モノタロウでデータサイエンティストをしております、朝倉と申します。今回は、モノタロウのサプライチェーンを支えるシステムの1つである需要予測に、機械学習を現場導入した際のお話をしようと思います。
- はじめに
- モノタロウでの発注の仕組みと需要予測
- 機械学習を導入する取り組みの開始
- 機械学習の現場導入で起きた問題点① - 発注量が増える
- 問題点① - 発注量が増えることへの解決策
- 機械学習の現場導入で起きた問題点② - 結果の解釈が難しい
- 問題点② - 結果の解釈が難しいことへの解決策
- まとめ
- これからの展望
はじめに
モノタロウでは1800万点以上の商品を取り揃えており、50万点近くの商品が在庫化されています。また、11年連続で売上が20%以上成長しており、売上増に伴い物流量も年々増加しております。規模の大きさや複雑さが増していくサプライチェーンの中で、コスト最適な状態を維持しながら顧客が必要とする商品をお届けするには、膨大なデータを正しく活用し意思決定していくことが必要不可欠です。
その一環としてモノタロウでは、サプライチェーンを支える様々なシステムや施策において、機械学習を導入しております。今回の記事は、その1つである需要予測に機械学習を導入した際のお話になります。
需要予測に限らず機械学習システムをビジネス現場で最大限に活かすためには、精度の高さだけでなく、現場の実情にフィットしたシステムであるかという視点が重要になってきます。そこでこの記事ではモデリングの手法や精度向上のためのテクニックというよりむしろ、機械学習をビジネス現場に実装する上で浮かび上がった課題とその解決方法についてフォーカスして紹介していきたいと思います。
モノタロウでの発注の仕組みと需要予測
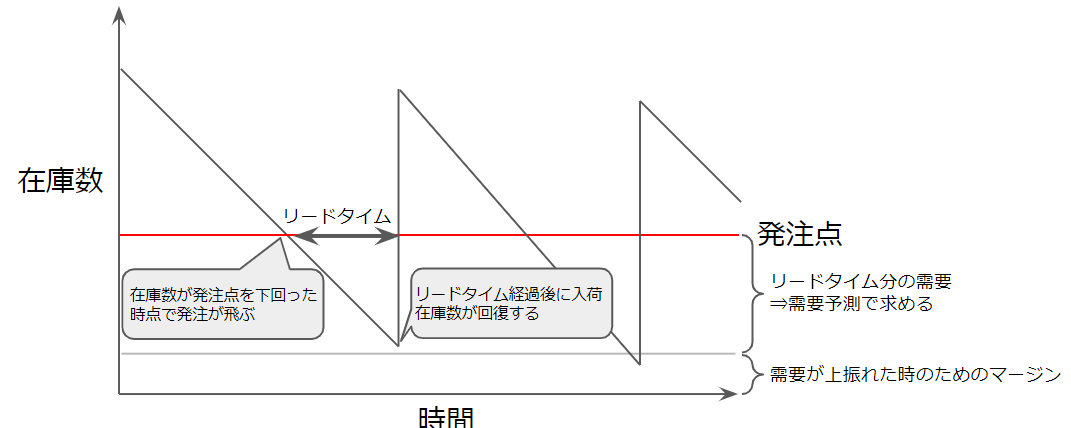
本題に入る前にここで少し、モノタロウでの発注の仕組みと、需要予測との関係について説明します。モノタロウでは50万点近い在庫数(2022年2月時点)を有していますが、これら商品の発注はいわゆる「発注点方式」と呼ばれる仕組みが中心となっています。サプライヤに発注してからモノタロウの倉庫に入荷するまでの期間(=リードタイム)分の需要に、需要のバラツキを加味したマージンを足した値を発注点とし、その発注点を在庫量が下回った時点でサプライヤに発注が飛ぶ仕組みです。発注点を決めるために必要なリードタイム分の需要を求めるために必要なのが「需要予測」ということになります。
機械学習を導入する取り組みの開始
需要予測をより精度の良いものにするために、モノタロウでは需要予測に機械学習を導入することになりました。モノタロウではデータ基盤がしっかりと整備されているので、機械学習モデルの作成に必要なデータはすぐに準備することができます。今回のプロジェクトでも比較的スムーズに機械学習モデルの検討・構築を行うことができました。モデルができたら、次に行うのが性能評価です。以前の需要予測と機械学習を用いた需要予測をシミュレーションやABテストで比較すると、予測精度や欠品率(倉庫に在庫が足りず欠品してしまった割合を示す指標)といったKPIにおいて、機械学習を用いた需要予測の方が良い結果となりました。精度やKPIでよい結果となったことだし、あとは現場導入の全面展開をするだけだ!
・・・と思いきや意外な落とし穴があったのです。
機械学習の現場導入で起きた問題点① - 発注量が増える
シミュレーションでの検討の中で、需要予測を機械学習に切り替えた瞬間に、発注量が跳ね上がることが判明しました。何が起きたかというと、需要予測を機械学習に切り替えた際に「予測値が上がる商品」と「予測値が下がる商品」が混在することになります。「予測値が下がった商品」は発注点が下がるだけなので特に何も起きないのですが、「予測値が上がった商品」に関しては発注点も上昇するので、在庫数が変化していなくても発注が飛びやすくなってしまっていたのです。

一度に大量に発注が飛べば、当然その後の入荷量も増えてしまいます。入荷できるキャパシティには限りがあるので、50万点近くある在庫品に対して大量発注・大量入荷が起きれば、物流現場に対して与える影響が非常に大きくなってしまいます。また、この問題は需要予測を機械学習に切り替えた後にも発生します。機械学習は一度モデルを作ったらそれで終わり、というわけではなく定期的にモデルを更新していく必要があるからです。モデルを更新するたびに発注量と入荷量が増えて物流現場に負担をかけているのでは、たとえ予測精度やKPIが改善しようと意味がありません。
問題点① - 発注量が増えることへの解決策
モデルの切り替えの際に少しずつ更新できる仕掛けに
発注量の問題に対処するために、需要予測を機械学習へ切り替える際に50万SKUに対して一度に切り替えるのではなく、少しずつ切り替えができる仕掛けを導入しました。毎月のモデル更新の際にも、少しずつ切り替えることで発注量が更新のたびに跳ね上がることを防ぐことができました。
あえて予測の更新頻度を落とす
また予測の更新頻度を落とすことで発注量を減らす施策も導入しました。前述したように、在庫数が変化していなくても発注点の変化によって発注が飛んでしまうケースがあります。そして発注点の変化は需要予測の切り替え時だけでなく、予測結果が更新されるたびに発生する可能性があります。これを防ぐために予測を行う頻度を落とすコントロールを行いました。発注点が必要以上に変動することがなくなり、発注量を抑えることに成功しました。
予測精度のことだけを考えればより細かい頻度で需要予測を行ったほうが良いですが、あえて精度を許容できる範囲で落とすことで、現場によりフィットする仕組みを作ることができたのです。
機械学習の現場導入で起きた問題点② - 結果の解釈が難しい
モノタロウの発注はほとんどが発注点を起点に自動で発注が飛ぶのですが、一部の商品では需要予測の結果から手動で発注を行う必要があります。需要予測を機械学習に切り替えたもう一つの問題点として、手動発注のように需要予測の結果を見て実務を行う社内ユーザーにとって、理解が難しい仕組みとなってしまいました。
機械学習化する前の比較的シンプルな需要予測では、例えば手動発注の担当者が「発注量が多いな」と感じたときに「なぜ多くなるのか」「その値で発注して大丈夫なのかどうか」がすぐ判断できていました。しかしながら機械学習化した需要予測ではロジックが複雑になり、そのような判断が困難になっていたのです。結果的に、手動発注の担当者は何か分からないことがあるたびに需要予測チームに問い合わせをしなければならなくなり、双方にとって負担が大きくなっていました。

問題点② - 結果の解釈が難しいことへの解決策
この問題を解決するにあたって、当初は需要予測の仕様を詳細に説明した資料を整備・共有することで解決しようとしていました。しかしながら、仕様書の共有では問題の解決には至らず、問い合わせが必要な状況も続くこととなってしまいました。
そこで手動発注の担当者にヒアリングを実施したところ、「需要予測の仕組み」そのものよりも「何かトラブルが起きたときの具体的な調査・対応方法」が知りたいことが判明。仕様書だけでなく、担当者視点でのトラブルシューティングやFAQを整備する方向に舵を切ったことが功を奏し、需要予測システムの結果に疑問を感じた際に担当者だけで調査・判断できる範囲を広げることができました。手動発注の担当者からも「分かりやすくなった」「自分たちだけでも調べやすくなった」との声を頂きました。

まとめ
機械学習をビジネス現場に導入した際に発生した課題と、それぞれの課題に対する対応策について紹介しました。今回紹介した2つのケースで共通して言えるのは、最新の手法や華麗なテクニックを駆使したという訳ではなく、機械学習が使われる現場や使う人の目線に立ちながら当たり前なことを積み重ねて解決していったということです。
もちろん、最新の手法を追求していくことは、より良いシステムを作り他社差別化を図る重要なポイントの一つです。しかし、手法はあくまで手法であって、それ単体のみで現場に活きるケースはそれほど多くはないです。「現場目線に立った当たり前」を積み重ねていくことで、最新の手法を現場で活躍できるシステムへと昇華させることができるのだと考えます。
これからの展望
今回は機械学習に関するテーマでしたが、サプライチェーンにおけるデータ活用には機械学習以外にも数理最適化やシミュレーションが使われており、それらを組み合わせることでより高度なデータ活用を目指しています。一例をあげると、先ほど紹介したように現在のモノタロウでの発注では、在庫数が発注点を下回った時点で自動的に発注が飛ぶ仕組みになっています。今後はこれに数理最適化を組み合わせ、現場リソースを上回らない範囲で欠品率を最小化できる発注パターンを計算することで、現場作業の効率化や、需要予測のロジック変更などのイベントに対して更に頑健性を高めることを狙った発注ロジックの導入を検討しています。
このようにサプライチェーン・物流における課題は多く、データサイエンスによる改善の余地が大いにあります。上記の課題や、取組みに興味、関心がある方はデータサイエンティストとのカジュアル面談へのご応募お待ちしております。