こんにちは。コアシステムエンジニアリング部門 商品ドメイングループの流川です。当グループでは商品情報管理基盤の開発・運用を担当しています。
突然ですが、システム刷新後にトラブルが頻発し、頭を抱えたことはありませんか?
慣れ親しんだシステムをいつまでも使い続けたいですよね。社会背景や事業成長と共にシステム刷新を行わなければならない時は必ず来てしまいます。刷新に関わることも大変ですが、本当に大変だったのは運用後だったことを痛感しました。刷新を行うと運用方法も同時に変わってしまい、トラブルが起きがちです。今回は商品点数約2200万点を支えるモノタロウの商品情報管理基盤を刷新した際の経験をもとに、どう解決したのか、その手引きをご提供します。
商品情報管理基盤の刷新背景
従来、モノタロウの商品情報管理の仕組みは内製のシステムで運用されていました。この内製システムを繰り返しの改修作業をしてきた結果、システムが煩雑となり業務要件変更の際の影響調査・開発・導入までに時間を要する肥大で煩雑な仕組みとなってしまいました。
その結果、ビジネス変化のスピードに改修が追いつかないレガシーシステムになりました。
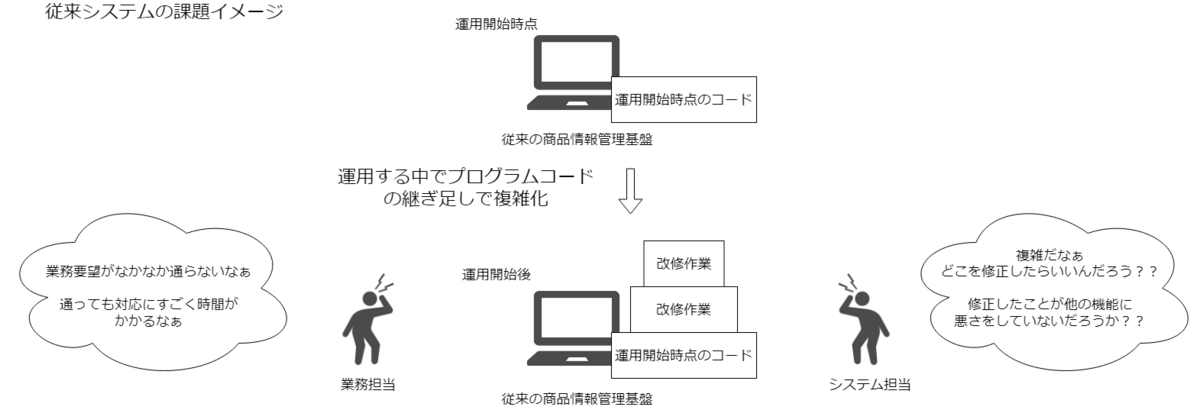
そこで、改修に強いシステムを新たに導入することで、ビジネス変化の対応にかかる時間を短縮することを狙いとして、カスタマイズ性の高いPIM(Product Information Management)パッケージシステムへの刷新を行いました。
(補足:このPIMパッケージシステム導入の判断は2019年に行いました。その後様々な経緯があり、会社全体としては、これ以降、他の基幹システムについては、業務ドメインに分割しつつ、内製システムでの刷新という方針に変更しています。)
刷新後のシステム概要図
システムは下記の概要イメージのような構成です。
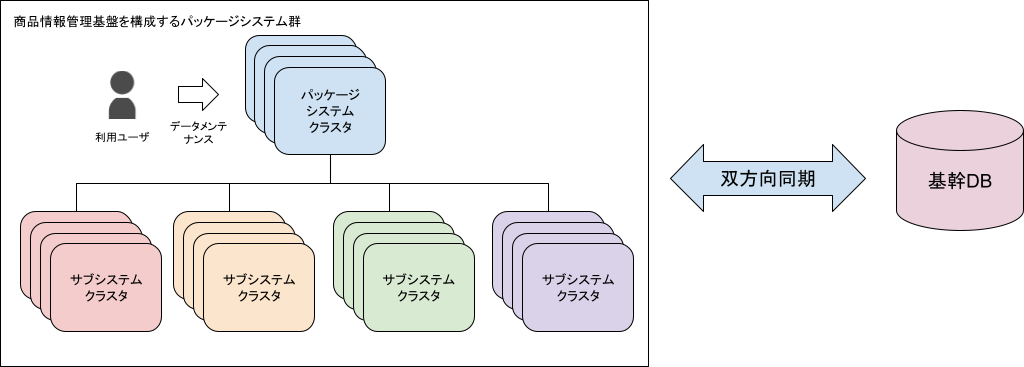
パッケージシステムはクラスタ構成で組んでいます。ユーザが直接触れるパッケージシステムの裏では複数のサブシステムが稼働しており、データメンテナンスを行うとサブシステム間の処理を経て、基幹DBへデータが同期されるような仕組みです。また、パッケージシステムで参照している一部マスタデータについては基幹側でも更新が行われており、その情報をパッケージシステムにフィードバックするため、パッケージシステム群と基幹DB間の双方向でのデータ送受信を行っています。
※データ送受信部分の同期処理パフォーマンス改善については以前に記事を公開しています。よろしければご覧ください。
導入後にトラブルが頻発!
導入後半年間で約20種類の障害原因でサービス停止が頻発しました。多い時では日に数回サービス停止を繰り返し、それに伴い商品情報登録業務も滞留することになります。
[発生した障害例]
- サブシステムへの大量の処理依頼が発生し、捌き切れずにサービス停止
- パッケージシステム内部のDBパフォーマンス劣化が発生し、時間内にコンシューマーからレスポンス依頼を返答できない
- パッケージシステムクラスタの設定競合によりSplit brainが発生
- 障害復旧やリリースオペレーションミスによりサービスが正常稼働しない
- 原因不明の障害
等々
当時の運用担当者の心境とその背景から得た改善ヒント

当時、繰り返しの障害発生によりネガティブな感情で障害復旧対応にあたっており、場当たり的な対応では状況改善が難しい状況でした。そこで、上記のように感じる背景を考えてみることにしました。その背景を紐解くことで解決の糸口につながるのではないかと思ったためです。その結果からいくつかのヒントを得ることができました。
- パッケージシステムに対する理解・ノウハウが不足している。運用を考慮した機能が不足している
- スキルセットが各担当者で大幅に異なる。障害復旧対応が属人化している。サブシステムを横断した問題が発生した際の意思決定が難しい
- 複数のサブシステムから構成されるパッケージシステム群とクラスタ構成によりシステム運用には複雑性がある
- 適切な判断を行うための指標が不足している
- 目先の対応に追われ、改善活動を行うための時間の確保ができない
これらのヒントを踏まえて、解決に向けてのアプローチ検討とその実行に進みます。
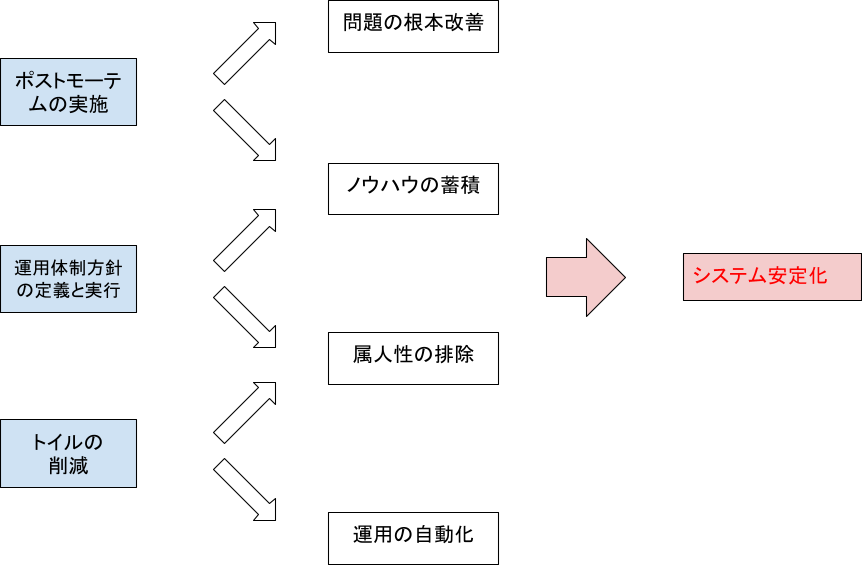
解決に向けてのアプローチ
ポストモーテムを実施
ポストモーテムとは、起きたトラブルから学ぶことを目的としたプロセスです。人を非難しない分析と議論により、トラブル発生原因の詳細な説明と、将来同様のトラブルを再び発生させないためのアクションを作成します。ポストモーテムは継続的な改善の文化を促します。人のミスを指摘するのではなく、改善アクションを出すことを目的としているため、参加者の心理的安全性を確保します。そうすることにより問題点が隠ぺいされない分析と議論が生まれ、解決に向けた効果的な改善アクションがアウトプットとして出てきます。
具体的には下記の項目を整理し、分析と議論をもとにアクションアイテムを決定していきます。
対応タイムライン
- 障害検知から対応完了までのタイムラインを整理します。この項目をもとに直接障害対応にあたっていなかった人へも状況が分かるように明文化します。
影響範囲
- 顧客や社内への影響を整理します。
根本原因
- 障害の原因として分かっていることを整理します。
トリガー
- 何をきっかけにして障害が発生しているのかを整理します。きっかけが不明な時には各サーバーの状態指標等、状況証拠を積み上げることで仮説を立てるためのインプット情報を収集します。
解消の経緯
- どのようにして障害が解消したのかを整理します。
検知方法
- 障害をどのようにして検知したのかを整理します。
トラブルの深掘り
- 上記までの項目を関係者で意識合わせした後に参加者全員で議論を行います。議論の観点は「うまくいったこと」・「うまくいかなかったこと」・「ラッキーだったこと」・「トラブルから学べたこと」です。※心理的安全性確保のため、否定的な言葉を使わないことがポイントです。
アクションアイテム
- 分析と議論を踏まえた改善アクションをSMARTなもので設定します。
- 具体的(Specific) – 具体的な改善項目を示す。
- 測定可能(Measurable) – 進捗測定について、定量化するか、最低限でも目安を与える。
- 割り当てられる(Assignable) – 誰が実施するかを定める。
- 現実的(Realistic) – 利用可能な資源の範囲で結果を達成することが現実的であることを示す。
- 期限のある(Time-related) – いつまでに結果を達成するかを定める。
- 分析と議論を踏まえた改善アクションをSMARTなもので設定します。
ナレッジの蓄積と障害の根本対応を狙いとして、障害発生後はポストモーテムを実施するようにしました。
運用体制方針の定義とスキルマップの整理
サービスインまでの間は各サブシステム毎にそれぞれを得意としている担当者が開発を担い、実質サブシステムごとに担当がついている状況であり、「深く狭い範囲を守備範囲とする特化型の体制」となっていました。しかし、運用開始後に起こる障害対応はサブシステムを横断しての判断が必要になります。そこで、運用体制方針として「パッケージサブシステムを横断しての意思決定と改修対応を運用担当者全員ができるようになる。浅く広い守備範囲を目指す。深く狭い範囲を担当するアサインは行わない。」と定め、それを実現するためのギャップを埋めていくアプローチをとっていきました。
ギャップを埋めていくための必要な情報を把握するために取ったアクションの一つがスキルマップの整理です。「そもそも開発・運用に必要なスキルって何だっけ?」という点に立ち戻り、これまでのノウハウを一つずつ棚卸しすることにしました。棚卸しのハードルを下げるため、完璧な整理を目指さず、徐々に拡充していく前提を置き、環境構築〜リリースの各プロセスに着目し、各システムで実施していることを観点として書き出していきました。
スキルマップの枠組みができた後に実施したことは、各担当者がどのスキルを習得しているか、状況の見える化です。スキルについてはレベル分けをして紐づけていきます。
次は各スキルを習得するための題材の整備です。安定していないシステムの運用をしながらの整理作業となるため、時間は潤沢に取れません。まずは在りものの資料を紐づけていくことから始め、資料がない観点については過去の対応チケットを紐づけていきました。
[出来上がったスキルマップのイメージ]

ここまでの整理を踏まえて、運用体制方針で掲げている「浅く広い守備範囲を目指す」という点を実現するにあたっての現状のギャップと必要な対応が見えてくるようになりました。各担当者毎のそれぞれが未修得スキルを埋めていくことができれば運用体制方針を実現ができそうです。
スキル習得に向けては毎月各担当者ごとの習得計画を立て、翌月に実績振り返りをすることにしました。
稼働工数の約20%を目途にその月の習得タスクを割り当てます。割り当てられた担当者はケーススタディ題材を写経する形で作業を実施します。その後、作業した結果の気づきをもとにケーススタディ題材の更新をしていきます。
これを繰り返すことにより運用体制方針の実現を目指していきました。
トイルの削減
トイルとは、自動化が可能な繰り返し行われる手作業のことです。
※詳細はSite Reliability Engineeringの「Eliminating Toil」で説明がされています。
自動化していくことにより、これまで手作業にかかっていた分の時間を短縮し、その他の改善に取り組む余力を捻出します。また、自動化することで作業の複雑性を隠ぺいし、ニッチなノウハウについても属人性を排除することや、オペレーションミスを排除することができます。このような効果を得ることを狙いとして、トイルの削減に乗り出しました。
まずは、トイルの特定です。運用作業の中で繰り返し行われる手作業をリストアップしていきました。
緊急度と自動化による改善効果をもとに対応優先度を割り当て、優先度が高いトイルから自動化に着手していきます。
[トイルとその概要例]
- 障害復旧作業
- 障害復旧作業が手作業で行われている。属人化により特定の作業者に負荷が偏っている。
- リリース作業
- リリース作業が手作業で行われている。クラスタ構成の各ホストに対して順次作業をするため、作業者は半日ペースで掛かりきりになる。また、オペレーションミスによる障害も発生している。
トイルを特定した後は自動化です。
JenkinsとPythonライブラリのFabricを用いて、下記の構成によって自動化を実現していきます。
Jenkinsとは継続的インテグレーション支援ツールであり、ビルドやテストといった一連の作業の自動化や効率化を支援します。Fabric は、定義した任意の処理をSSH経由でリモート実行することができます。この二つを組み合わせることで、各システムホストに対して手動で実施していた作業を自動化して再現をすることができます。
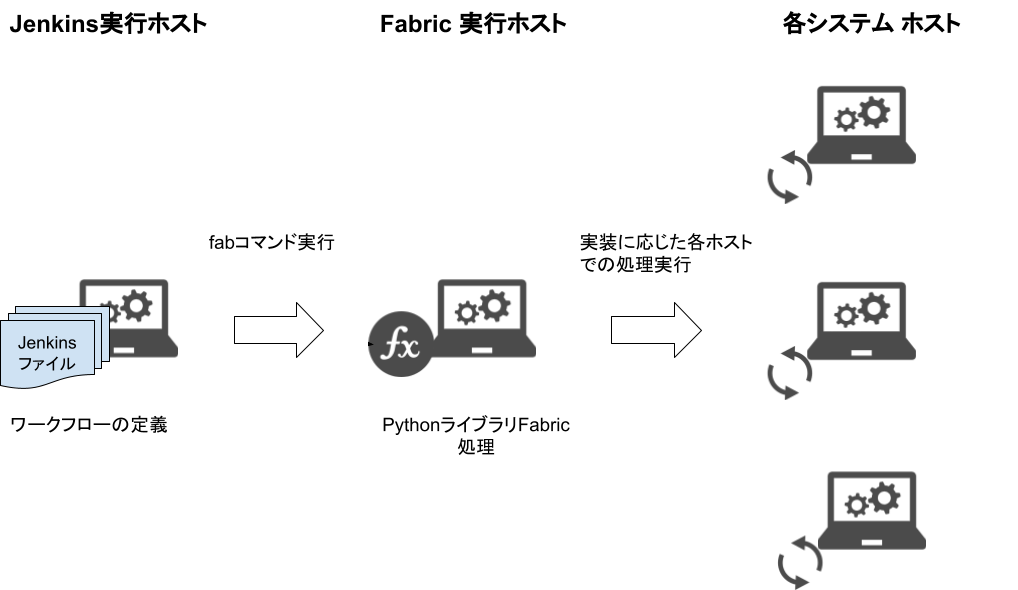
※Jenkinsについては以前に記事を公開しています。よろしければご覧ください。
作成した処理を他のトイルの削減でも再利用可能にするため、自動化基盤は極力同一のアーキテクチャを使うようにしました。自動化対象手順の各ステップをFabric処理としてコーディングし、複数のトイルで共通した手順に関しては、作成した処理を流用することで徐々に自動化範囲の拡充を実現します。
トイルの削減により、システム改善を行う余力を確保していくことを目指していきました。
取り組みの結果と振り返り
導入から1年経過した時点の改善効果です。※「導入直後〜半年」と「半年〜1年」の各指標の集計結果を比較することで効果測定をしています。
[改善効果例]

上記は代表的な改善項目です。
解決に向けたアプローチから大幅な効果を確認することができ、その結果システム安定化につなげることができました。
振り返ると、速効性のある施策とそうでない施策がありました。
トイルの削減はすぐに大きな効果を得ることができました。トイルの削減には有識者のみで構成した少人数の改善チームを作り、学習コストやマネジメントコストが極力かからない形で作業を進め、自動化の結果、目先の余力を捻出することに集中していました。
一方、スキルマップの定義やスキル習得は中長期的には有効でしたが、短期的には効果が出にくく、また時間をかけて準備を行わなければならない施策でした。その結果、作業負荷が一部の要員に集中し、短期的には追い詰められる状況となりました。しかし、トイルの削減が順調に進んだお陰で、その増えた作業負荷を軽減することができ、新たに得た余力を活かしてノウハウの標準化に取り組むことができました。トイルの削減がうまくハマって効果がすぐに出たことはラッキーだったと感じています。それでも、ケーススタディ題材の維持管理は思った以上の苦労を伴いました。ポストモーテム実施の結果や改善が進む中でノウハウが蓄積しはじめ、当初準備していたコンテンツだと十分ではなく陳腐化し始めていました。そのため、スキル学習者自身が学習後の気づきをもとにコンテンツを修正していく運用とし、常に生きた題材にする工夫を行い、意思決定をできる人員の拡大につなげることができました。
システム安定化には、「運用しやすいシステムアーキテクチャ」と「システムを支える体制」の両軸が必要だと痛感しています。また、今回は安定しないシステムを運用保守をしながら取り組みを並行して実施していきましたが、システムの運用開始後は「想定していないことが発生すること」を想定しておき、その対応に余裕を持てるよう開発工程から運用作業の自動化や要員のスキル標準化には取り組むことが必要だと思いました。また、今回紹介したどのアプローチでも思惑通りうまくいかない点は多々ありましたが、短いスパンでの振り返りと軌道修正を行うことで狙っていた目的を達成できたと考えています。
この記事では、商品情報管理基盤刷新の際の運用安定化に向けた取り組みを紹介しました。
運用安定化にはいくつものハードルがありましたが、メンバー同士が協力しあう雰囲気のもと改善活動を積み上げていくことができました。今回の取り組みで得た知見はシステムによらない考え方で、横展開が可能なものであり、確実な糧となりました。
現在は、更なる運用安定化を実現することができています。それを踏まえて、業務改善に向けた新たな構想を練っており、今後はその実現に向けたチャレンジを計画しています。
モノタロウでは随時エンジニアの採用募集をしております。この記事に興味を持っていただけた方や、モノタロウのエンジニアと話してみたい!という方はカジュアル面談 登録フォームからご応募お待ちしております。