こんにちは、MonotaROの伊藤です。
今回は私が所属しているチームでMonotaROのサイトのデプロイの大部分で使用されているJenkinsの運用を引き継いだ話をしたいと思います。 チームが結成されて最初の仕事として始めたこの引き継ぎでしたが、当初予定されていた二週間どころか完全な完了に四カ月かかってしまいました。 なぜ、このような事が起きてしまったのか振り返り、上手くいった事や上手くいかなかった事、どうすればもっとスムーズに進められたのか事などの内容について紹介できればと思います。
背景
MonotaROではCI/CDプラットフォームとしてJenkinsを2016年から使用しています。(Jenkins Day Japan 2021に登壇させていただきました - MonotaRO Tech Blog) 導入が開始された2016年から2023年の今にいたるまでの七年間、このJenkinsプラットフォームは拡大を続けてきました。Jenkinsの状況として現在は下記のような状態となっています。
- 3つのネットワーク(dev,stg,prod)
- 5つの部門、20以上のチーム
- サイト開発
- 基幹システム
- データ分析
- 海外向けサイト開発など
- 200人以上の利用者
- 500件以上のジョブ
開発作業のCIとしてや本番リリース作業、バッチサーバーとしてまで常時使用され続けており、そのサービスレベルを維持し続ける必要があります。 このJenkins環境の運用業務について担当者の異動があり、新規に編成されたチーム(総員二名)にて引き継ぐ事になりました。
そして引き継ぎ作業の完了条件として設定されたのがJenkins本体の最新版へのアップデートです。 前任の担当者の方が非常に多忙であり、一年半近くアップデート作業が実施されていない状態のためバージョンが古く、開発チームが入れたいと考えている必要なプラグインの導入が出来ないなどの開発者全体の生産性に影響を与えていました。アップデート作業を通じてJenkinsシステムに詳しくなる事ができ、利用者全員が利益を受けられる良い完了条件だと思い、当時の私を含めたチームメンバーや前任者の方は気軽な気持ちで作業を開始したのが始まりでした。 そして、当時の関係者は誰も分かっていませんでした。前任者の方の引継ぎ期限である一か月後どころか、四半期近くもかかる作業の始まりであった事を
終わらないアップデート
前章の最後で言った通り、アップデート作業は最初から失敗しました。その後も問題が発生し続け、アップデート予定日を3回程ずらし開発環境のアップデートを終えるだけで一ヶ月半もの時間を消費してしまったのです。失敗要因は多岐に渡ったのですが、代表的な問題についてご紹介いたします。
問題一: 本体のバージョンとプラグインの整合性が合わない
Jenkinsはその機能のほとんどをプラグイン形式で追加していく仕様となっています。
この設計の良い所はJenkins本体のアップデートに依存せずに、機能拡充を行う事ができる事です。 ですが、私たちのアップデート作業ではこの仕様によって以下のような無限ループに陥りました。
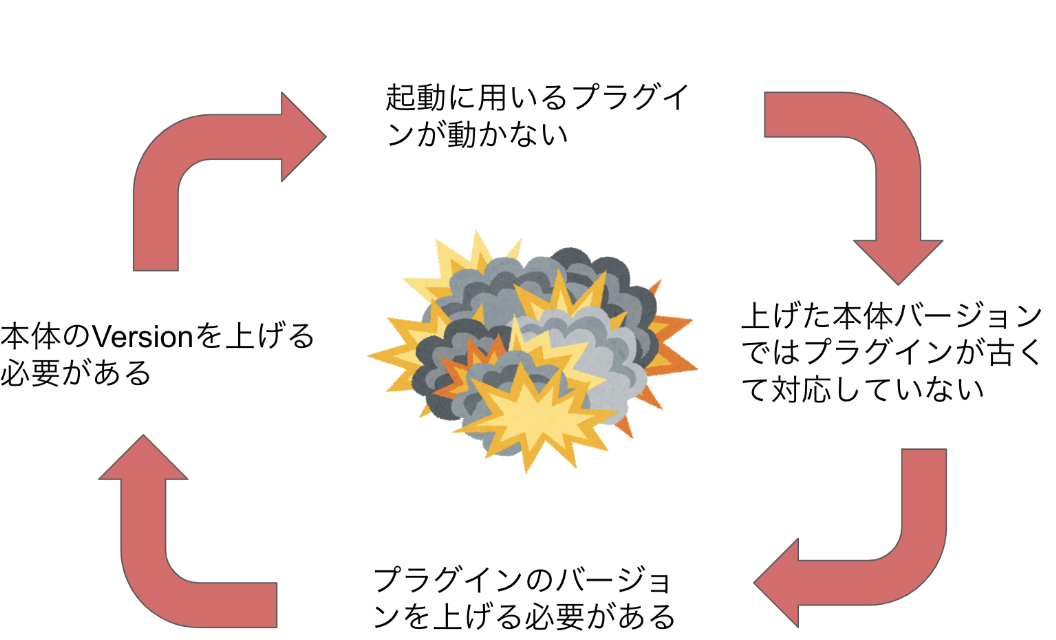
このような状態から脱却する為には、本体とプラグインを同時にアップデートする必要があるのです。しかし、既存の運用手法では同時にアップデートされる手順などは存在せず、Jenkins公式が用意しているアップデート手順でも不可能であった為、一から手探りで整合性の取れた状態でアップデート出来る手法を模索するという作業から始める事になりました。
問題二: ジョブが動かない!
上記の問題をトライアンドエラーで解決し、なんとかアップデートを実施したら起きたのがこの問題です。 前章で記載しましたが、弊社のJenkins環境は複数の部門に渡り様々な使われ方をしています。その中には、機能的には非推奨になっているものを使い続けているものがありました。 アップデートにより非推奨の機能が完全に削除された結果、ジョブ自体が通らなくなってしまったという問題が起きたのです。
これ以外の問題としてJenkins本体が稼働しているコンテナにバンドルされているパッケージの機能更新によりジョブの実施が出来なくなったりなど問題が発覚する度に元の状態に戻し、対応をしてやり直すという対処をし続ければなりませんでした。
問題三: サービスを停止して対処が出来ない
このようなメンテナンス作業は一定期間のサービス停止期間を設けて、アップデート作業を進めたいのですがJenkinsの活用状況からそのような時間を捻出するのも難しい状況だったのです。
一番検証がしやすい開発環境のJenkinsであったとしても、日々の開発フロー自体に組み込まれており半日以上の停止は許容されないです。そのような環境で上記の問題を全て解決し、本体設定やジョブ情報、認証情報の全てを維持したままアップデート完遂させる必要がありました。
このような制約で困った例としては以下のスクリーンショットのように、アップデートによりCIの履歴が参照できなくなり全てのブランチで再度CIが動き出してしまった為、ジョブキューが溜まり続け終わらなくなったという事態がありました。(1500件のジョブが溜まっている) このケースでは一日待てば、全てのジョブが実行され捌けるのでそれを待つという選択肢もありましたが、開発環境のJenkinsであっても、一日以上の停止は許容ができず緊急で対処しました。

それこそ本番環境のJenkinsは毎時実行されるバッチなどの兼ね合いもあり、一時間以上の停止は関係部署への連携が必要となる為、失敗した場合に一時間以内に全て元の状態に復旧させる手法をアップデート時に検討する必要がありました。
教訓
アップデートは定期的に実施しよう
基本的な事ですが、アップデートは定期的にきちんと実施し続ける体制の構築が重要だという事を再認識しました。
気軽にトライ&エラーが試せる個人のパソコンと違って、システムを使用しているユーザー数が多い業務用ソフトウェアではアップデートの影響が大きく、動いている状態が正である為、そのままにしてしまいがちです。ですが、アップデートが滞れば滞る程、変更内容が増えていき受け入れ側の負荷が上昇していきます。
幸いな事に弊社では問題となりませんでしたが、数年前の大きな騒動となったLog4j問題などの危険な脆弱性によりアップデートを即時実施を行わなければならない状態などに陥る可能性は十分にありえます。このような状態を回避する為にも定期的なアップデートを実施した方が良いです。
問題の解像度を上げる
これら問題に取り組む際に意識してやってよかったと思う事が問題の解像度を上げるという事です。 最初、私たちはこの状態についての理解が「なんかアップデートが上手くいかないぞ🤔」というレベルでした。 その後、しばらくの間はとりあえず思いついた目に見えている問題を解決するというサイクルを回し続けていましたが、結局次々と問題が発覚し我々が実施したかったアップデート自体はなかなか進まないという状態が続いてしまいました。この状態について解決出来たのはいったん落ち着いて我々が何を実現させたいのか、そしてその実現の障害は何であるのかを分割し続けた事です。これらの取り組みは非常に基本的な事かと思われますが、焦っている時などは意識的にはあまり実施できないものです。ですが、焦っている時こそきちんと分割し問題の解像度を上げ、やるべき事を明確化する事で悩む時間やトライ&エラーの精度が上がりより早く問題の解決に繋がりました。
最後に
アップデート作業自体は多くのハードルを乗り換えていかなければならない大変な物でしたがシステムの運用チームとして多くの知見を得る事が出来た良い仕事でした。チームメンバーは全員が運用の経験が浅く、良い運用とはどういうものかについて曖昧なイメージしか持ち合わせていませんでしたが、この経験を通して良い運用状態とはどのようなものかについてかなり具体的なイメージを持つ事が出来ました。 具体的には我々の後任者の方が我々と同じようなケースに陥ったとしても、当初の予定通りの二週間でアップデート作業も完遂が出来、運用も引き継ぐ状態を作り上げるという事です。それはRunbookが整備され続けている状態であり、アップデートや保守作業などの運用作業における明確なポリシーが定められ明文化された状態であり、システムのインフラがIaC化されコードによって管理されている状態であるといった、よりあるべき理想の運用像を共有する事が出来ました。 現在はその理想の運用像を元に新規に導入されたGitHubの活用や完全自動化されたリリースのシステムの開発・運用、QAのさらなる導入などを行っております。本取り組みについて興味がある方はぜひカジュアルMTGにお申し込み下さい。