDowntimeを短縮するため、HotReloadを導入し4秒かかった再起動の処理を1秒に短縮できました。
障害3. まだ一部ログが欠損になっている (Prestop)
まだ、LBログとアプリケーションのログを比較してみると、一部ログが欠損になっていることがわかって調査をしました。
原因:DaemonSet pod(Fluent-bit)がApplication podより先にTerminatedされ、その後アプリケーションが出したログは拾えなく欠損になる。
対応:lifecycle.preStopを105秒に設定して、SIGTERMを遅延させ、Fluent-bitがapplicationより後で終了するようにしました。
再現:ログ欠損の時刻と、Karpenterの動作時刻が一致することが確認でき、以下のテストをしてみました。
Applicationにテストアクセスを流し続け、Application podのログと、Fluent-bitログをモニタリングをしてみました。
Application podのログモニタリング
$ kubectl logs test-app-a-77d446bddc-8x444 -f
Fluent-bitログモニタリング
$ kubectl logs fluent-bit-logger-sxfwv -f
そして、そのapplicationが乗せているノードをDrainしてみると、
$ kubectl drain ip-10-121-78-15.ap-northeast-1.compute.internal --ignore-daemonsets --delete-emptydir-data
Fluent-bitが先に終了され、その後、applicationはより長くログを出していることを確認できました。
調査:
Try1) 「daemonset-eviction-for-empty-nodes」、「daemonset-eviction-for-occupied-nodes」を設定してみる。(X)
ClusterAutoScalerにある、Nodeが空になってからDaemonSetが最後にteminatedされるようにするoptions、「daemonset-eviction-for-empty-nodes」、「daemonset-eviction-for-occupied-nodes」はKarpenterの場合は適用できませんでした。
Try2) terminationGracePeriodSecondsを300秒に設定する (X)
terminationGracePeriodSecondsはSIGTERM遅延出来なく、設定したterminationGracePeriodSecondsより先にFluent-bitはSIGTERM signalを受け、ログを読み込む処理を止まってしまい、その後出したログは処理しませんでした。

Try3) SIGTERMを遅延させるため、prestopを設置しました。(O)
(テストのため) 以下のようにFluent-bit DaemonSetのpreStopを5分に設定して、またテストしてみると、Fluent-bitがapplicationより後Terminatedされ、ログ欠損もなくなったことが確認できました。
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 300"]
ですので、各Applicationのprestopも含め、terminationGracePeriodSecondsを100以内に設定するようにして、Fluent-bit DaemonSetには、
prestop : 105
Fluent-bit Grace : 5 (default)
のように設定し、Fluent-bitがapplicationより先にterminatedされログ欠損になる問題を解決できました。
[FAQ]
Q: EKSなのに、aws-fluent-bit imageではなく、公式のFluent-bit イメージを利用するのはなぜ?
A: 導入するとき、aws-fluent-bit imageのFluent-bit versionが1.xで、prometheus支援ができませんでしたので、2.xのバージョンを使う必要がありました。 現在、aws-fluent-bitも、Fluent-bit 3.x versionもリリースされたので、またアップデートを検討する予定です。
Q: Dockerhub pull rate limit (outbound IP当たり6時間に100回)の問題はないの?
A: Deploy, Scale-in, Scale-outでlimitに当たってしまう可能性があるので、ECRにイメージミラーリングをして使うようにしました。
Q: Filterなどの処理はAggregator(FluentD)におくべきなのでは?
A: Aggregator側にrefactoringも含め、filterなどのtransform処理はAggregator側に移行する計画をしています。
Q: 各Application configで設定するメモリー使用率はどう把握してるの? DaemonSetに正しいresourceをrequiredしているの?
A: 現在は乗せているapplicationが少ないので手動で確認とモニタリング・アラートを設定をしているのですが、Configsに設定されているメモリーを自動計算してテストするCIを導入する予定です。
Q: Self-serviceで各開発者がconfigを作成や変更する場合、そのconfigが正しく設定できているかどう検討できる?
A: 現在は開発者はconfig 作成や変更後、Pull-requestを作成し、基盤メンバーがレビュー・承認・マージをしています。そして、Hotreload プロセス中で --dry-run テストして、syntaxなどの適用に問題ないかをチェックしています。
今回の記事で紹介しきれなかった様々なトラブルも含め、問題をDebuggingしながらDeamonsetと、Fluent-bitについてより深く学ぶことができました。
当記事を通じてMonotaROに興味を持っていただいた方は、カジュアル面談もやっていますのでぜひご連絡ください。 チームの採用募集も合わせてご覧ください。