こんにちは。データ基盤グループ データエンジニアリングチームの宮口です。 この記事ではGoogle Cloud Platform(以下、GCP)のサービスの1つであるGoogle Kubernetes Engine(以下、GKE)のクラスタを手動アップグレードした話を紹介します。
私が所属するデータエンジニアリングチームでは、社内システムに保存されたデータをGCPのBigQueryにニアリアルタイムで同期するシステムや、BigQueryに保存されている大容量のデータを低レイテンシなAPIとして提供するシステムなど、モノタロウのビジネスを裏側で支えるシステムの管理を行っています。それらのシステムは全てのコンポーネントをコンテナ化しており、その実行環境としてGKEを採用しています。 また、それとは別に社内でGKE共通環境と呼んでいる、マルチテナント方式のクラスタによるアプリケーション実行基盤を提供していたりもします。 ※GKE共通環境に関してはこちらの記事でも紹介しています。
普段はKubernetesのマネージドサービスであるGKEを利用することで、Kubernetesを運用する上で必要な作業を省力化しています。クラスタのアップグレードもGKEの機能を利用して夜間に自動で実施するようにしているのですが、この後紹介する内容が原因で自動アップグレードが停止し、手動アップグレードの必要にかられました。
少し前の話にはなりますが、本記事では手動アップグレードを実施することになった原因と、その際に得られたTipsなどをご紹介できればと思います。
前提情報・知識
本題に入る前に前提となる情報をいくつか説明します。本題は手動アップグレードからになりますので本題を知りたい方はそちらから読み進めてください。
GKEクラスタ
まずは、データエンジニアリングチームで運用しているGKEクラスタについてです。
データエンジニアリングチームでは作業当時で15個のGKEクラスタを管理していました。自チームでのみ利用しているシングルテナントのクラスタもあれば、GKE共通環境のように不特定多数のユーザーが利用しているマルチテナントのクラスタもあったりと、利用者も構成も様々なクラスタが存在している状況でした。
CDツール
次にデータエンジニアリングチームで利用しているデプロイツールに関してです。
データエンジニアリングチームでは継続的デリバリーを実現する方法としてGitOpsを採用しており、その実現手段としてArgoCDを使用しています。
Kubernetesのマニフェストなどインフラの構成に関わるものをアプリケーションのコードとは別のインフラ用のリポジトリに保存しておき、インフラリポジトリへの変更内容をArgoCDでGKEにデプロイする、といった使い方をしています。
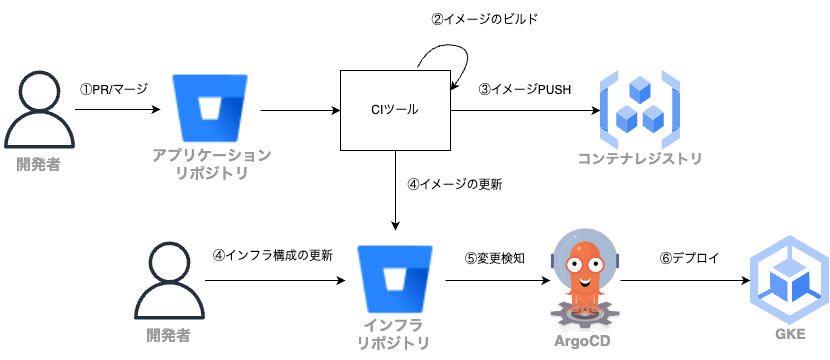
詳細は後ほど紹介しますが、今回はこのArgoCDが原因で手動アップグレードを実施することになってしまいました。
Kubernetes Deprecation Policy
最後にKubernetes Deprecation Policy(非推奨化ポリシー)についてもお話します。
Kubernetesは自身のバージョンをセマンティックバージョニングに従い x.y.zの形式で表現しており、xはメジャーバージョン、yはマイナーバージョン、zはパッチバージョンを意味します。
Kubernetesではマイナーバージョンが上がる毎に利用の少ない機能の非推奨化や廃止を実施する場合があり、その際はポリシーに従い実施されます。(詳細はKubernetes Deprecation Policyを参照ください)
以前少し話題になりましたが(私の観測範囲だけの話かもしれません)、v1.22のタイミングでは削除されるAPIの中にはIngressのextensions/v1beta1やnetworking.k8s.io/v1beta1など利用者が多いと思われるAPIも含まれており、削除による影響は大きかったと思われます。
データエンジニアリングチームでもそれらのAPIは利用していたので、APIのバージョンをアップグレードする必要に迫られました。
なぜ手動対応する必要があったのか
前置きが長くなってしまいましたが、ここからが本題になります。
まず、手動対応することになった原因を一言で説明すると、ArgoCDが削除予定のAPIを呼び出したことで、GKEのDeprecation Insightsという機能によって自動アップグレードが一時停止してしまったため、になります。
ではDeprecation Insightsがどういった機能かというと、これはGKE上のアプリケーションが次のマイナーバージョンで削除予定のAPIを利用していないかを検出する機能です。削除予定のAPIを利用している場合、クラスタをアップグレードするとAPIが利用できなくなりアプリケーションが動作しなくなる恐れがあります。GKEではこれを事前に防ぐ仕組みとしてDeprecation Insightsが提供されており、削除予定のAPIの利用を検出した場合は警告を表示して自動アップグレードを一時停止します。
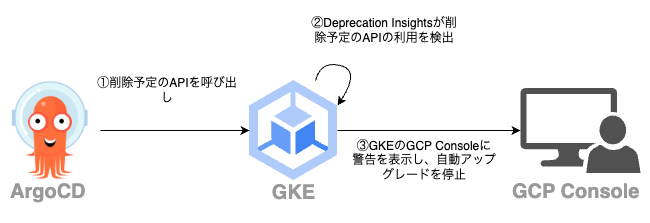
データエンジニアリングチームの管理するアプリケーションでも削除予定のAPIを利用していたのですが、事前にAPIのバージョンをアップグレードして削除予定のAPIは利用しないようにしていました。にもかかわらずDeprecation Insightsにより削除予定のAPIが検出され続けており、調査を進めたところArgoCDが原因だということが分かりました。
ArgoCDのリポジトリでもこの件はIssueが上がっており、それによるとArgoCDはデプロイ先のクラスタで利用可能なリソースに対して監視を確立するため全てのAPIを呼び出すようです。そのため削除予定のAPIも呼び出されてDeprecation Insightsに検出されたというのが、自動アップグレードが停止した原因でした。
このArgoCDの挙動自体は不具合ではなく正常なもので、ArgoCDのバージョンをアップグレードするなどしても解決する見込みはなさそうだったので手動でのアップグレードを決めました。
手動アップグレード
では手動アップグレードをどのように行ったかも紹介します。
といってもGKEでは手動アップグレードの手順自体は複雑な作業ではなく、基本は公式ドキュメントに記載されている内容に沿って実施しました。
公式ドキュメントにも記載がありますが、クラスタのアップグレードはGCPのCLIツールであるgcloudコマンドを使用するか、GCPのコンソールからアップグレードを行うかの大きく2つの方法があります。
gcloudコマンドによりアップグレードを実施してもよかったのですが、クラスタにより構成が様々でアップグレード時のパラメータも異なることや、gcloudコマンドでは気軽に手元で実行できるので、誤って意図しないクラスタをアップグレードする危険もあったため、コンソールからアップグレードすることにしました。ただ、今思えばクラスタの数も多かったのでgcloudコマンドを利用したスクリプトを作成するなどしておけば楽だったかなと思っています。
実際に手動アップグレードした際は以下の手順で実施しました。 コントロールプレーンのバージョンをアップグレード 各ノードプールのバージョンをアップグレード ノード数を確認して数が多い場合はmax-surge-upgradeの値を変更 バージョンをアップグレード
コントロールプレーン
まず、コントロールプレーンのアップグレードに関してです。 Kubernetesは大きくコントロールプレーンとワーカーノードと呼ばれる2つのノード群で構成されており、コントロールプレーンはKubernetesのコアコンポーネントが動作しているノードでワーカーノードはユーザーが管理するノード、という構成になっています。
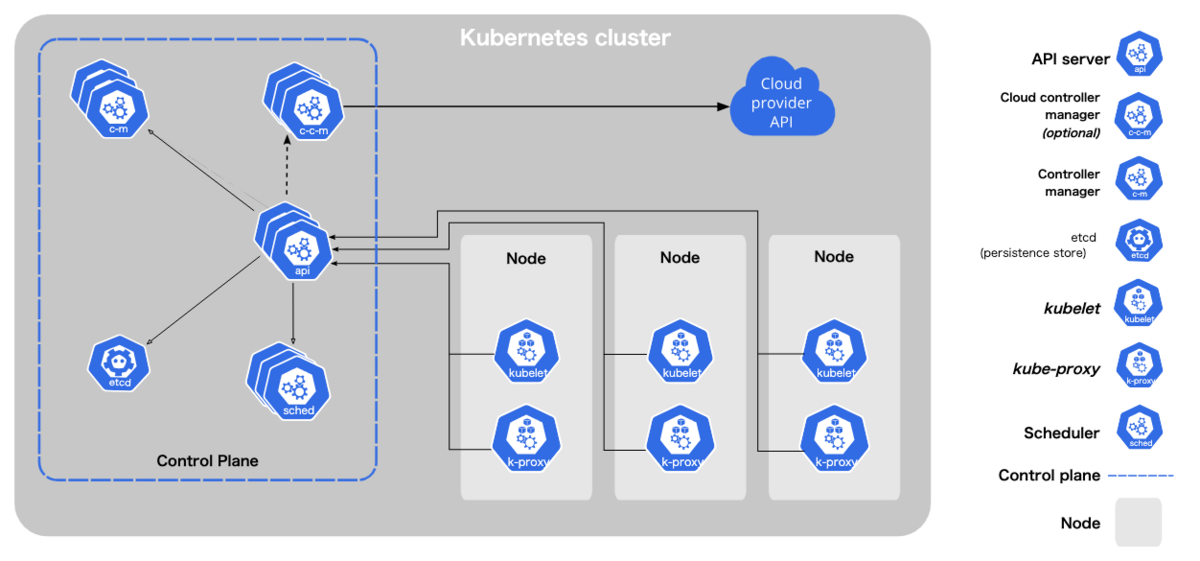
GKEではGCPがコントロールプレーンを管理しており、手動アップグレードする場合はバージョンを変更するだけです。
コントロールプレーンのアップグレード中はクラスタの可用性タイプにより一部の操作ができなくなるので注意が必要です。 ゾーンクラスタと呼ばれる可用性タイプの場合、アップグレード中はクラスタの構成やワークロードの変更などの更新操作は行えなくなります。逆にリージョンクラスタと呼ばれる可用性タイプの場合はコントロールプレーンのレプリカがリージョンの各ゾーンに存在するので上記のような制約はありません。
コントロールプレーンに関しては基本的にバージョンを上げるだけですが、ゾーンクラスタとリージョンクラスタの場合は、アップグレードの実行時間に差があるのでこの点も気に止めておいていいかなと思います。
私が作業した際はコントロールプレーンのアップグレードに1ゾーン=約15分ほどかかりました。ゾーンクラスタの場合は1ゾーンのみなので約15分ほどでアップグレードが完了しますが、リージョンクラスタの場合はリージョン内のゾーンの数だけ順にアップグレードが実行されるので、ゾーンの数x15分ほど時間がかかります。データエンジニアリングチームが管理しているクラスタは東京リージョン(asia-northeast1)にあるのですが、東京リージョン内には3ゾーン(asia-northeast1-a、asia-northeast1-b、asia-northeast1-c)含まれているので、リージョンクラスタのコントロールプレーンのアップグレードには約45分要しました。
ノードプール
次に各ノードプールのアップグレードについてです。
GKEのノードプールのアップグレード戦略には大きく2つの戦略を取ることができるのですが、今回のアップグレードではサージアップグレードと呼ばれる戦略をとりました。
詳しい説明は公式ドキュメントを参照頂ければと思いますが、これはGKEデフォルトのアップグレード戦略で、既存のノードを削除する前に新しいノードを起動することで利用可能なノード数を維持しながらアップグレードを行います。それにより、ワークロードの中断の可能性を低減させることができる方法となっています。
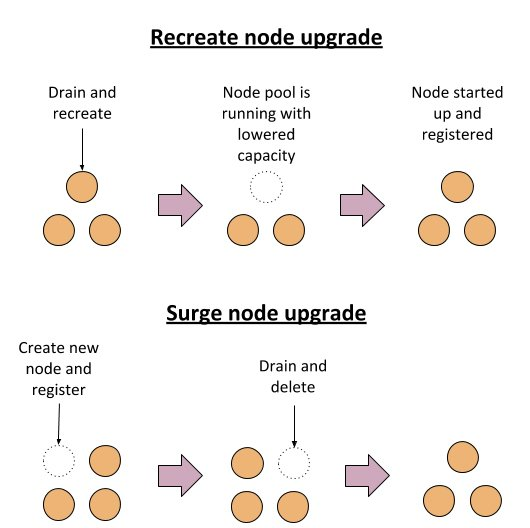
ノードプールに追加できるノード数(max-surge-upgrade)や、アップグレード中に同時に使用不可となるノード数(max-unavailable-upgrade)のパラメータを調整することで、サージアップグレードの挙動を調整することができます。
デフォルトではmax-surge-upgradeは1、max-unavailable-upgradeは0となっており、1ノードずつ新しいノードが追加され、新しいノードの準備が完了したら古いノードが1台削除されます。1台ずつノードをアップグレードしていくため、ノード数が多いとそれだけ時間を要します。max-surge-upgradeの値を増やせば同時にアップグレードできるノード数が増えるので、その分早く処理が完了します。
私が実際に手動アップグレードを行った際は、作業前に稼働中のノード数を確認してmax-surge-upgradeの値を変更することで、現実的な時間でアップグレードが終わるようにしていました(勿論これは開発環境で動作を確認した上でのことです)
max-surge-upgradeの値はワークロードの種類やアプリケーションの性能などにより変わってきます。
私が作業した際は、常駐するWebアプリケーションが稼働しているノードプールの場合は、全ノード数のおおよそ1/3ほどをmax-surge-upgradeの値に設定することが多かったです。 夜間バッチのためのノードプールもありましたが、ノードのオートスケールにより日中はノード数が0となっており、そもそも一瞬で終わっていました。
実際に作業する際はクラスタ上のノードプールの数に応じて作業時間が必要になるので注意が必要です。というのもノードプールのアップグレードは並列に実行できないので、ノードプールを1つ1つアップグレードしていく必要があります。ノードプールの数が多いとそれだけ時間がかかってしまいます。
後日談
GKEのバージョンをv1.21からv1.22にアップグレードしても、自動アップグレードの一時停止は解決しなかったので、v1.23へも手動でアップグレードしました。 というのもIssueにも言及がありますが、GKEではIngress Beta APIの移行に対する延命措置として、v1.22でもIngress Beta APIをサポートを決定しました(一定の条件を満たす必要あり)。 これによりv1.21と同様にDeprecation InsightsにIngress Beta APIの利用が検出されて自動アップグレードが一時停止してしまったためです。
まとめ
GKEを利用している場合、クラスタのアップグレードも自動で行っている場合がほとんどだと思いますが、手動でアップグレードが必要になる場合もあるという話を紹介しました。 手動アップグレードする機会はあまりないと思いますが、本記事が何かの役にたてば幸いです。
モノタロウではGCPやGKEを活用した基盤を支えるエンジニアを募集しています。この記事を読んでモノタロウに興味を持って頂けた方がいらっしゃればぜひカジュアルMTGにご応募ください。お待ちしてます!