はじめまして、MonotaROでデータエンジニアをやっています、芝本です。
エンジニアのみなさん、技術を使って何か作ってみるのって楽しいですよね。 私は、公私ともに日々物作りに励んでいます。プライベートだと、最近はマイクロフロントエンドについて学んでいます。 技術を使うためには、技術を学ばなければいけません。 プライベートにおいては、好奇心に従って自由に学びますよね。 とりあえずgit cloneして動かしてみたり、書籍を購入して読んでみたりします。 というようにプライベートでは主に次のような選択肢があると思います。
- 書籍を読んで好きなものを選ぶ
- 実際に手を動かしてみて好きなものを選ぶ
- 人に教えてもらって好きなものを選ぶ
基本的にプライベートの場合は何でも良いです。 しかし、業務の場合は、何でも良い訳ではなく、次のような選択肢があると思います。
- 技術を差別化して選ぶ
- 情報資産の観点から技術を選ぶ
- エンジニア採用しやすい技術を選ぶ
最近、ワークフローエンジンの技術選定を通して、“俯瞰的・相対的な技術選定”の考え方を学び、視野が広がりました。 “俯瞰的・相対的な技術選定”の考え方とは、技術選定で考慮すべき観点を、個々で考えるのではなく、全体を俯瞰しながら考え、それらを相対的に評価し技術を選ぶことです。 その考え方により、技術を選ぶ上での多角的に捉える視点を得られました。

その学びに至るまでの経緯についてこれから紹介しますので、ぜひ一度、読者の皆さんにも知って頂ければと思います。
※ ここでいう技術とは、ソフトウェア技術を指します。
背景
私はこれまで、実際に手を動かしてみるなどして技術を学び続けてきました。技術を学んでいくと、次は、学んだ技術をプロダクト開発に使えるかどうか、つまり技術選定を考え始めるようになりました。そうすると、これまで深く考えてこなかった”技術の差別化”や”情報資産からToBeを考える”についての観点を意識するようになりました。
○ 技術の差別化
例えば、ワークフローエンジンのDigdagとAirflowについての明確な違い(差別化)がどういったものか知らない場合、目的が実現できるのであれば、どちらの技術でも良いのではと思ってしまいます。そうすると、新しい技術を使って挑戦したくても、使い慣れた技術を使うというジレンマに陥ります。
○ 情報資産からToBeを考える
情報資産という言葉がある通り、組織には「ヒト・モノ・カネ」という情報があります。これを意識せずに技術選定してしまうと、組織全体の仕組みに合わなくなります。例えば、組織にDigdagを扱えるエンジニアが多い一方で、Airflowを扱えるエンジニアが少ない状況下で、Airflowを選択すると、Digdagを選択する場合と比べて、工数が増えることになります。
私は、“技術の差別化”についての理解が浅かったためそれを深堀りしたいと考えました。
また、”技術の差別化”だけで判断すると、”情報資産からToBeを考える”があるような課題に直面する可能性があります。個々の観点に焦点を当てるだけではなく、一歩引いた俯瞰的な視点で、個々を相対的に評価する力も養いたいなとも思いました。そこで、”情報資産からToBeを考える”への理解を深め、”技術の差別化”と比較し評価してみようと思います。
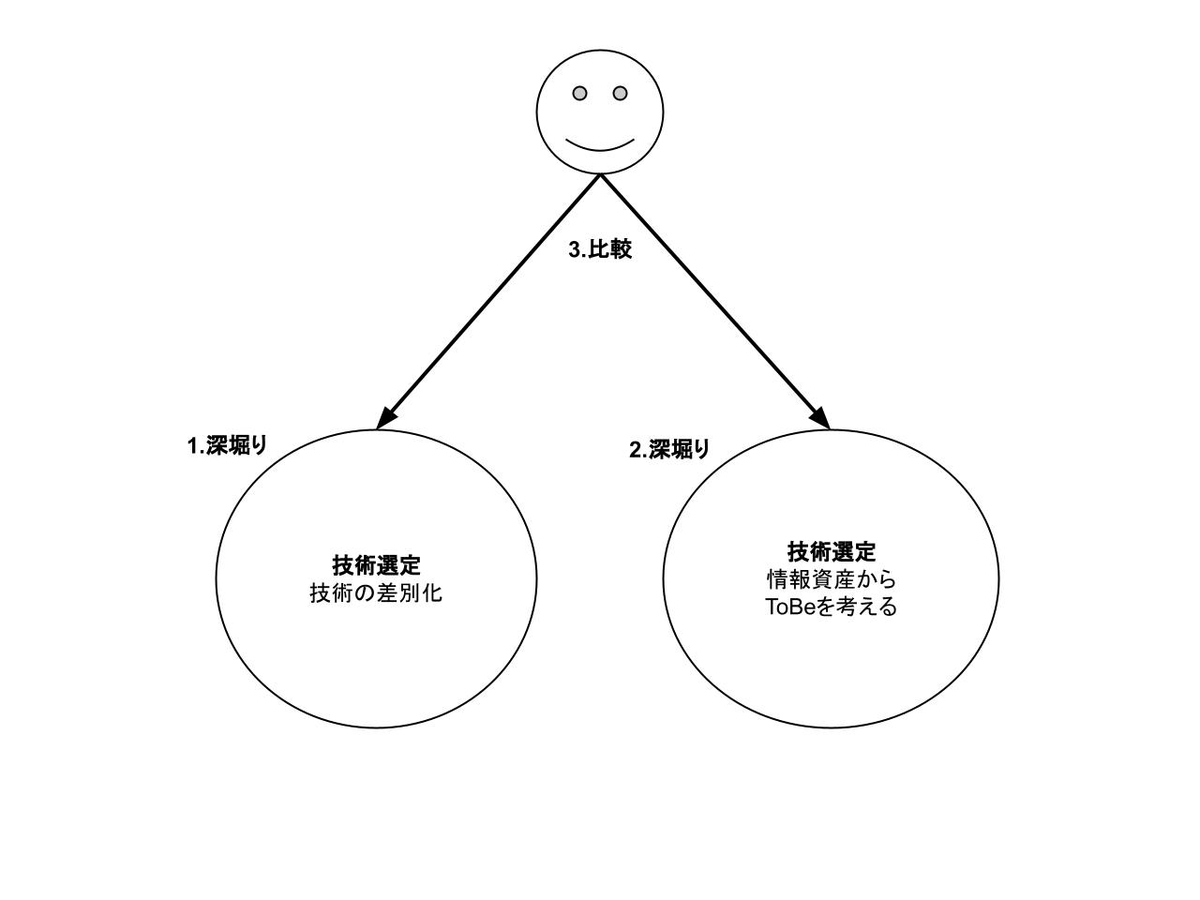
お題
技術選定を通じて学んだワークフローエンジンを題材とします。
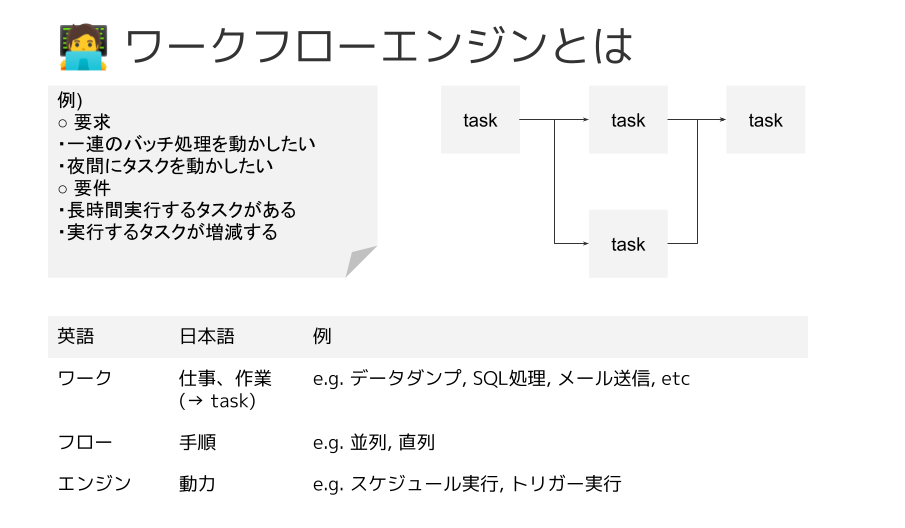
ワークフローエンジンとは"タスクを決まった順序で自律的に動かすもの"と考えます。
たとえば、"次のような手順を毎日0時に実行するよう自動化したい"という要求があるとします。
- MySQLのテーブルをダンプ
- 1を参照して、複数のSQLを並列で実行&保存
- 実行結果について、メール送信
このワークフローをスクラッチで開発する場合、次のようなスクリプト構成が考えられます。
・ workflow.sh (以下のshellscriptを順序通り実行する)
・ dump_table.sh
・ excute_and_store_by_sql.sh
・ item.sql
・ product.sql
・ send_mail.sh
上記スクリプトを次のようなcronに書きます。
0 0 * * * ./workflow.sh
スクラッチで書くと、次のようなことを考えなければいけません。
- 各タスクの実行タイミング調整
- Ex. 前方タスクの完了を待機
- 各タスクのエラーハンドリング等の制御
- Ex. あるタスクが失敗した場合の復旧&再開
- ワークフロー起動のステータス確認
- Ex. 毎日0時に起動できたかの確認
これらを自前でやろうとすると、なかなか骨が折れます。特にワークフローにおける各タスクの状態管理(待機中、進行中、成功、失敗)が難しく、辛酸をなめることになります。
技術の差別化
前述のようにスクラッチで書くと状態管理の難しさに直面します。これらを解決するためにワークフローエンジンが存在します。
技術の差別化を知るには、公式資料を見るのが一番です。ConceptやMotivation、Historyを見ると、原点を知ることができ、その結果、各技術の差別的な特徴が分かるようになります。さらに知りたい場合は、ArchitectureやUnder the hoodのような章を読むと理解が深まります。
それでは、いくつかのワークフローエンジンを確認していきます。
○ Luigi
Luigiというソフトウェアの特徴は、公式サイトによると次のことが書かれています。
The purpose of Luigi is to address all the plumbing typically associated with long-running batch processes.
※ Getting Started — Luigi 2.8.13 documentation
long-running batch processesとあるように、長時間実行するようなタスクを処理するのに向いています。
These tasks can be anything, but are typically long running things like Hadoop jobs, dumping data to/from databases, running machine learning algorithms, or anything else.
※ Getting Started — Luigi 2.8.13 documentation
長時間実行するタスクの例としては、データベースのダンプ処理があります。
○ Apache Airflow
Apache Airflow (以下,Airflowと呼ぶ)は、公式サイトによると次のことが書かれています。
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Airflowはワークフローエンジンをスケジューリングやモニタリングするためのプラットフォームです。 プラットフォームは、土台・基盤という意味なので、ワークフローエンジンを動かすための土台と解釈できます。 土台ということは、ワークフローエンジンに必要な準備が整っていることになります。 その一例として、GCP、AWS、Azureなどのサードパーティサービスとの連携機能が準備されています。 現に、Airflow 公式サイトを見ると、Integrationsのセクションがあります。
他にもArgo WorkflowやDigdag存在します。これらのワークフローエンジンについての特徴を次の図でまとめました。
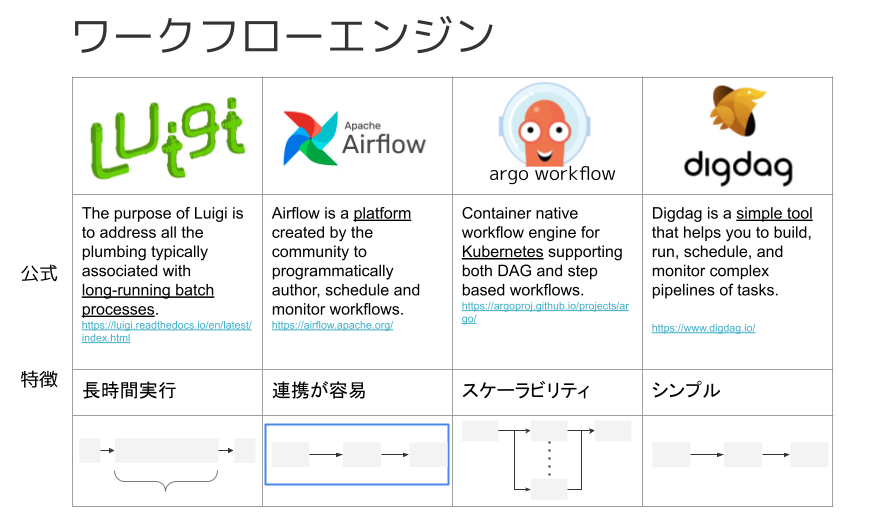
差別化から分かること
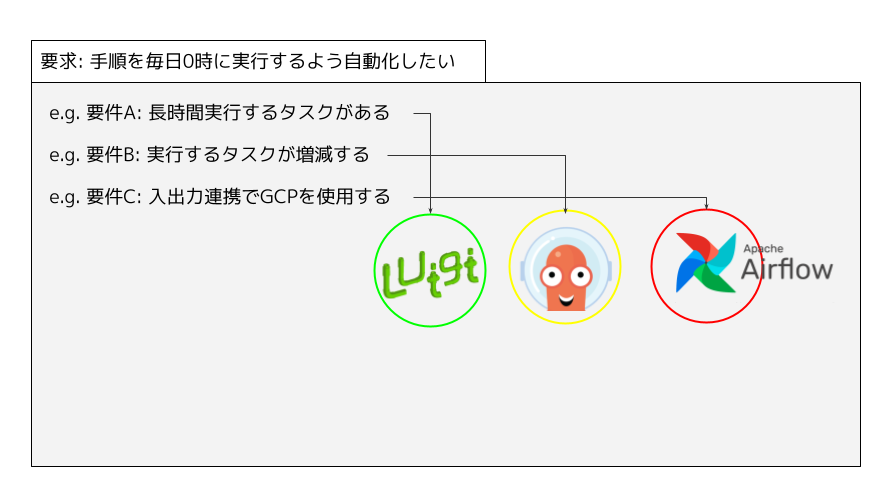
お題で挙げた例のような要求、”手順を毎日0時に実行するよう自動化したい”があったとします。その要求を満たすための要件は、色々あります。 たとえば、次のような要件があるとします。
- 長時間実行するタスクがある
- 実行するタスクは増減する
- 入出力連携にGCPを使用する
これらの要件を満たすだけであれば、どのワークフローエンジンでも実現可能だと思います。
たとえば、”入出力連携でGCPを使用する” という要件は、Digdagでも実現できます。 Digdagにあるビルドインの機能を使うか、なければ泥臭くshellscriptを書くことになります。
では、何でもかんでも1つの技術だけで良いのかと言われると、そうではありません。
包丁という道具には、果物ナイフや出刃包丁といったように切る対象に応じて道具を使い分けるように、ワークフローエンジンの各技術も対象に応じて使い分けるべきです。
先程の”入出力連携でGCPを使用する”であれば、シンプルさの特徴を持つDigdagではなく、外部との連携がしやすいプラットフォームのAirflowの方が適しています。
このように対象技術を差別化することによって、技術を使い分けることが大切です。
情報資産からToBeを考える
背景で述べた”技術の差別化”という観点については、前章で深堀げました。次は、”情報資産からToBeを考える”という観点で考えます。組織には、これまでプロジェクトや案件などから積み重ねてきた情報資産があります。その資産の内、私の場合、次の3つの項目について考慮します。
- 工数
- 依存関係
- パフォーマンス
工数は、組織として開発する上では欠かせない要素です。いつまでに完成するのか、それにはどれぐらいの費用がかかるのか、スケジュールを考える上では重要な要素です。工数には、モノを作るための学習コスト、モノを作る開発段階、作ったモノを保守・運用するメンテナンスコストなどがあります。これが考慮できていないと、組織全体の足並みが揃わなくなってしまいます。組織で働く以上、工数を考慮しなくてよい場面は、ほとんどないと思われます。
依存関係は、保守・運用段階で大きく影響する要素です。依存するサービスがダウンした場合はどうなるのか、変更があった場合に影響を受けるのか、保守・運用する立場の人にとっては気になる要素です。これが考慮できていないと、トラブルシュートに追われる日々が待っています。依存関係を考慮しなくてよい場面は、依存先のサービスに変更頻度がほぼないようなケースなら、特に気にしなくても良いと思います。
パフォーマンスは、非機能要件として挙げられる要素の1つです。弊社のようなプロダクト規模になると、パフォーマンスはほぼ間違いなく検討事項の1つとなります。処理すべき件数(アクセス数、データ量など)が大きかったり、今後増加が見込まれる場面においては考慮が必要です。考慮できていないと、プロダクトの成長に伴うサービスレベルの維持が困難になってしまいます。パフォーマンスを考慮しなくてよい場面は、先程の考慮すべき事項の逆を指します。
これらの項目からToBeを考えるためには、既存システムのAsIsを知ることが大切です。それを知ることで、工数はどのぐらい使えるのか、パフォーマンスは今後どれぐらい捌く必要があるのかといった課題が見えてきます。そこから、項目に優先度を考えて、技術選定を行います。
俯瞰的・相対的な技術選定
“技術の差別化”と”情報資産からToBeを考える”の2つを考慮する場合、どのように評価するのでしょうか。それは、そのプロジェクトにおける優先順位に従います。
そこで、その2つを考慮した事例について紹介します。
現在、弊社が提供している検索システムを新しい基盤で再構築するプロジェクトが進んでいます。その検索システムが参照するデータの生成部分(以下,データ生成と呼ぶ)にワークフローエンジンDigdagで構築することになりました。その経緯について説明します。
○ 技術の差別化
Dataflowというデータ処理パイプラインであるGCPのマネージドサービスがあります。Dataflowは自律的に起動できる仕組みがないため、ワークフローエンジンではありません。データを入力、加工、出力するETLというカテゴリに属します。詳しくは、公式ページをご確認下さい。Dataflowには、主に次の2つの特徴があります。
- データ転送のレイテンシを抑えたストリーミング処理
- GCPによるフルマネージドサービス
この2つの特徴を併せ持つワークフローエンジンはありません。 ストリーミング処理の機能を活用すれば、検索システムのデータをリアルタイムに更新できるかもしれません。商品の在庫数など日々変化するデータに対してリアルタイム更新が実現できれば、ユーザー体験の向上が期待できます。
そのため、Dataflowという選択肢が候補になりました。
○ 情報資産からToBeを考える
情報資産からToBeを考える”として、それぞれ見ていきます。
・ 工数
社内には、現検索システム向けのデータ生成にDigdagを採用している箇所がすでにあります。そのため、Digdagの実績もあり、Digdagを扱える社員も存在しますので、資産が豊富です。
既存システムの課題として、現検索システムの寿命があり、それの延命措置が繰り返し行われている点です。そのため、極力工数を削減したいという狙いがあります。
・ 依存関係
現行の設計では、データストレージのハブとしてワークフローエンジンが使われています。データストレージは、MySQLとBigQueryになります。 これは、元々MySQLだけに参照していたところ、BigQueryへ段階的に移行しようとしていた形跡になります。移行目的は、パフォーマンス改善になります。 新しく開発するシステムは、現行の設計を踏襲する必要はありません。MySQLとBigQueryという2つへ依存するのではなく、BigQueryだけに依存するような設計となりました。
・ パフォーマンス
“依存関係”というテーマの本来の狙いとしては、こちらのパフォーマンスにありました。 現行の設計では、MySQLで取得したデータをPythonで更に加工する処理をしています。 本プロジェクトの要件に、指定時間内にデータを生成する必要があるため、パフォーマンスは重要になります。 パフォーマンスとしては、MySQL + Pythonに比べて、BigQuery だけで処理するほうが断然早いことは明白です。そこで、MySQL + Pythonというパターンを捨て、全てBigQueryだけで完結するよう設計しました。
これらの理由より、Digdagを選ぶこととなりました。
○ 選定結果
これまでの話より、DataflowかDigdagかという2択に絞られました。 前者はビジネスインパクトが大きなモダナイゼーションのロードマップで、後者は現検索システムを移行するというマイグレーションのロードマップです。 前者は、とても魅力的な施策なのですが、開発・検証工数が読めないのが課題となりました。 後者は、工数見積が前者と比較して読みやすいため、スケジュールを立てやすいです。しかし、ユーザー体験は変わりません。
本プロジェクトとしては現検索システムの寿命までに移行するという優先事項があるため、後者のDigdagを選択するという判断になりました。ただし、前者の魅力的な施策をしないという訳ではなく、それも視野に入れた設計で開発を進めています。
これまでの話から学んだこと
大きく分けて3点あります。
- “技術の差別化”を知るために、対象技術の特徴を知ること
- “情報資産からToBeを考える”ために、既存システムのAsIsを知ること
- 俯瞰的・相対的な技術選定をするために、視野を広げること
1点目は、技術にはそれぞれ差別化を図るための特徴があり、それは公式資料を見れば分かります。何でもかんでも1つの技術で良いという訳ではなく、技術を使い分ける必要があります。
2点目は、組織が蓄積してきた情報資産も技術選定する上では大切な材料です。あるべき姿を捉えるためには、まず既存システムの現状を知ることが重要です。そこから、情報資産の優先すべき項目を見つけます。
3点目は、これまで技術選定には “技術の差別化”と”情報資産からToBeを考える”という2つの観点で選定しました。これは一例に過ぎず、観点は幅広く存在します。例えば、記事冒頭で述べたように “エンジニア採用” という観点も存在します。この観点があると、プロダクトを支えるエンジニアの数が潤い、安定した開発プロセスに貢献できます。このように、技術選定するには多角的に見れるような視野が必要になります。
最後に
技術選定における学びについてご紹介しましたが、いかがでしたでしょうか。 読者の皆さんに、何か一つでも気づきがあれば幸いです。 弊社では、本記事でも紹介したようなもの以外にも、新基盤刷新へのプロジェクトが複数存在します。もし興味がありましたら、ぜひご応募下さい。 最後まで読んでいただき、ありがとうございました。