こんにちは。
この記事では、2024/5/22に開催された「アーキテクチャを突き詰める Online Conference」で弊社CTOの普川がお話しした内容(ビジネスの構造をアーキテクチャに落とし込みソフトウェアに可変性を注入する〜モノタロウ基幹システム刷新の実践例)を、現場目線から改めてご紹介します。
なお、本稿の執筆は頼と尾髙が分担しておりまして、途中で急に文体が変わったな?と違和感を持たれることもあろうかと思われますが、ご容赦いただけますと幸いです。
本稿をさらに深掘りするイベントを10/4(金)に開催いたします。
ご興味ある方はぜひご登録ください。
https://connpass.com/event/328360/

問題領域は関連システムの密結合点
モノタロウの基幹システムには、受注・配送・発注というドメインがあります。
各ドメインはそれぞれ、商品の在庫(在庫状況)に関する属性を持ちますが、それらの属性はただ1つのテーブルに保存されています。

そのレコード数は5000万件を越え、
関連するユースケースは更新で80以上、参照では730以上あります。
また、各ドメインはそのデータ構造に依存してしまっているため、うっかりデータ構造を変更しようものなら入出荷が止まる等、お客さまに商品を約束通りお届けできないリスクが高まります。
つまり、モノタロウのビジネスの基本業務である在庫状況の管理は、ただ1つのテーブルに依存している状況と言えます。。まさに神テーブル。
ですが、その神が持つのは在庫の状態のみであり、「なぜその状態となったか?」を調べる術は持ちません。
さらには、ビジネスの成長に伴う変化に追随できておらず、利用者は業務上必要な数値を独自に導出する必要があります。
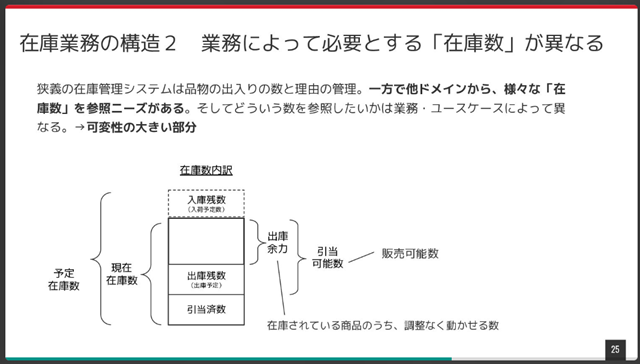
必要な数値を導出するにあたっては、他のテーブルと結合して参照するなどのユースケースが生じ、「在庫状況を管理する」という文脈において担保すべき不変条件の範囲を曖昧にしています。
これこそがまさに「不要な複雑性が付随し、本来取り組むべき課題、複雑性に集中できない」状況の深刻さを示しており、過日のイベントで普川がお話しした内容です。
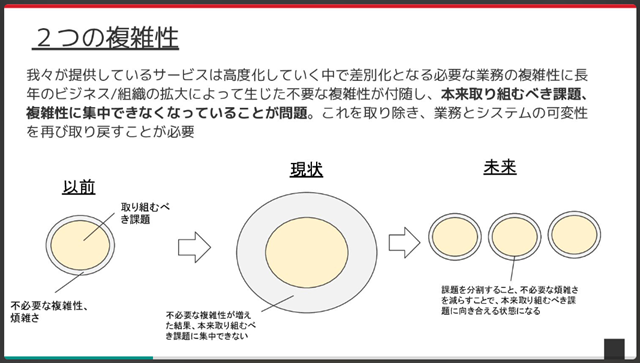
分割を試みる
この在庫状況を取り巻く問題は、その複雑さ(関連システムの密結合点、担当チームが明確に決まっていない、そもそもドメインの存在も不確か)から積年の課題となっていましたが、「業務とシステムの可変性を取り戻すには課題を分割する必要があり、分割するには「在庫状況問題」を避けては通れない!」ということで、もはや不要な複雑性の本丸的な扱いとなった在庫状況問題に取り組むこととなりました。
我々が取り組んだ手順は下記のとおりです。
- 在庫状況に関連する更新ユースケースを網羅的に洗い出す
- どのドメインがどの属性を更新しているか分類する
- 属性のオーナー候補ドメインを仮定する
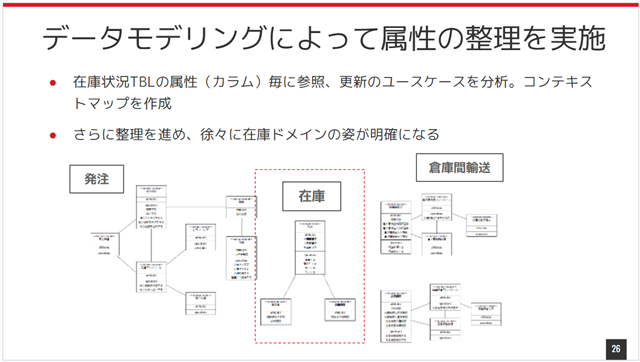
この手順は、いわゆる「神クラス」を分割する常とう手段に似ていますね。
また、属性のオーナー候補を仮定するにあたっては、当時は(今も)存在が不確かな「在庫ドメインとその属性」を仮定し、各更新ユースケースが破綻なく処理できることを慎重に確認しました。
具体的には下記のような取り組みを行いました。
- 各ドメインシステムの有識者が参加する大規模なワークショップでモブプログラミングを行い、在庫ドメインの属性と責務を仮実装してそのイメージをつかむ
- 更新ユースケースを網羅的にシーケンス図に起こしてドメインシステム間のメッセージングを確認する

仮実装やシーケンス図によって表出した課題を各ドメインと密に調整することで、ついに「在庫ドメインはあります!」という仮説に至りました。
これまで避けていた在庫状況問題にようやく切り込むことができました。
最初のモデルを手に入れる
仮説を立てられたら次は実証ですね。
実証では最速で動くものを!と言いたいところですが、我々は下記の理由からドメイン駆動設計(DDD)の手法でアプローチすることにしました。
- 問題領域は基幹業務
- 自社在庫の管理を柔軟に行うことはモノタロウの競争優位性の源泉となり得る
- 最大の目的は、業務とシステムの可変性を取り戻すこと
とはいえ社内にDDDのエキスパートがいるわけでもなく、ドメインエキスパートも開発者も基幹システムの案件開発と新システムのモデリングを並行して行うことが難しい、、といったよくある(しかし強力な)足踏み要因を取り除くため、専任チームを結成してAWSさまにご支援いただくことにしました。
(AWS プロフェッショナルサービス)
チームはまずイベントストーミングで在庫状況管理業務プロセスのハッピーパスをモデリングしました。(カタカナばっかり!)
前段として、フルフィルメント(受注~出荷までの一連のプロセス)全体の業務イベントを可視化する大規模なイベントストーミングが開催されビッグピクチャーが作成されていたので、これをインプットとしました。

ビッグピクチャーは大きなプロセスを俯瞰するには適していますが、個々の集約を詳しく分析するには大きすぎて扱いづらいので、チームは在庫状況の業務領域に絞ってイベントストーミングで分析を重ねました。
ビッグピクチャーでは業務イベントを追うにとどまるのに対して、このフェーズではそのイベントがどのように発生したか?を細かく分析します。
ここで作られる図を社内では「プロセスモデル」と呼びます。(絶賛布教中)
さらに、こうして見えてきた在庫状況管理のプロセスモデルからドメインモデルを導出します。
ドメインモデルを導出するには、
- プロセスモデル上に現れる「集約」の付箋を取り上げ
- 集約に対するコマンドを「振る舞い」とし
- 振る舞いに必要となる「属性」を推定し
- さらに属性を「エンティティ」と「値オブジェクト」に分けて集約を構成
するのですが、、
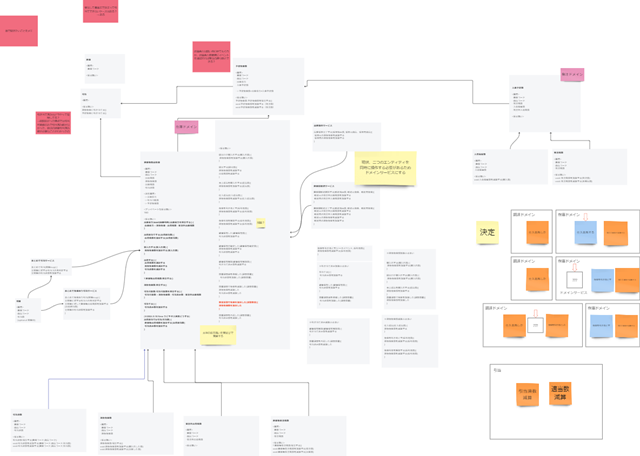
(プロセスモデルとドメインモデルの世代が合っていないので図が整合しませんが、イメージとしてご参考ください)
今さら見ると「めっちゃわちゃわちゃしてるし、なんか別ドメインの知識が混ざりこんでるな、、」という感想しかないですね。。若かりし頃に書いたコードを見ている気分です。
ちなみにこの頃は完全にAWSさまにリードしていただいておりましたが、モデルが稚拙なのはAWSさまに問題があったからでは決してありません。
きっとコーチングしながら「このモデル、、伸びしろしかないな」などと思われていたことでしょう。
忍耐強く導いていただきまして感謝しかありません。
レイヤードアーキテクチャに沿って実装
導出されたドメインモデルをコードに落とし込むのに、私たちはレイヤードアーキテクチャを採用しました。アプリを4つの層に分けて実装しています:
- ビュー層(プレゼンテーション層)
- ユーザーインターフェースを担当します
- 具体的に、イベントを受け付けるイベントハンドラがここに実装されます
- アプリケーション層(ユースケース層)
- ビジネスロジックを実行し、ユースケースを管理します
- ドメイン集約をリポジトリから読み出し、適切な振る舞いを呼び出す処理がここに実装されます
- ドメイン層
- ビジネスルールやドメインモデルを定義します
- 在庫集約や、リポジトリのインタフェースがここで定義されます
- インフラストラクチャ層
- データベースアクセスや外部システムとの連携を担当します
- リポジトリの実装はここです
4つの層を素直に実装しようとすると、ドメイン層が集約の永続化のためにインフラストラクチャ層を参照し、データベースなどの外部システムの実装都合に依存してしまいます。
ここでは依存関係の逆転を適用して回避しています。
リポジトリのインタフェースをドメイン層で定義し、インフラストラクチャ層で実装することで、ドメイン層からインフラストラクチャ層の実装への依存を回避しました。
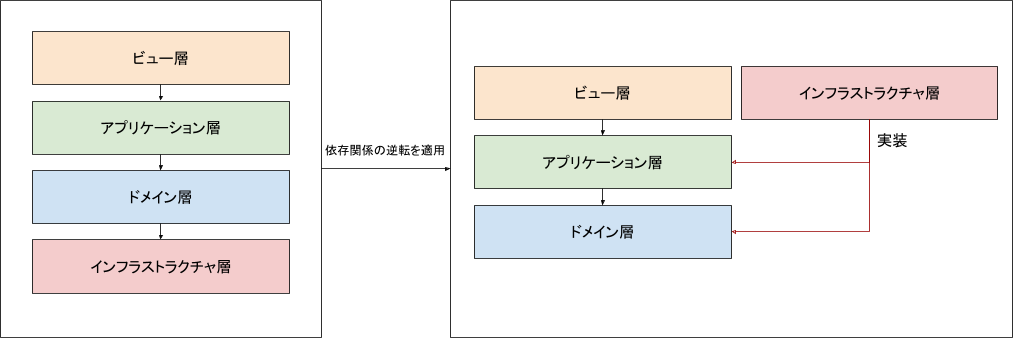
入荷イベントの処理フロー
ここで入荷イベントを例にして各層の処理の流れを簡単に説明します。
- ビュー層のイベントハンドラが倉庫から入荷のイベントを受け付け、アプリケーション層の入荷ユースケースを呼び出します。
- アプリケーション層の入荷ユースケースが集約をリポジトリから読み出し、集約の入荷処理(振る舞い)を呼び出します。
- ドメイン層の在庫集約が入荷の振る舞いによって、在庫数を加算します。
- アプリケーション層の入荷ユースケースが集約をリポジトリに保存します。
レイヤードアーキテクチャのメリット
レイヤードアーキテクチャを採用して感じた最大のメリットは、アプリの保守性の向上です。
- 各層の責任と関心事が独立しているので、コードが整理されやすくなり、システム全体の理解が容易になります。
- 層間の依存関係が限定されることによって、コードの変更の影響範囲も限定され、変更容易性にも繋がります。
実装初期のMVPは、APIGateway経由で同期的にリクエストを受け付けていました。
実装が進み、非同期でイベントを受け付けるように変更した際には、ビュー層にあるハンドラの書き換えのみで済みました。これもレイヤードアーキテクチャがもたらした変更容易性のおかげです。
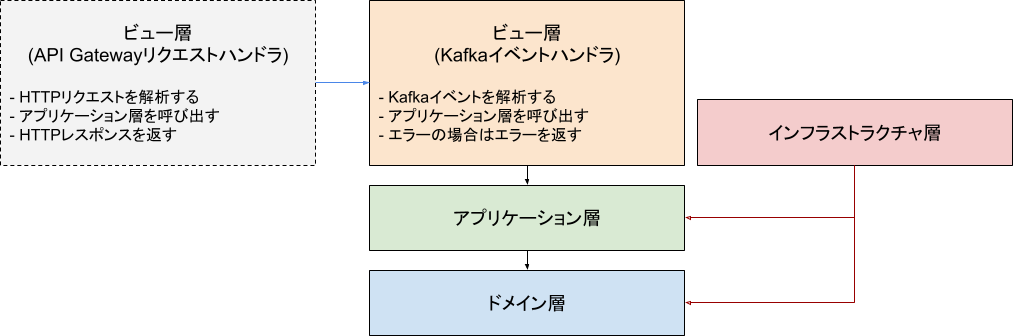 ビュー層の実装変更前後のイメージ
ビュー層の実装変更前後のイメージ
モデルを洗練させる(業務領域と向き合う)
一通りのモデルができ実装も済んだところで、次はユースケースの網羅性を上げることと、モデルを洗練することに取り掛かりました。
具体的には、、と説明したいところですが、このフェーズでは業務・モデル・コードを往復しながら、「本当にこれでいいんだっけ?」「この業務の意図に照らすと別のあり様があるのでは?」といった正解のない禅問答のようなやりとりが続きます。
禅問答を例示すると、
- プロセスモデルと実装を直接紐づけるにはどのようなモデルで表現するのがよいか
- ユースケースとドメインモデルの属性の関係はどう表現すべきか
- 属性は集約をどのように構成すべきか
のような問いが印象的でした。
これらの答え(とは言えないが一定満足できる結果)に至るには相当の試行錯誤がありましたが、ドメイン知識を得てモデリングに慣れていくことで「より良いモデルとはどういうものか」を感覚的に理解できるようになってきました。
その過程で、業務上の概念を構造化したモデル(概念構成図)で考えを整理するようになり、これはプロセスモデルからドメインモデルを導出し、その構造を洗練させるのに大いに役に立ちました。
概念構成図ではドメインロジックを中心に置き、ドメインロジックを起動する業務イベント(ユースケース)、ドメインロジックにより更新される集約と、複数の集約を合成/集計して作られるリードモデルを表現しました。(絶賛試行錯誤中)
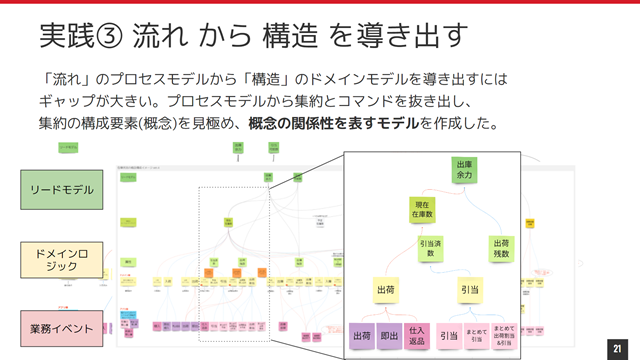
一方、システムアーキテクチャも順調に拡大していき、最初期のハッピーパスのみを実現する素朴な実装はイベント駆動アーキテクチャとCQRSパターンで構成されるようになりました。
直近では商用環境相当のデータ量を処理できるようになり、着々と実証を進めています。
「良いソフトウェア」であるために
モデリングの結果をレイヤードアーキテクチャに沿って実装するだけでは、「良いソフトウェア」を作るのに不十分だとチームは考えています。
ソフトウェアの「質」を高めるために、設計原則の共有や、定期的にリファクタリングなどの取り組みを実施しています。
設計原則の共有
チーム内で設計原則のすり合わせ会を定期的に行っています。
初回は社内ワークショップの資料(リファクタリングを文化にする 〜組織が技術的負債と向き合うワークショップ〜 - MonotaRO Tech Blog)を振り返りながら、「良いコードとは何か」の議論から始めました。重要なポイントの一つとして、テスト容易性を向上するためには、単一責任の原則の厳守と依存性の注入の活用が大事という認識を合わせました。
最近では、こちらのブログ記事を参考に「良い設計とは何か」について議論しています:7つの設計原則とオブジェクト指向プログラミング。
良い設計についての共通認識がチーム内で形成されると、良いソフトウェアを作る合力も生み出されます。
リファクタリングを定期的に実施
チームは、ソフトウェアの設計がその時点での最適(に近い)か、良い設計になっているかどうかを確認し、必要なリファクタリングを毎スプリント行っています。リファクタリングのアイテムを特定して、ストーリーポイントを割り振って対応しています。
アプリケーション層のリファクタリングの一例
実装初期の段階では、各ユースケースごとにServiceを定義し、各Serviceの実行メソッドに共通する処理がありました。リポジトリから集約をロードし、イベントを適用し、集約を保存するという流れです。この処理の流れがユースケースにかかわらず共通していることに気づき、リファクタリングを行うことにしました。
リファクタリング前のコードのイメージ
// ... func (s *AService) 実行(集約ID AggregateID) { 集約:= s.repository.集約をロードする(集約ID) 集約.振る舞いX() s.repository.集約を保存する(集約) } // ... func (s *BService) 実行(集約ID AggregateID) { 集約:= s.repository.集約をロードする(集約ID) 集約.振る舞いY() 集約.振る舞いZ() s.repository.集約を保存する(集約) } // ...
リファクタリング後のコードのイメージ
単一の集約に対してイベントを起こす処理をすべてSingleEntityCommandServiceというサービスが処理するようにしました。ユースケースごとに異なるコマンドを渡すことで、異なる処理を呼び出すことができます。
// ユースケースによって変わらない部分 type SingleEntityCommandService struct { repository Repository } func (s *SingleEntityCommandService) 実行(コマンド Command) { 集約 := s.repository.集約をロードする(コマンド.集約ID()) コマンド.適用する(集約) s.repository.集約を保存する(集約) } // ユースケースによって変わる部分 func (c ACommand) 適用する(集約 *Aggregate) { 集約.振る舞いX() } func (c BCommand) 適用する(集約 *Aggregate) { 集約.振る舞いY() 集約.振る舞いZ() }
メリット
- 共通の処理を
SingleEntityCommandServiceに集約することで、コードの重複が減り、再利用性が向上しました。 - コマンドの処理フローが統一されるため、メンテナンスが容易になりました。
- 単一の集約を操作するコマンドを追加する際には、
Commandインタフェースを実装するだけで良く、サービスクラスを変更する必要がありません。そのため、拡張性も向上しました。
では最初から前述の抽象を適用しておけば、リファクタリングに手間をかけずに済んだのではないかと疑問に思うかもしれません。
ユースケースが3つくらいしかなかった初期段階では、後続のモデリングの結果がまだ見えていなかったため、早計に抽象化しなかったのです。しかし、モデリングが進むにつれてユースケースがどんどん増えてくると、重複が目立つようになり、リファクタリングの必要性が出てきました。
リファクタリングの時間を確保することで、開発の初期には予見できなかった技術的負債を返済することができ、保守性の向上に寄与できました。
今後の展望
ここまでは私たちチームの活動にフォーカスしてご紹介させていただきましたが、この活動はMonotaROにおける基幹システムの分割・モダナイズ活動の一環です。
在庫ドメインではある程度動くものができ、商用環境への展開も視野に入ってきましたが、これから始める業務領域もまだまだ多くあります。
また、個別の業務領域と併せて、基幹システム全体の構造とマスタデータ管理も最適化していく必要があります。
これまでの営みで得られた知見を再利用できるようドキュメントを残し、ワークショップを開催するなどしていますが、これらの難題を推し進めるにはより多くの仲間が必要です。
この長文をここまで読み進めていただけたあなたなら活躍できる場所がきっとあります。MonotaROにはエンジニアの好奇心を満たす(あるいはMonotaROとともに成長できる)舞台があります。
まずは気軽にお話しさせていただきたく、、2024/10/4(金)にオフラインイベントを開催いたします!
本稿でご紹介した内容に加えて、AWSさまをお招きしたトークセッションを予定しておりますので、ぜひぜひご登録ください。
現地でお話しできることを楽しみにしております!!
https://connpass.com/event/328360/