こんにちは、EC基盤グループ 商品情報基盤チームの江村です。今回は私が所属している商品情報基盤チームで構築、運用を行っているシステムについてお話します。
モノタロウでは以前から記事になっていますが、検索システムの移行を行っており、現在商品検索ページの裏側の検索システムのSolrからElasticsearchへの切り替え*1が完了しました。
私が所属している商品情報基盤チームではElasticsearch、Spannerに入れるための商品情報の作成とSpannerおよび、Spannerからデータを取得するAPIの運用を行っています。今回はその中でもElasticsearch、SpannerのためのBigQueryでの商品情報作成処理について取り上げます。(詳しい検索部分の構成については以前の記事を参照ください)
システム移行の背景
システムの設計にも関わってくるためまずは簡単に移行の背景をお話します。
モノタロウでは現在1900万点に及ぶ商品を取り揃えており、会社の売上としても20%以上の成長が続いています。そのためシステムで扱うデータ量が今後も増えていくことが予想されており、数年前から検索システムの移行に取り組んでいます。商品情報を作成する部分についても同様で今後のモノタロウの成長を見据えて移行を行っています。
ではここからシステムの紹介、設計について紹介をしていきたいと思います。
移行による設計ポイント
「MySQL + Python」の処理を「BigQuery + SQL」に変更
最初の設計ポイントを説明するために、まずは移行元、移行先(私達のチームで管理)のシステムの構成を紹介します。
説明のため図、処理の流れは簡略化していますが、おおまかに以下のようになっています。

- BigQuery上でSQLを実行し中間テーブルを作成
- BigQuery上の中間テーブルをEC2上のMySQLにINSERT
- EC2上のMySQLのデータを元にPythonで商品情報を作成
ここから私達のチームで管理している移行先のシステムでは商品件数の増加にそなえて下記のような構成に変更を行いました。
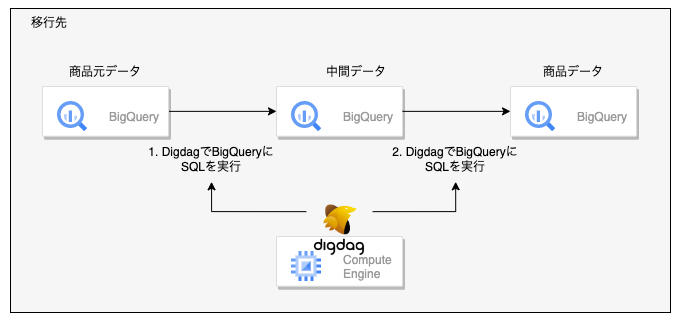
- BigQuery上でSQLを実行し中間テーブルを作成
- BigQuery上の中間テーブルからさらに、BigQueryに商品データを作成
移行元では「BigQuery + SQL」、「MySQL + Python」を使用していたのに対し、移行時に「MySQL + Python」の処理もすべて「BigQuery + SQL」で処理を行うようにしました。
「MySQL + Python」から「BigQuery + SQL」に移行した背景は大きくは2点あります。1点目は元々一部の処理(移行元1)はBigQueryで処理していたので、使用するツールを統一するという目的がありました。そして、2点目としては背景でもデータ量の増加を見据えていると記載しましたが、BigQueryのスケーラビリティ、マネージドといった特徴を活かして今後の商品件数の増加に対応をするためです。
商品情報のフィールドごとにSQLファイルを分けた
続いては具体的な処理の分け方の話になります。設計の方針として、依存関係を減らすために商品情報のフィールドごとにSQLファイルを分けました。前提として商品情報のフィールドとは「商品名」、「属性」、「価格」のようなものです。
移行元のシステムではPython処理を行っている部分が1ファイル3000行ほどになっており、1つの関数で160行ほどのものがある、条件分岐も多い...などフィールドごとの依存関係がわかりづらくなっている状態でした。
そのためSQLファイルを下記のようなイメージにしています。
price.sql
SELECT item_id, price FROM item_price WHERE price_type = 1
item_attribute.sql
SELECT item_id, ARRAY_AGG(attribute) AS item_attributes FROM item_attribute GRPUP BY item_id
item.sql
SELECT item_id, price, item_attributes FROM item_base LEFT JOIN price ON item_base.item_id = price.item_id LEFT JOIN item_attribute ON item_base.item_id = item_attribute.item_id
これにより、フィールドの修正時にも影響範囲を限定して修正を行うことができるようになりました。
バッチ処理として冪等性を保つようにした
バッチ処理では当たり前ですが、移行元の設計を引き継ぎ冪等性を保つように設定を入れました。日付ごとに商品情報を作っており、同じ日付であればすでに作成されているテーブルを上書きするようにしています。実現方法としてはDigdagのファイルの_export設定にbqの書き込み時の設定でWRITE_TRUNCATEを設定しています。
workflow.dig
timezone: Asia/Tokyo
_export:
!include : 'variables.yaml'
bq:
write_disposition: WRITE_TRUNCATE
+main:
+price:
+execute:
bq>: sql/price.sql
destination_table: price
これにより、バッチ処理が途中で失敗したときも状態を気にせず、インプットとなる日付情報だけを気にすればよく運用時に考えることが減るというメリットがあります。
移行元のシステムと日々データの比較を行い開発した
データ作成処理の設計ではないですが、システムの移行を安全に行う上での仕組みを紹介します。「MySQL + Python」の処理を「BigQuery + SQL」に置き換えたため作成された商品情報が移行の際に差異がないことを確認する必要があります。今回はデータの作成処理とは別にデータの比較処理を別のバッチとして構築を行いました。移行元のテーブルは社内の別の仕組みでBigQueryに結果を出力しており、移行先のテーブルとBigQueryを使って比較をしています。(モノタロウでは様々なデータをBigQueryに出力しています)
データの比較処理はフィールドごとに行い、いくつの商品で差がでているかやフィールドの差異をBigQueryのテーブルに書き込んでいます。

実際のSQLがだいぶ長いため簡略化していますが以下のイメージです。
- 移行元、移行先のテーブルをSELECT
- フィールドの結果をJSONにして、ハッシュ化
- それぞれのテーブルのIDをキーとしてハッシュの内容を比較
data_check.sql
WITH
# 1. 移行元、移行先のテーブルをSELECT
before_data AS (
SELECT
item_id AS key,
price
FROM
before_item ), # 移行元のテーブル
after_data AS (
SELECT
item_id AS key,
price
FROM
after_item ), # 移行先のテーブル
# 2. フィールドの結果をJSONにして、ハッシュ化
before AS (
SELECT
key,
SHA1(TO_JSON_STRING(STRUCT(d))) AS hash_string, # JSONにしてハッシュ化
FROM
before_data AS d ),
after AS (
SELECT
key,
SHA1(TO_JSON_STRING(STRUCT(d))) AS hash_string, # JSONにしてハッシュ化
FROM
after_data AS d ),
# 3. それぞれのテーブルのIDをキーとしてハッシュの内容を比較
diff AS (
SELECT
key,
CASE
WHEN before.key IS NULL THEN 'Add' # 移行元になければAdd
WHEN after.key IS NULL THEN 'Delete' # 移行先になければDelete
WHEN before.key = after.key AND before.hash_string = after.hash_string THEN 'Equal' # ハッシュが同じならEqual
ELSE
'Change' # 該当しない→ハッシュが異なるのでChange
END
AS result,
FROM … # before, afterのテーブルをkeyを元にして結合
そして、差異が出た場合には、Slackにアラート通知が来るようにしています。この仕組みにより日々の開発の中で継続的に検証を行うことができ安全に移行をしています。

移行で苦労した点
今回の移行では当初から設計面で大きな変更はありませんでしたが、設計以外の部分でいくつか苦労した点がありました。
データの比較処理での移行元との差異
具体的には配列内の順序が異なる、値が重複しているなどです。これは移行元のPythonをSQLに置き換えていく中で、コードの理解が浅く処理が抜けている場合や、そもそも移行元の処理の不備がある場合、今回の構成では表されていない商品情報の入力時点での予期しないデータの混入など様々な要因がありました。
また日々のデータ比較なので、季節性の商品など実装後にすぐにデータの差異に気づけないこともありました。
後続システムのと強い依存関係
以前出された記事にもありましたが作成した商品情報を利用する後続のElasticsearch、Spannerへのデータ投入処理と密結合になっており変更が行いづらくなっているといった点があります。
こういった苦労した点の中で細かいデータの差異については各グループ、チームと連携を行うことで1つ1つ地道にデータの差異を解消していくことで初回のリリースを迎えることができましたが、仕組みとしてデータの品質の保証、後続システムとの依存関係の削減についてはまだ解決はできておらず今後の改善ポイントとして残っています。
今後の取り組み
最初のリリースは無事に達成できましたが、まだ並行稼動状態であり、プロジェクトの目標としてはシステムの完全な移行を目指しています。そのためにもデータの移行元との前後比較ではなく、自分たちのシステムだけでデータの品質を保証しなければなりません。具体的にはBigQueryでの季節性など特定のロジックのテストの検証を予定しています。その他にも後続の処理との依存関係を減らす構成変更などチームでは多くの改善に取り組み始めています。
最後に、本記事で紹介したBigQueryを用いたデータパイプライン構築、改善に興味がある方はぜひカジュアル面談でお話できたらと思います!
*1:その他のページについてはまだSolrベースのため現在は並行稼動中です